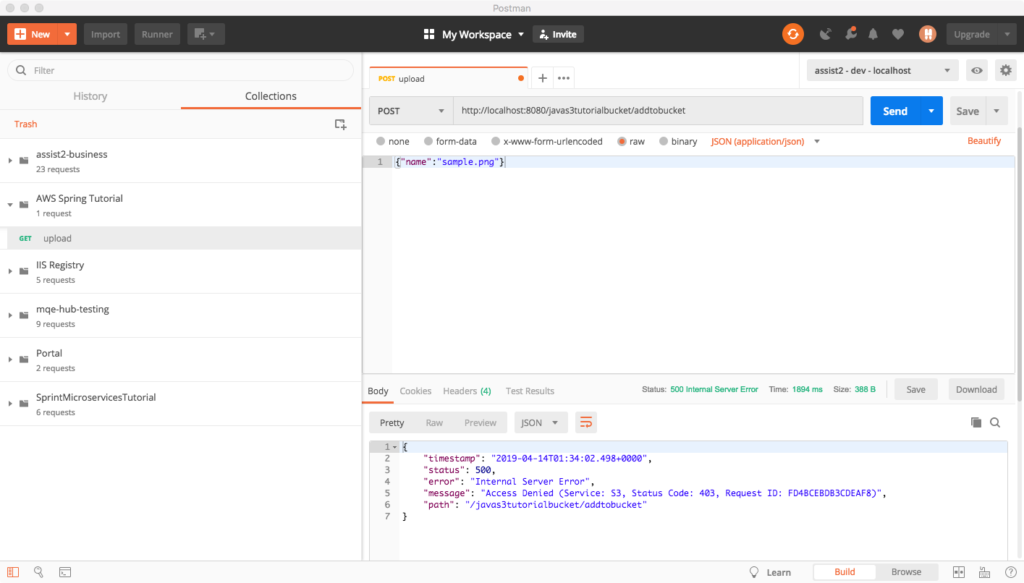
Introduction
AWS SQS Message Queues are a way to exchange messages between applications. Senders, send data objects to a queue and receivers, receive objects from a queue. Amazon’s Simple Queue Service (AWS SQS) is a service offered by AWS that offers scalability and reliability by being distributed across Amazon.
A message queue decouples applications. An message producer only knows about the queue and knows nothing about the queue’s consumers. Likewise, a message consumer only knows about the queue and knows nothing about the queue’s other consumers or producers. Moreover, producers and consumers know nothing about timing, and are asynchronous.
For more on queues and message-passing in general, there are many resources online. Here is a good reference from MIT: Reading 22: Queues and Message-Passing.
Use Case
Suspend disbelief, or more accurately, simply build the system regardless of what you think about the soundness behind the business plan. Famous entrepreneur John Bunyan from Washington State has a plan to get rich and famous by finally proving conclusively that Bigfoot – or Sasquatch for the cultured – exists and uses the extensive system of hiking trails to move around.
Against his accountant’s advice, he liquidated half his fortune to install a series of hidden cameras along Washington State’s hiking trails to take photos every fifteen minutes. As he is a busy man, he does not have time to analyze all the photos personally, and so he want’s image analysis software to analyze the images. If the software registers a Sasquatch, he wants the images to personally go to his email account so he can register the image as a Squatch or not.
Now, with if 10,000 cameras take a picture every 15 minutes, that is 600,000 images per hour. Assume each image takes up to five minutes to process. Hopefully you can see, we have a scalability issue.
There are various ways to deal with this scalability issue, but as this is a tutorial on SQS, we use AWS SQS. And, as I am fond of admonishing in all my tutorials, if the “business case” seems suspect, then suspend disbelief and focus on the AWS code.
Design
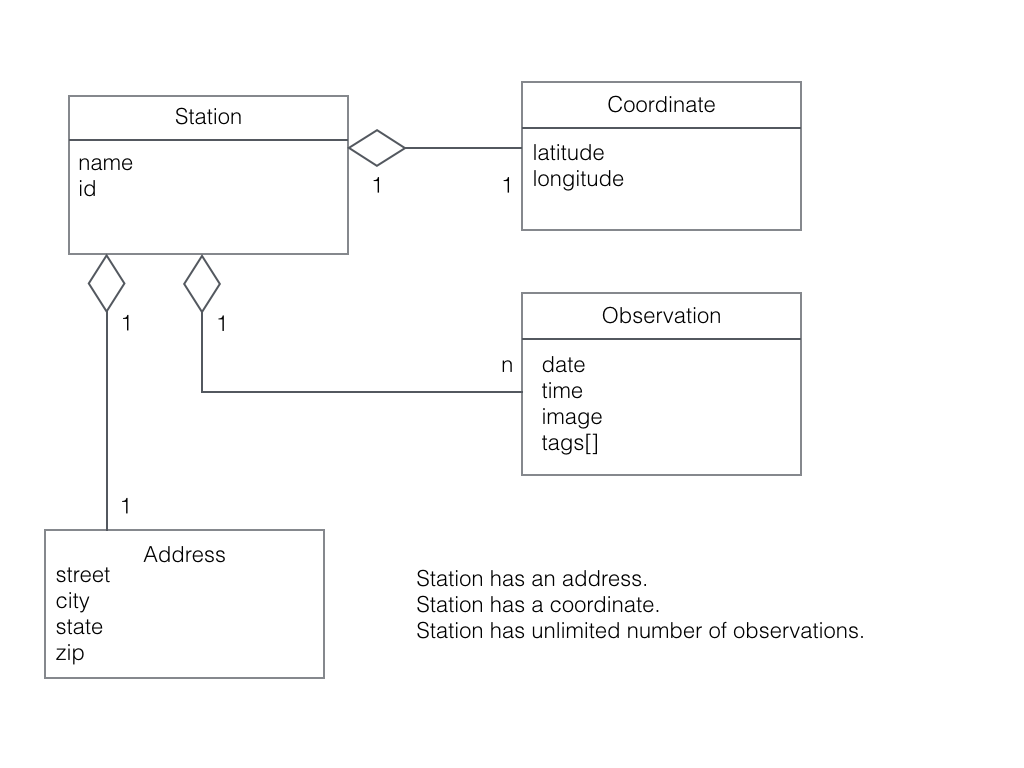
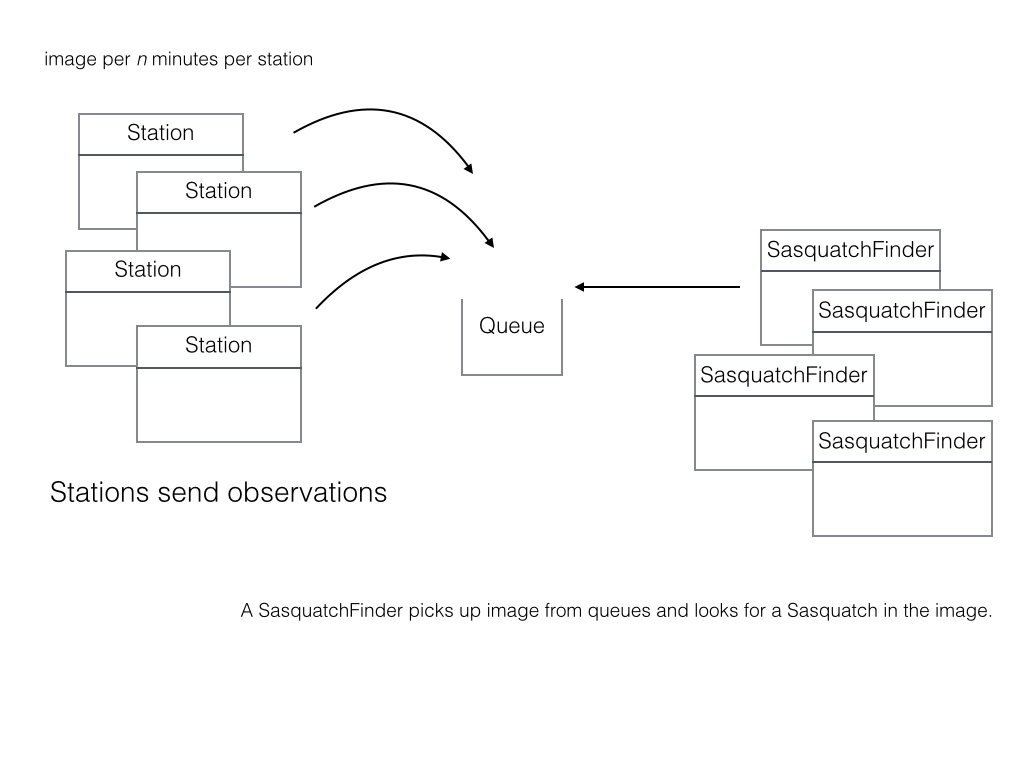
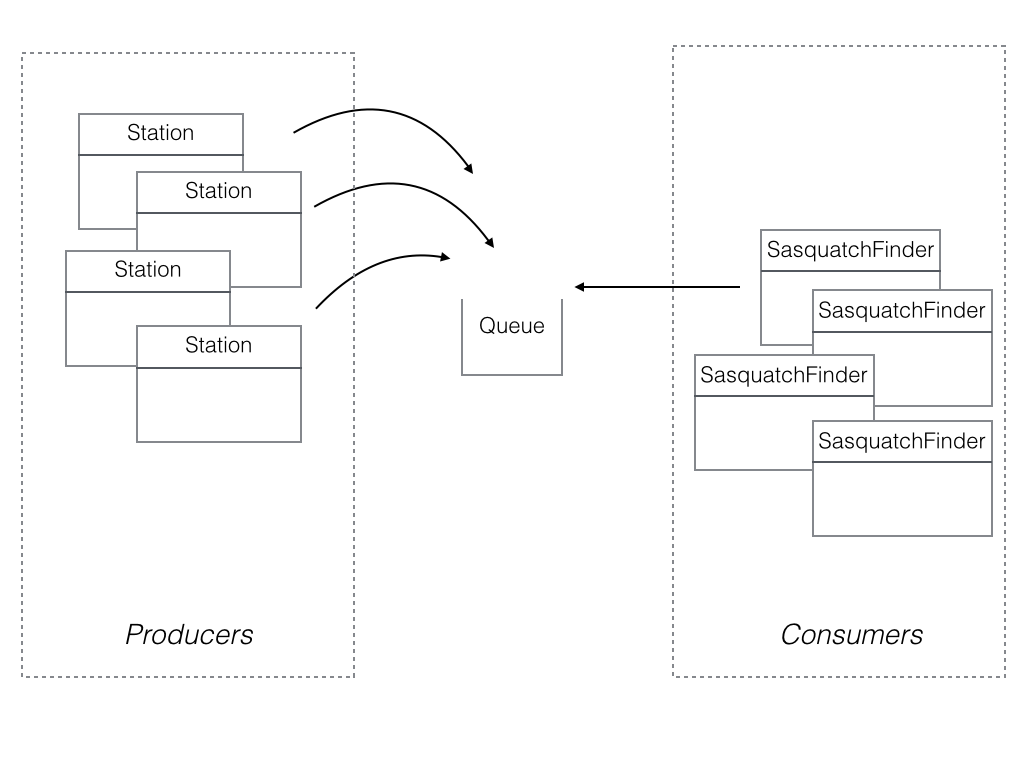
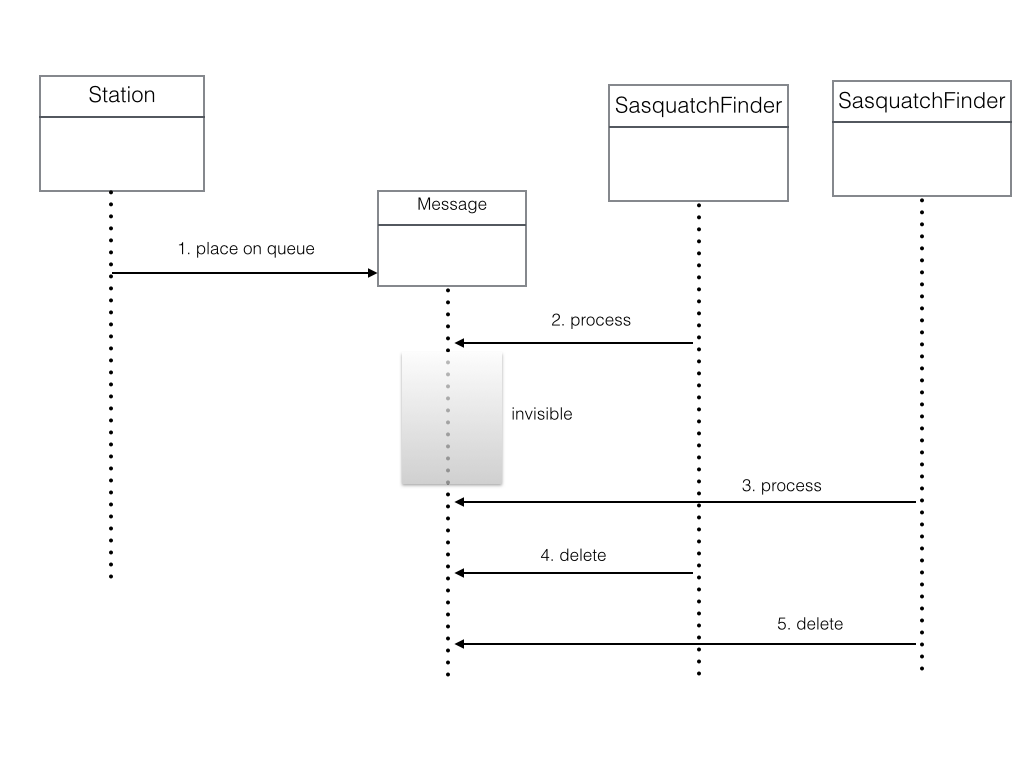
Enough apologizing for the business case, let’s focus on the application’s design. The following diagram illustrates the dilemma.
- Every n minutes a Station sends an observation to an AWS queue.
- There are 1 or more SquatchFinder components who’s job is to pick up an observation from the queue and process the observation.
- Station is the producer while SasquatchFinder is the consumer.
We can formalize our requirements with a simple class diagram. A Station creates an Observation. A SasquatchFinder processes an Observation.
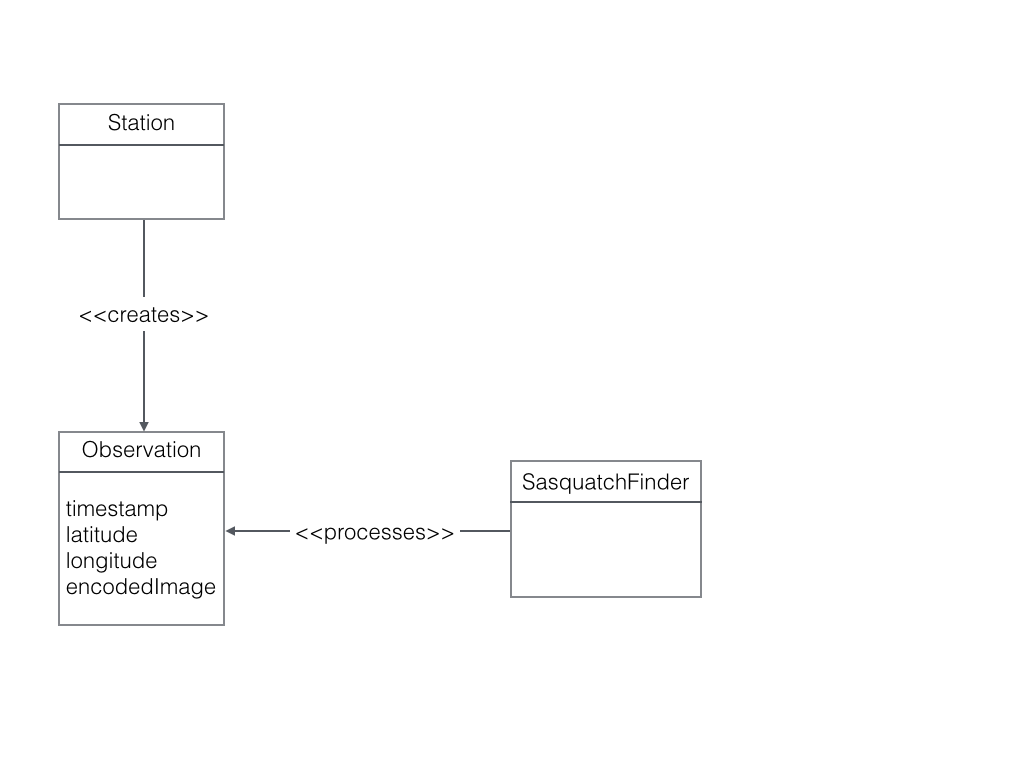
All communication with AWS isfrom external processes is via its REST API. AWS SQS is no different. Moreover, SQS queues only accept textual data. But a common need is for the queue to accept binary data, such as an image. Also, JSON is a textual data transport format.
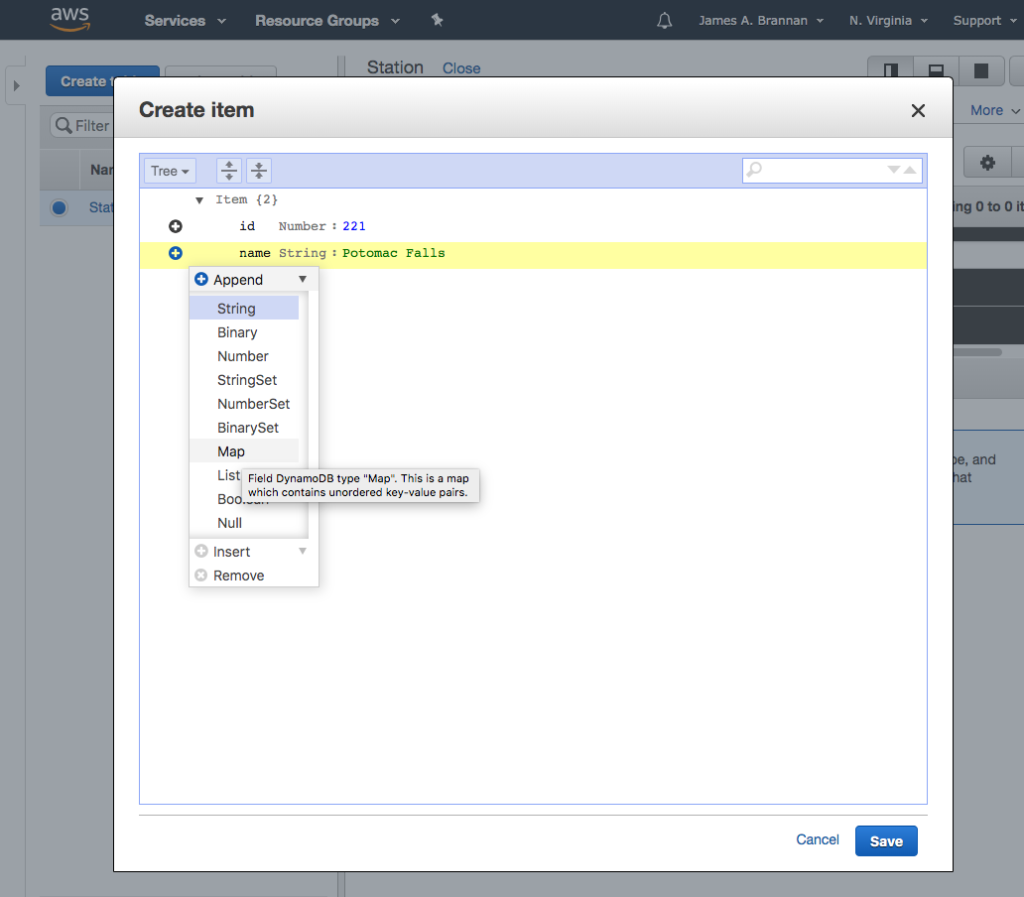
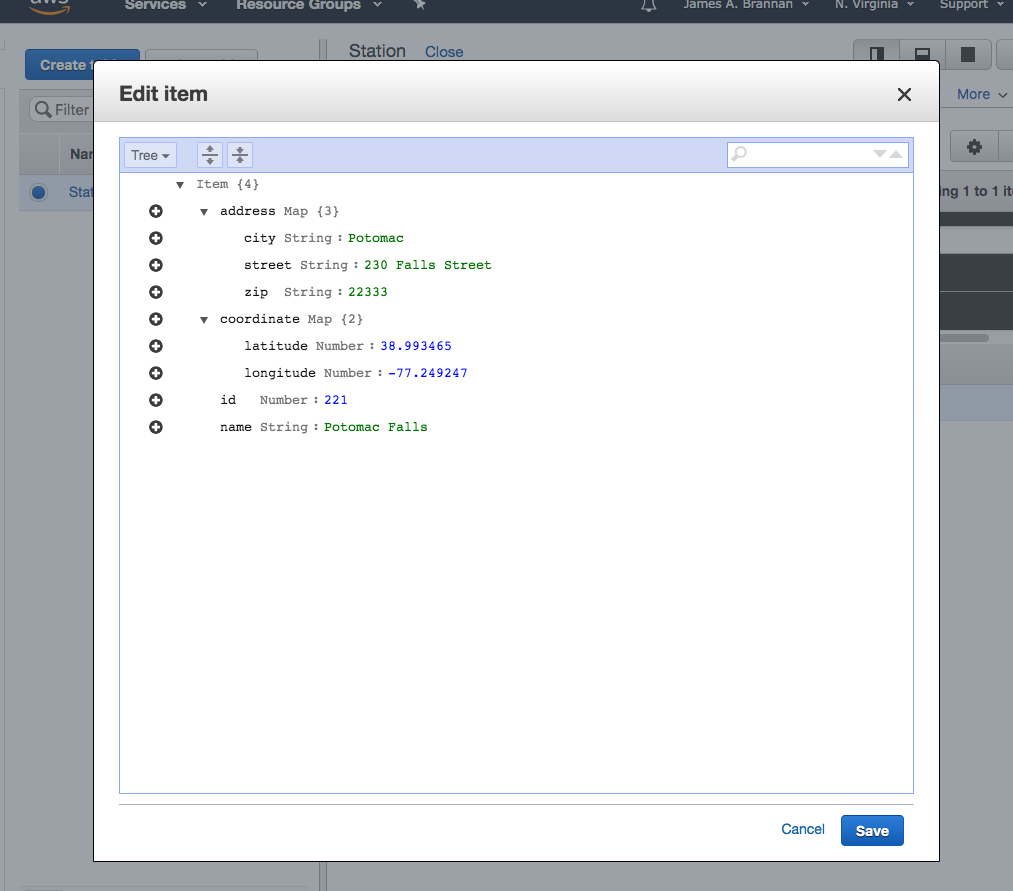
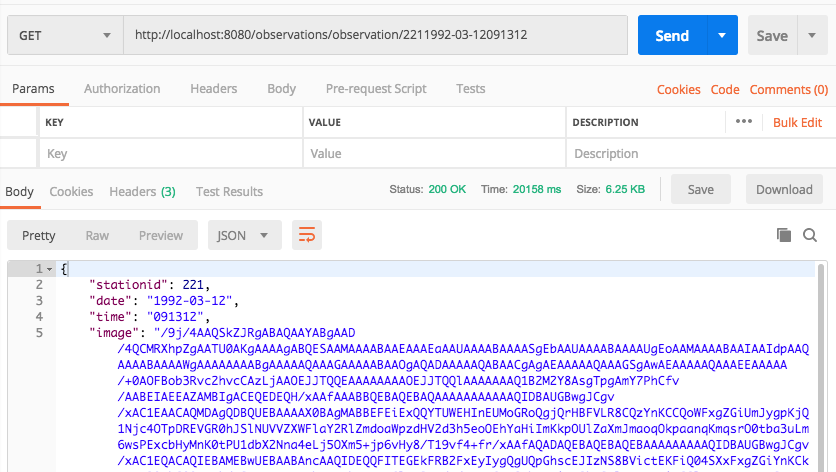
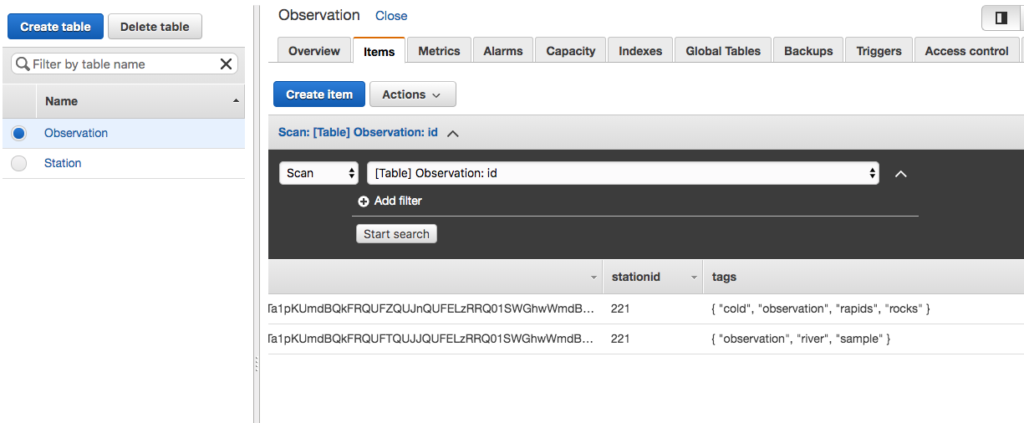
We can translate the Observation into a JSON document. The image is converted to base64 encoding so it can be represented as text. Note the encodedImage in this tutorial is always truncated with <snip>, as the base64 string is quite long.
{
timestamp: “1558493503”,
latitude:”46.879967”,
longitude:”-121.726906”,
encodedImage:"/9j/4AA <snip> 3QEUBGX/9k="
}Base64 Encoding
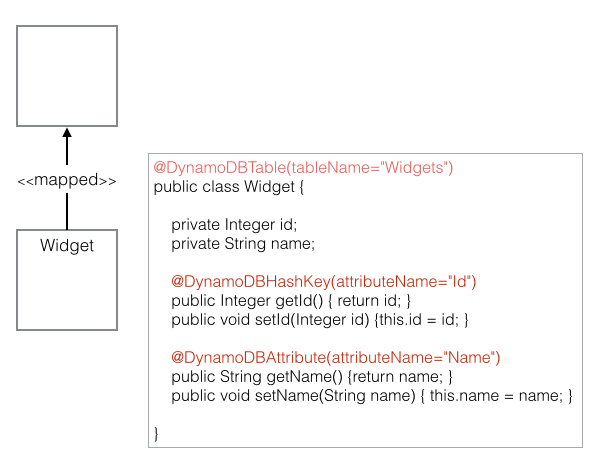
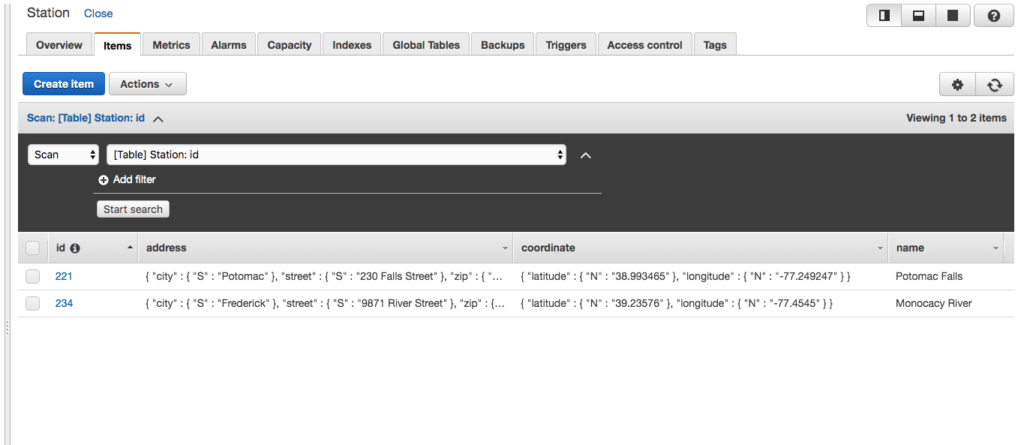
Images are binary. However, all binary can be represented by a String provided it is encoded and decoded correctly. Base64 is an encoding scheme that is converts binary to a string. It’s useful because it allows embedding binary data, such as an image, in a textual file, such as a webpage or JSON document. AWS SQS queues only allow textual data, and so if you wish to store an image on an AWS SQS queue, you must convert it to a string. And the easiest way to accomplish this is by using Base64 format to encode binary data to strings when transporting data and decode strings to binary data when storing the data. For an example of Base64 and DynamoDB, refer to this site’s tutorial: Using the AWS DynamoDB Low-Level Java API – Sprint Boot Rest Application.
Station – Producer
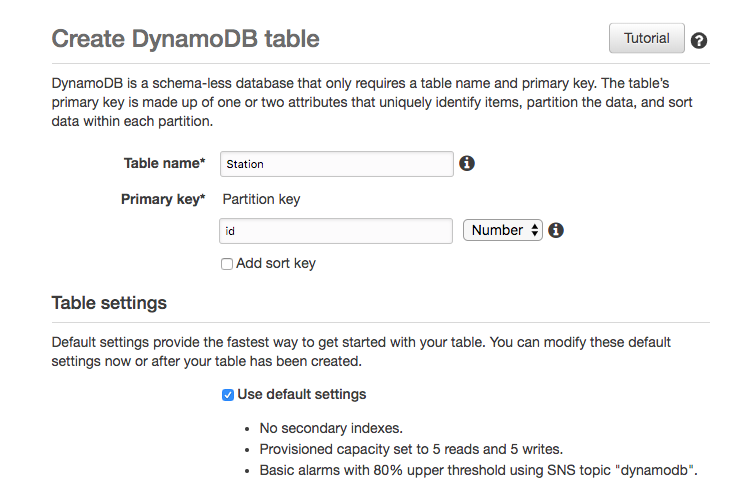
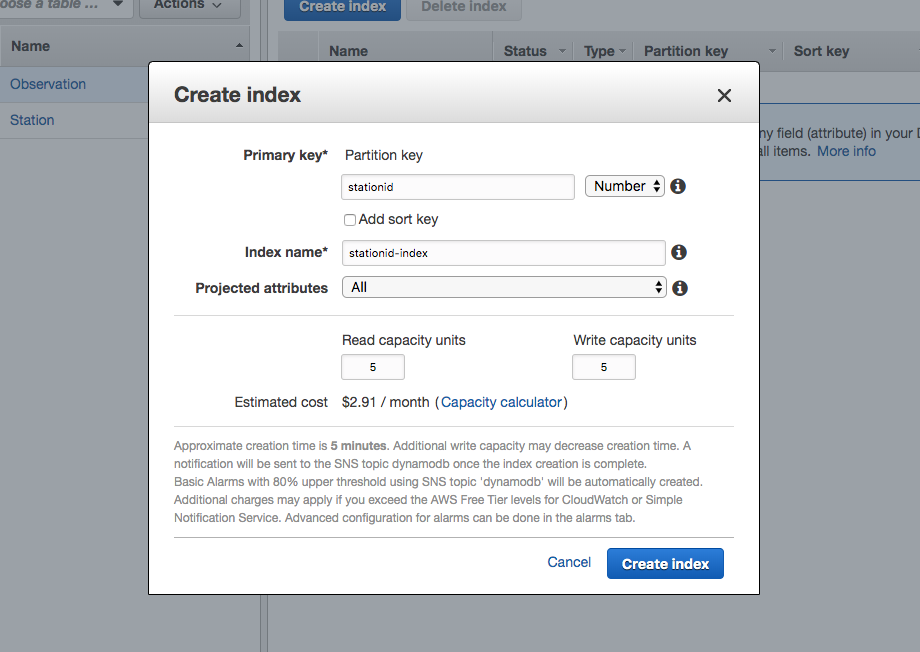
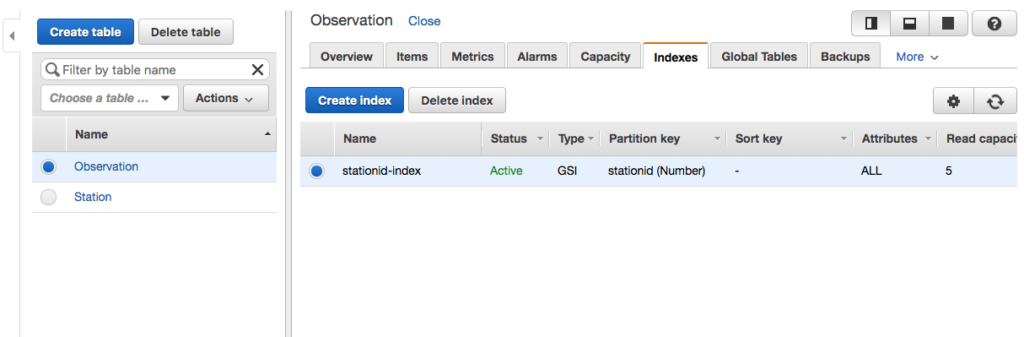
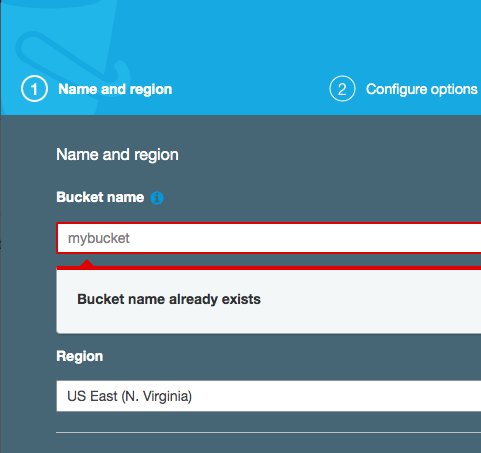
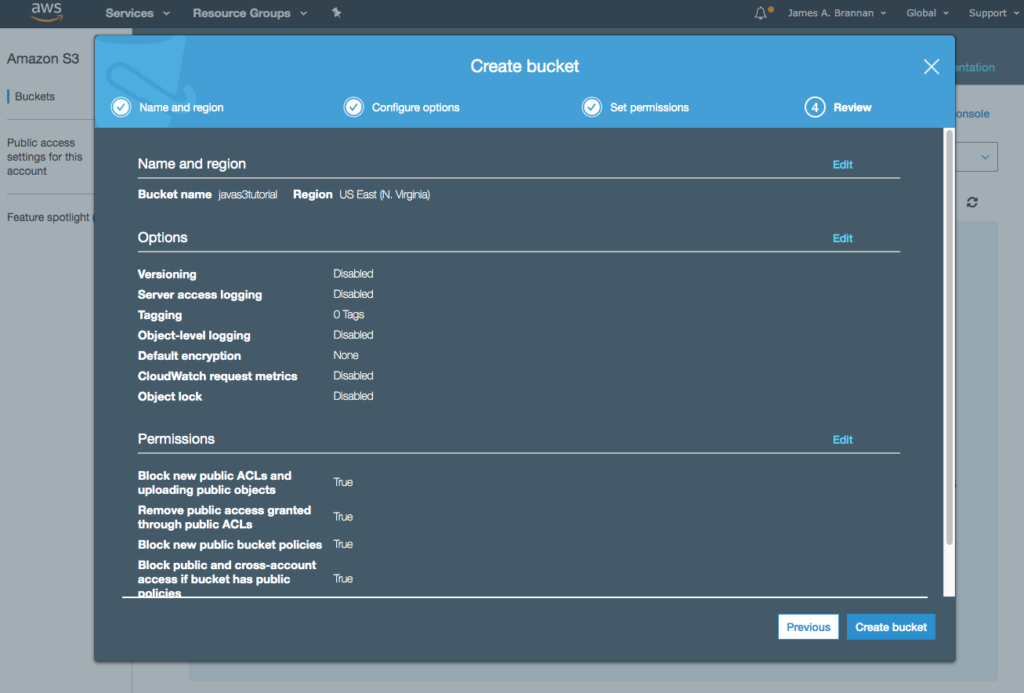
Before coding the application, let’s create a queue. You can create a queue via the Java 2 API SDK; however, here we create the queue manually and then use this queue to send and receive messages.
Create SQSQueue
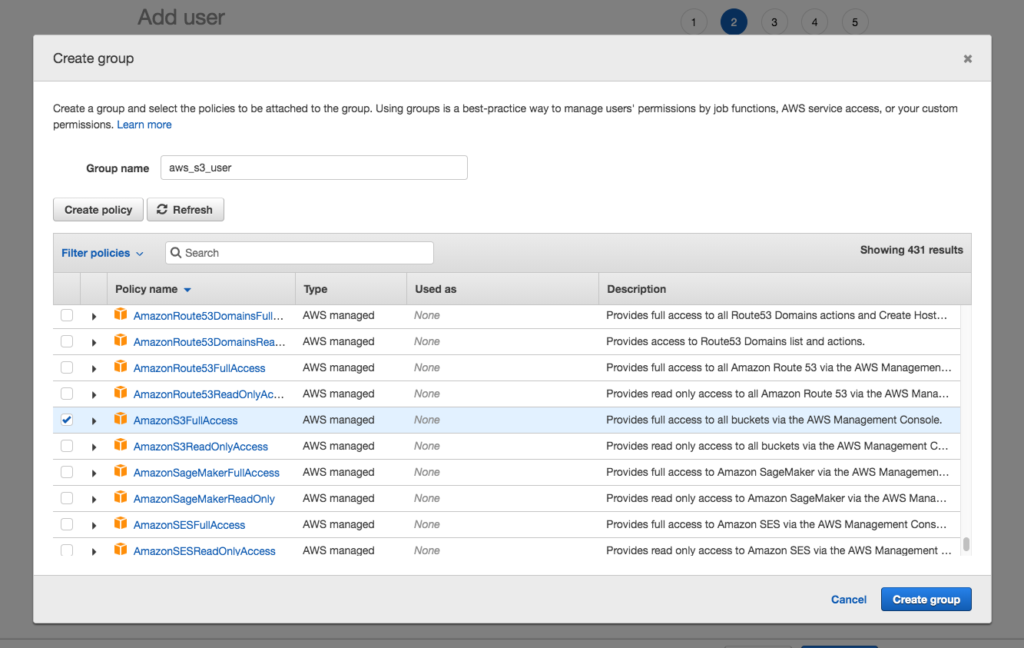
- Navigate to the SQS console and select standard Queue.
- Click the Configure Queue button.

- Name the queue SasquatchImageQueue.
- Accept the defaults for the Queue Attributes.
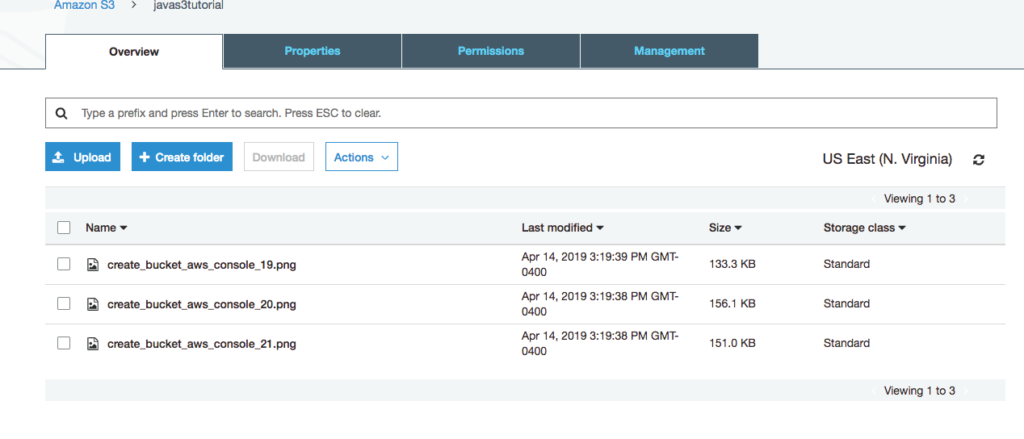
- After creating the queue you should see a screen similar to the following.
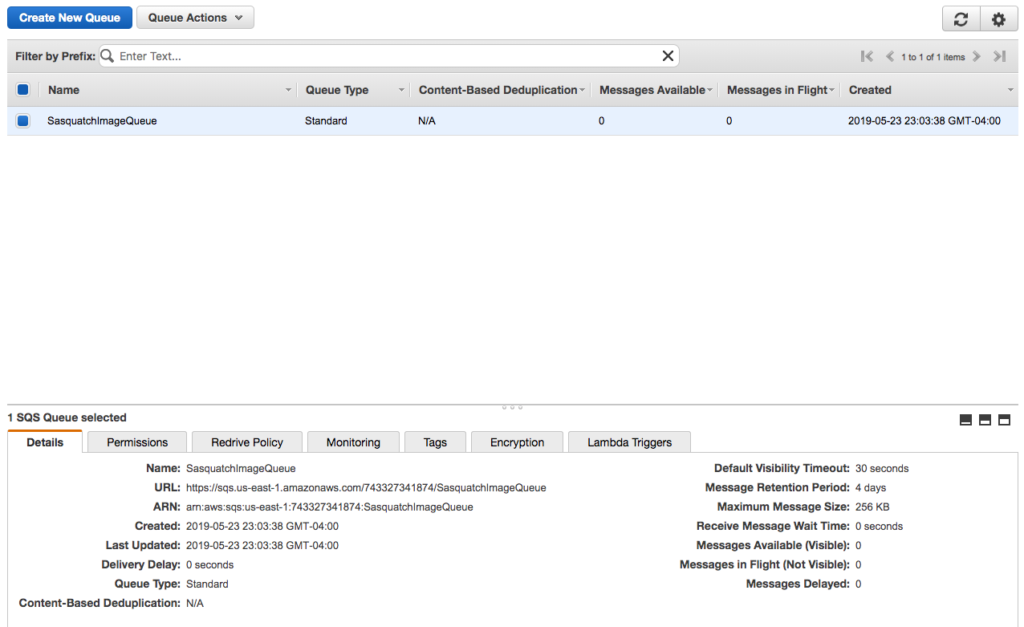
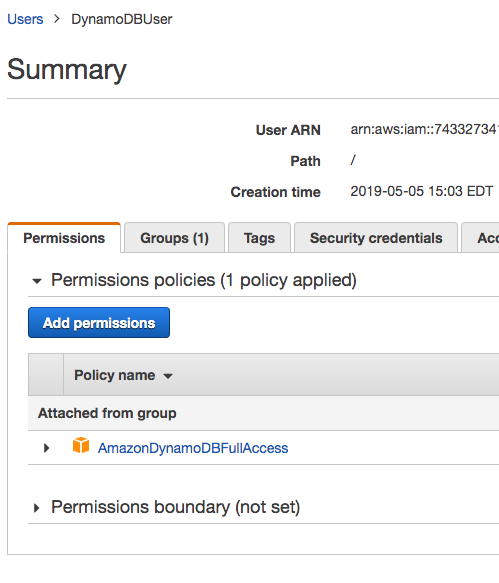
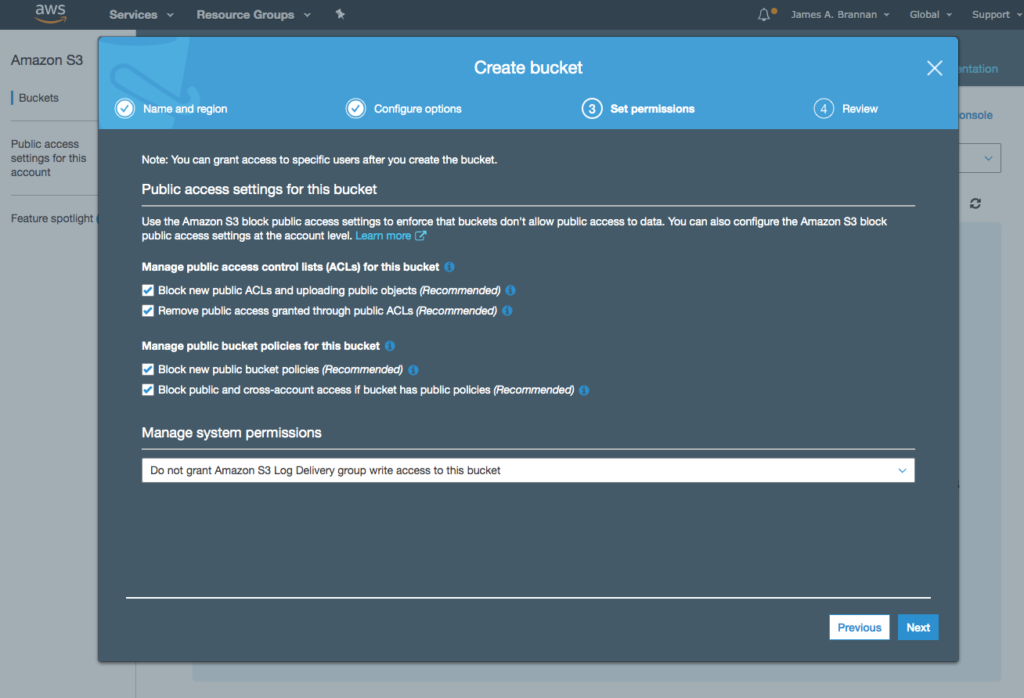
- Click on the Permissions tab and notice that we have not created a permission. We return to the Permissions tab after creating the two necessary users.

There are two types of queues offered by AWS SQS, Standard Queues and First In First Out (FIFO) Queues. Standard queues provide what is called best-effort ordering. Although messages are usually delivered in the order they are received, there are no guarantees. Moreover, messages can also be processed more than once. FIFO queues, in contrast, guarantee first in first out delivery and processing only once.
In this tutorial we primarily use standard queues. However, toward the end of this tutorial we illustrate using a FIFO queue.
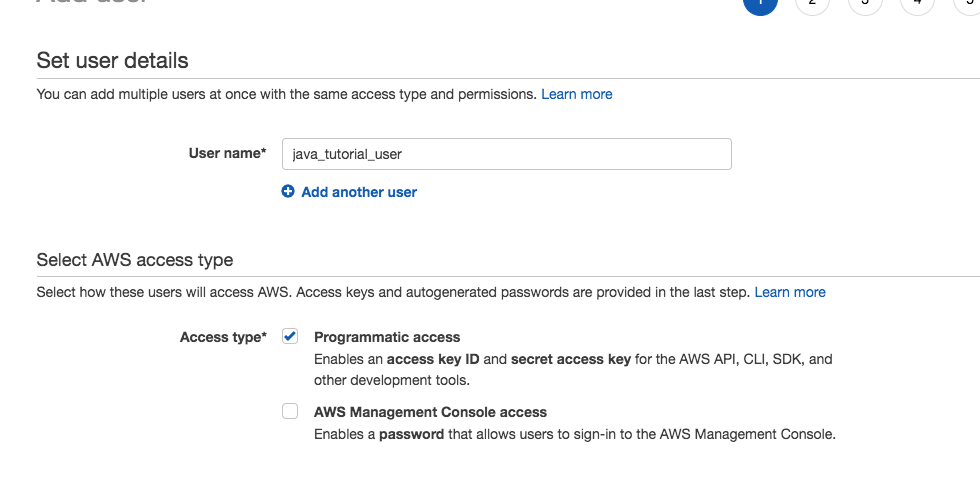
Create SQSQueue Users
We need to create two users, one to interact with the queue for sending messages and another for receiving messages. If you have created IAM users before, note we do not assign the user to any group or assign any policies. Instead, we allow the queue to determine its permissions. Of course, we assign the user programmatic access and download the credentials file.
- Navigate to the IAM console and create a new user called SasquatchProducerUser that has programmatic access.
- Save the user’s credentials locally.
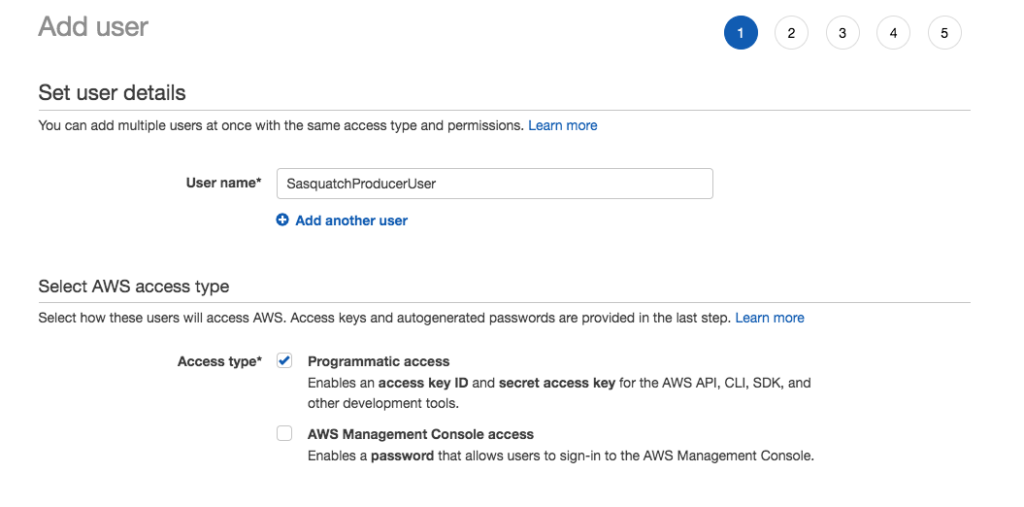
- Create a second user called SasquatchConsumerUser that also has programmatic access.
- Save the user’s credentials locally.
- You should have two users created with programmatic access.
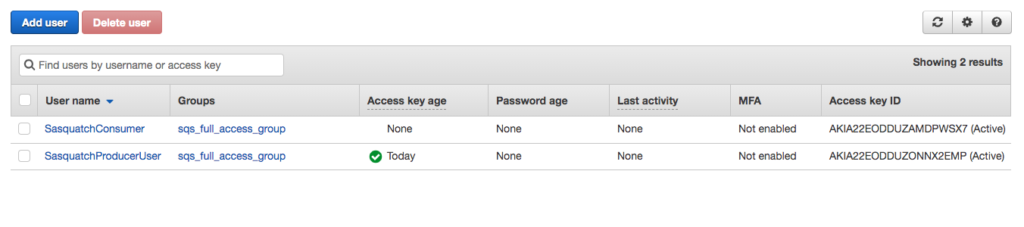
Queue Permissions
Initially only a queue’s creator, or owner, can read or write to a queue. The creator must grant permissions. We do this using a queue policy. We write the policy using the ASW SQS Console, although you write it manually if you wished.
Consumer Permissions
- Navigate to the SasquatchConsumerUser summary screen and copy the Amazon Resource Name (ARN).
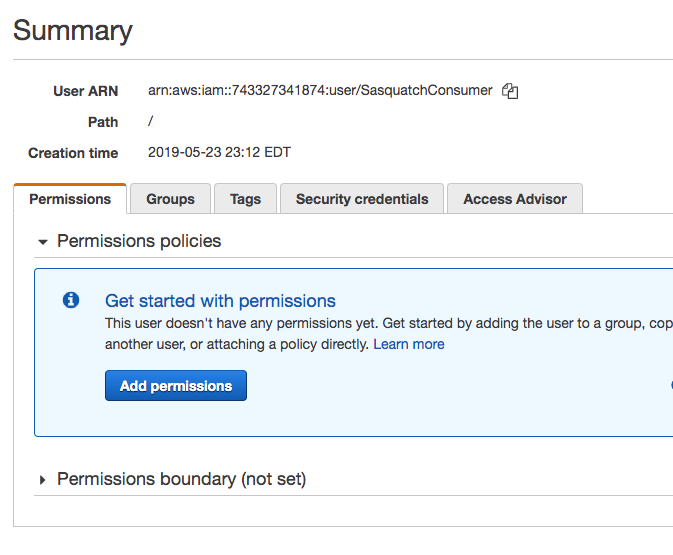
The ARN should appear similar to the following.
arn:aws:iam::743327341874:user/SasquatchConsumerThe Amazon Resource Number, or ARN, uniquely identifies an Amazon resource, in this case, the SasquatchConsumer user.
- Return to the SQS console and select the SasquatchImageQueue and click on the Permissions tab.
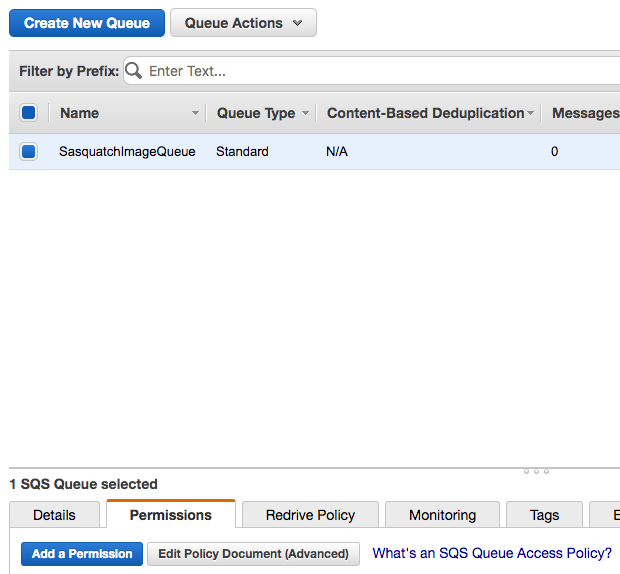
- Click Add a Permission.
- In the resultant popup, paste the ARN in the Principal text box.
- Check the DeleteMessage, GetQueueUrl, and ReceiveMessage Actions.
- Click Save Changes.
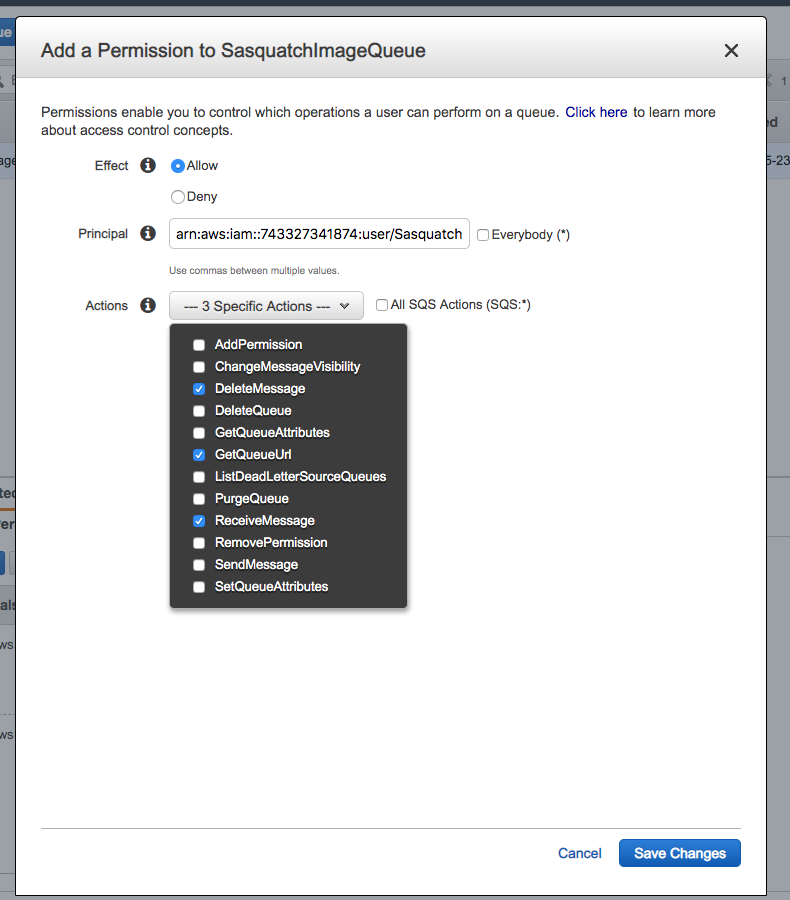
- After creating the SasquatchConsumerUser, navigate to the SasquatchProducerUser and copy the ARN for the producer.
arn:aws:iam::743327341874:user/SasquatchProducerUser- Navigate back to the SQS Queue and add this user to the queue as a permission. Allow the ChangeMessageVisibility, DeleteMessage, GetQueueAttributes, GetQueueUrl, PurgeQueue, and SendMessage Actions.
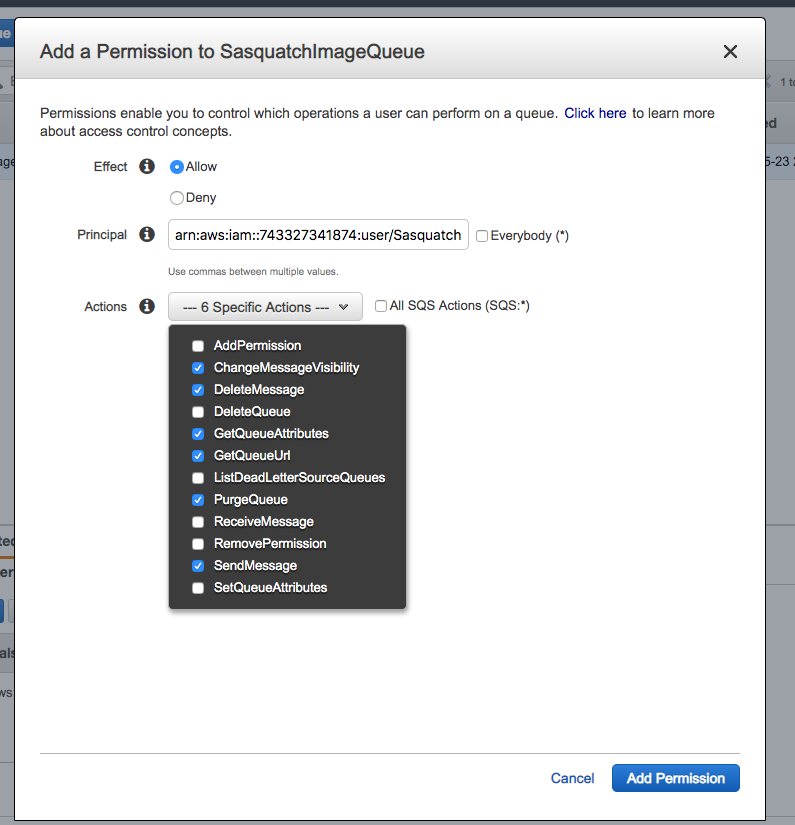
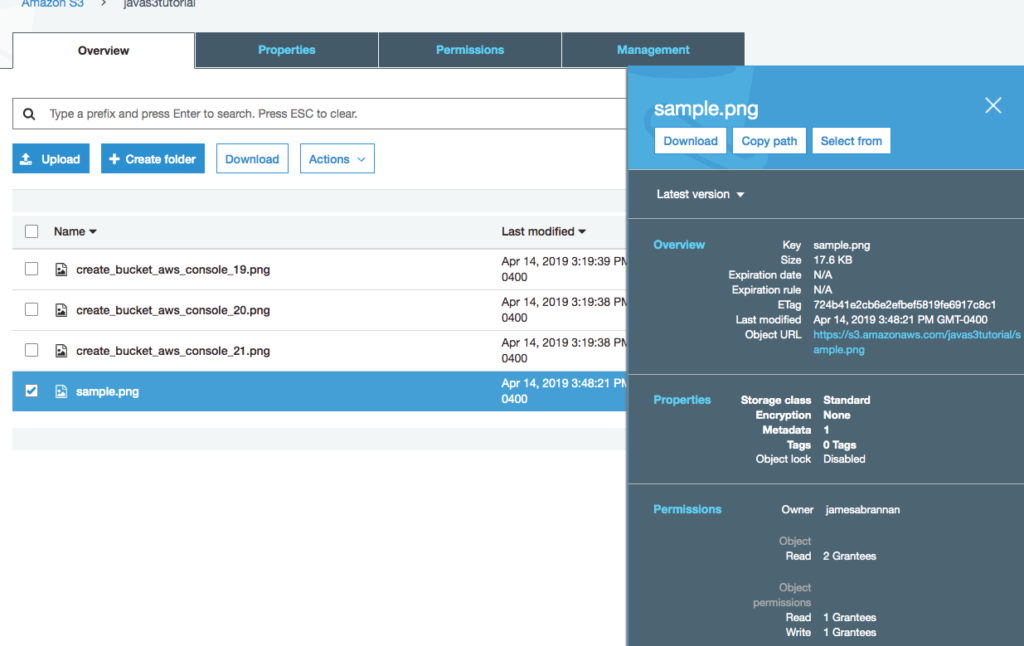
- After adding the permissions for both users the queue should appear similar to the following image.
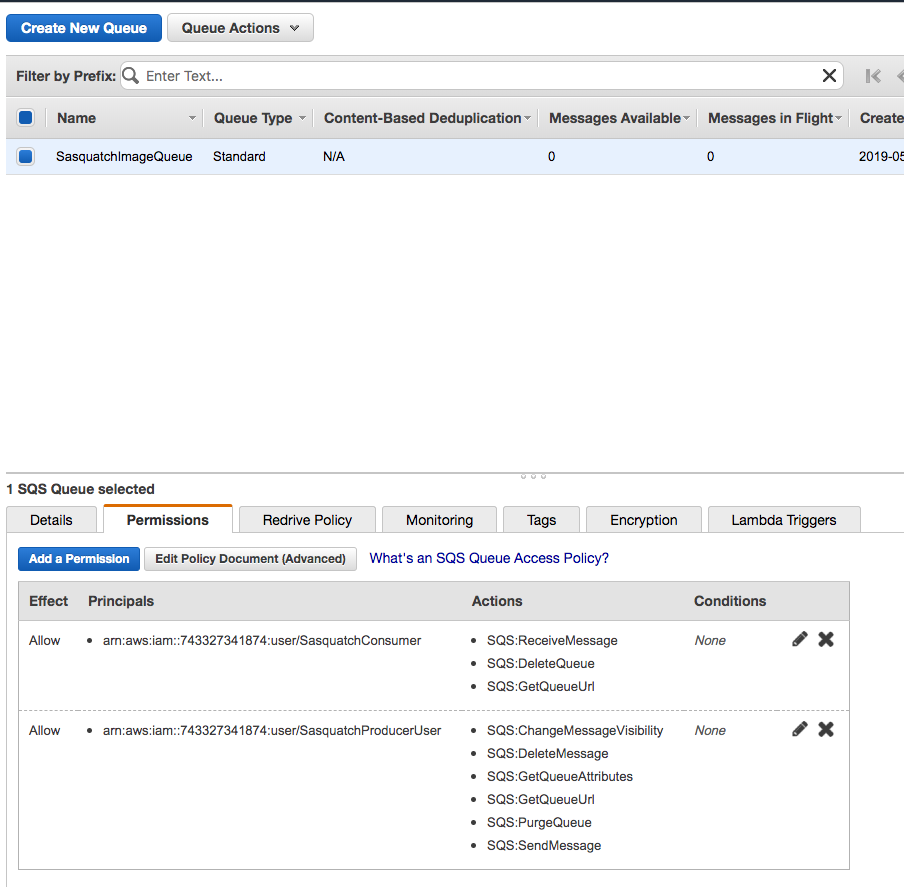
If you are still uncertain as to adding a permission to a queue, here is a tutorial by Amazon: Adding Permissions to an Amazon SQS Queue. You can also add Server-Side Encryption, as this tutorial illustrates: Creating an Amazon SQS Queue with Server-Side Encryption (SSE).
Although we do not discuss Policy documents, the following illustrates that a JSON document underlies the settings we set using the console. It is, however, important you understand policy documents, as they are at the heart of AWS security. For more information on AWS SQS Policies refer to this documentation: Using Identity-Based (IAM) Policies for Amazon SQS.
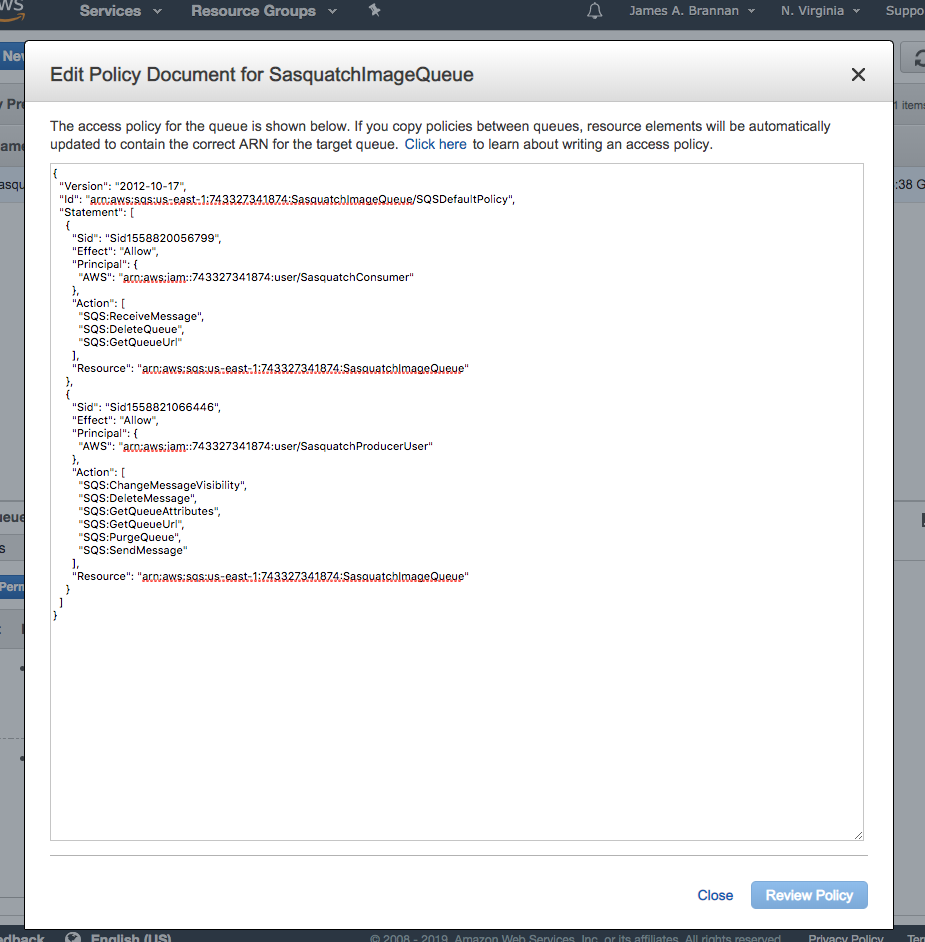
One thing to note is that here we assigned permissions to the queue using AWS SQS rather than the consumer or producer user we created. We could have just as easily used an IAM Policy, as the documentation in the link in the preceding paragraph discusses.
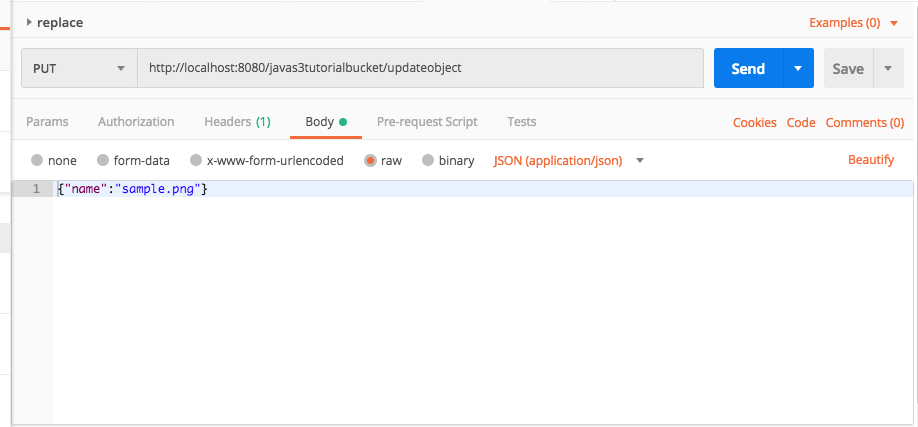
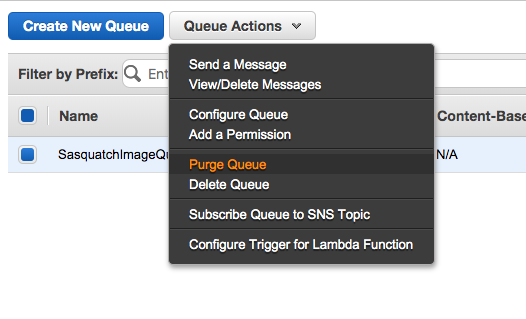
Sending Message Via Console
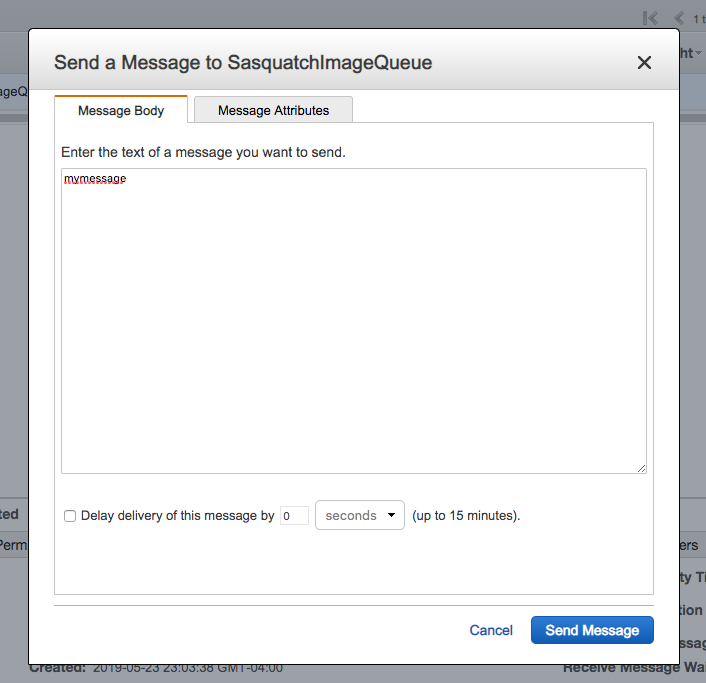
Although there is probably rarely a business reason, for testing purposes you can manually add a message to a queue. Although we will not use the message, let’s explore sending a message using the AWS SQS Console.
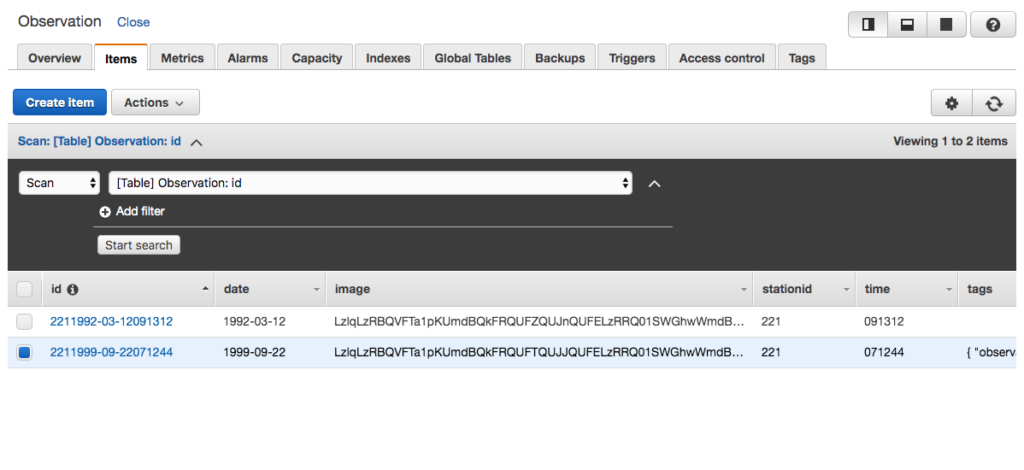
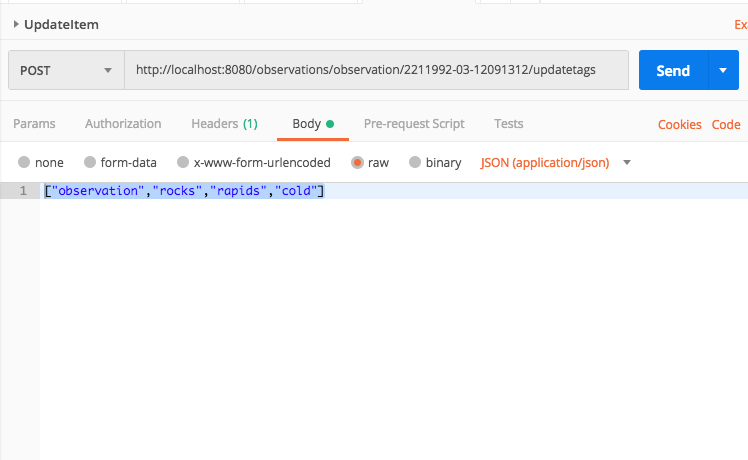
- Refer to the observations.json document and copy one of the observations. Of course, in the code listing below the image is truncated.
{
"stationid": 221,
"date": "1992-03-12",
"time": "091312",
"image": "/9j/4AA <snip> 0Wxkf/9k="
}- Select the queue and from Queue Actions select Send a Message.
- Copy a single message from observations.json and add the entry to the Message Body.
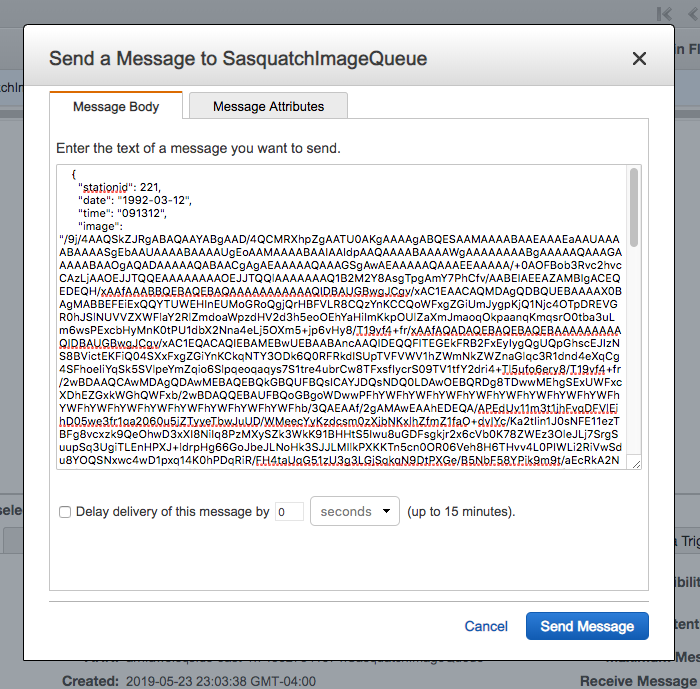
- Click Send Message and within a minute the Messages Available column should show one message on the queue.
- Purge the queue by selecting Purge Queue from Queue Actions.
Java Project – Producer
As discussed, a producer, well, produces messages. If we fully implemented the design above we would have many Stations and many . However, to keep the tutorial simple we limit ourselves to one Station in one project.
Project Setup
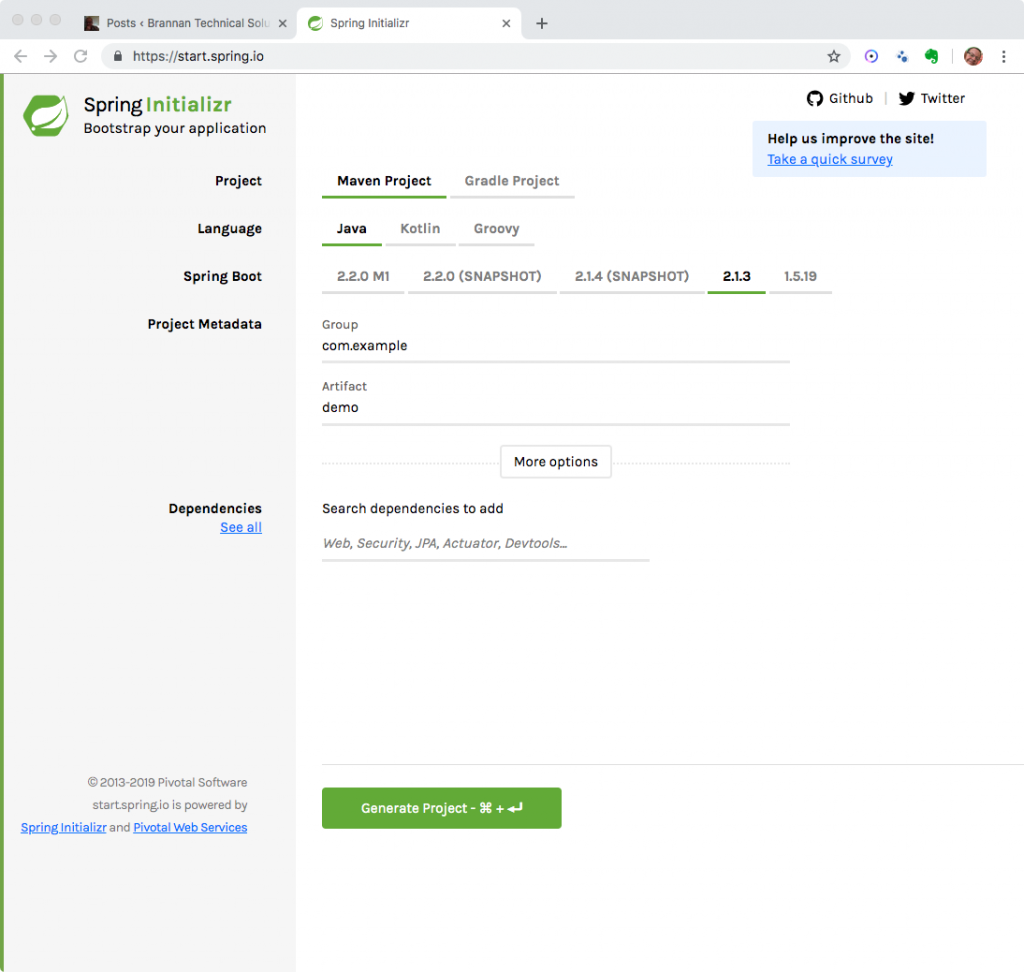
Although I developed the tutorial using Eclipse, you can use your own IDE or even the command-line. However, you really should use Maven or Gradle. Here we use Maven. It is assumed you are familiar with using Maven to build Java projects.
POM
- Create a new project named SQSTutorialProducer.
- Create or overwrite the POM file with the following POM.
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tutorial.aws</groupId>
<artifactId>SQSTutorialProducer</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>bom</artifactId>
<version>2.5.25</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<artifactId>auth</artifactId>
<groupId>software.amazon.awssdk</groupId>
</dependency>
<dependency>
<artifactId>aws-core</artifactId>
<groupId>software.amazon.awssdk</groupId>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>auth</artifactId>
</dependency>
<dependency>
<artifactId>sqs</artifactId>
<groupId>software.amazon.awssdk</groupId>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.6.4</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration> <outputDirectory>${project.build.directory}/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>com.aws.tutorial.sqs.main.Station</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>In the POM we use the AWS BOM so we can avoid specifying AWS library versions. We add dependencies for the required AWS libraries. We also specify that maven is to build an executable jar with the required dependencies packaged in the jar.
Notice the following.
<properties>
<java.version>1.8</java.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>If we do not specify Java 1.8 or higher, the compilation will fail, as the AWS builders are static interface methods that do not work with older Java versions. Although on your machine, the code might compile, you could have issues if you have multiple Java SDKs on your computer. By explicitly setting the version, source, and target we avoid any potential issues with compilation.
Station
Let’s create a simple executable Java class named Station. This will simulate a bona-fide message producer.
- First create an com.aws.tutorial.sqs.main package.
- Create a class named Station with a main method in the created package.
- Have the main method printout a message that the class executed.
package com.aws.tutorial.sqs.main;
public class Station {
public static void main(String[] args) {
System.out.println("Station running....");
}
}Executable Jar
- Compile and package the project. If running from the command-line you would type the following.
$ mvn clean compile package- After building, execute the program from the command-line. The printout should appear.
$ java -jar SQSTutorialProducer-0.0.1-SNAPSHOT.jar
Station running....
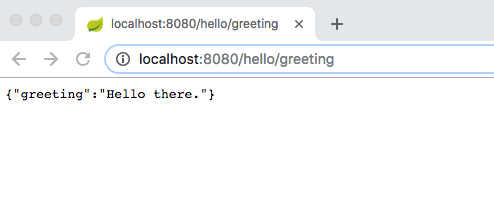
Now that we have created the consumer’s basic structure, we can modify it to send an SQS message.
Sending A Message
In this example we send a message to the queue using the SDK. The data payload is a string of JSON data. You use hardcoded data to send to the queue. Obviously in a real-world application the data would come from a different source. To simulate sending messages from a bona-fide producer, a delay is introduced between sending each message.
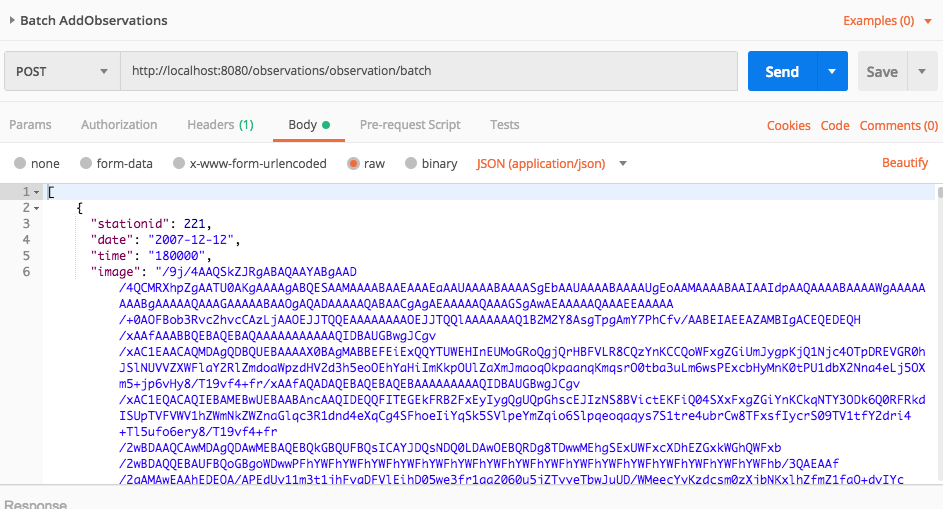
- Before modifying the program, create a new class named TestData in the com.aws.tutorial.sqs.main package.
- Copy three observations from the observations.json file.
- Or, if you do not wish escaping the strings yourself, use the TestData.java from this tutorial’s Git project. Note: if you use Eclipse, it will escape the strings for you when you paste the string immediately after the opening quotation. The image’s base64 code is shortened so they can be easily displayed.
package com.aws.tutorial.sqs.main;
public class TestData {
public static String observationOne = " {\n" +
" \"stationid\": 221,\n" +
" \"date\": \"2019-03-12\",\n" +
" \"time\": \"091312\",\n" +
" \"image\": \"/9j/4A <snip> \"\n" +
" }";
public static String observationTwo = " {\n" +
" \"stationid\": 222,\n" +
" \"date\": \"2016-02-09\",\n" +
" \"time\": \"091312\",\n" +
" \"image\": \"/9j/4A <snip> \"\n" +
" }";
public static String observationThree = " {\n" +
" \"stationid\": 223,\n" +
" \"date\": \"2017-12-22\",\n" +
" \"time\": \"091312\",\n" +
" \"image\": \"/9j/4A <snip> \"\n" +
" }";
}- Modify Station to have a constructor that takes three strings, the key, secret key, and the queue’s URL.
- Create two member variables, one of type SqsClient and the other String.
- In the Station constructor initialize the SqsClient.
- Create a method named sendMessage that sends the message to the queue.
- Finally, modify main to send all three messages in TestData.java and pause between sending each message.
package com.aws.tutorial.sqs.main;
import javax.annotation.PreDestroy;
import software.amazon.awssdk.auth.credentials.AwsBasicCredentials;
import software.amazon.awssdk.auth.credentials.StaticCredentialsProvider;
import software.amazon.awssdk.regions.Region;
import software.amazon.awssdk.services.sqs.SqsClient;
import software.amazon.awssdk.services.sqs.model.SendMessageRequest;
import software.amazon.awssdk.services.sqs.model.SendMessageResponse;
public class Station {
SqsClient sqsClient;
String queueUrl;
public Station(String key, String secretKey, String queueUrl) {
AwsBasicCredentials awsCreds = AwsBasicCredentials.create(key, secretKey);
this.sqsClient = SqsClient.builder()
.credentialsProvider(StaticCredentialsProvider
.create(awsCreds)).region(Region.US_EAST_1).build();
this.queueUrl = queueUrl;
}
public String sendMessage(String message) {
SendMessageRequest request = SendMessageRequest.builder()
.queueUrl(this.queueUrl).messageBody(message)
.delaySeconds(5).build();
SendMessageResponse response = this.sqsClient.sendMessage(request);
return response.messageId();
}
@PreDestroy
public void preDestroy() {
this.sqsClient.close();
}
public static void main(String[] args) {
System.out.println("Station running....");
Station station = new Station("AKIA22EODDUZONNX2EMP",
"LUXJ5WQjW0p4bk1gC5oGBUi41rxA7oSvWWA/8SqH",
"https://sqs.us-east-1.amazonaws.com/743327341874/SasquatchImageQueue");
String id = station.sendMessage(TestData.observationOne);
System.out.println("sent message: " + id);
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
id = station.sendMessage(TestData.observationTwo);
System.out.println("sent message: " + id);
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
id = station.sendMessage(TestData.observationThree);
System.out.println("sent message: " + id);
}
}- Compile and run the application and you should see the following output.
Station running....
sent message: b861220e-a37a-424d-880c-5dd67a052967
sent message: 5185e68b-a16f-4300-8ee5-7ef5cca0eb53
sent message: 161f7444-ae7b-4890-b022-0447933054c3
- Navigate to the queue in the AWS Console and you should see three messages in the Messages Available column.

The consumer has only one SqsClient instance that is initialized in the Station constructor and closed in a method annotated with the @PreDestroy annotation. This annotation is used to mark a method that should be called when a class is about to be destroyed for garbage collection.
Credentials
The client requires credentials to operate. This is the user account that the application uses to authenticate itself to the AWS SDK. Here we hardcode the credentials for simplicity. For more information on AWS Java 2 SDK and credentials, refer to SDK Documentation.
SqsClient
The SqsClient is an interface that extends SdkClient, and is the client for accessing AWS SQS service. You use the SqsClientBuilder to build the client. You build the client by passing the credentials and the region.
this.sqsClient = SqsClient.builder()
.credentialsProvider(StaticCredentialsProvider
.create(awsCreds)).region(Region.US_EAST_1).build()All requests to SQS must go through the client. Different types of requests are named accordingly. For instance requesting to send a message requires a SendMessageRequest, requesting to delete a message requires a DeleteMessageRequest. If you have worked with the other services offered by the Java 2 SDK such as DynamoDb or S3, then this pattern should be familiar.
SendMessageRequest
The SendMessageRequest wraps requests to send messages to the client. You build the request using a SendMessageRequestBuilder. Above we are setting the queue’s URL, the message’s body, and how long to delay before sending the message. We obtained the queue’s URL from the AWS SDK Console.
SendMessageRequest request = SendMessageRequest.builder()
.queueUrl(this.queueUrl).messageBody(message)
.delaySeconds(5).build();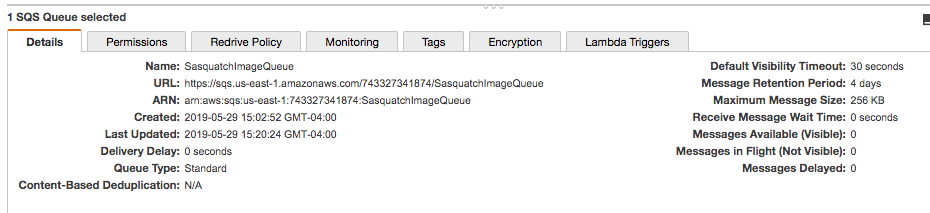
SendMessageResponse
The client sends the request and receives a response. The SendMessageResponse wraps the response. The method then returns the messageId and main prints the value to the console.
SendMessageResponse response = this.sqsClient.sendMessage(request);
return response.messageId();Now that we have created three messages and sent them to SQS, we can write a consumer to consume the messages. Now let’s create a Java project named SQSTutorialConsumer.
Java Project – Consumer
Consumers, well, consume messages. Let’s create a consumer for the messages on the queue. As with the producer, we greatly simplify the consumer by creating an executable class that runs from the command-line.
Project Setup
Let’s create a Java Maven project for the Consumer.
POM
- Create a Java project named SQSTutorialConsumer as a Maven project.
- Create a POM file with the following.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tutorial.aws</groupId>
<artifactId>SQSTutorialConsumer</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>bom</artifactId>
<version>2.5.25</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<artifactId>auth</artifactId>
<groupId>software.amazon.awssdk</groupId>
</dependency>
<dependency>
<artifactId>aws-core</artifactId>
<groupId>software.amazon.awssdk</groupId>
</dependency>
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>auth</artifactId>
</dependency>
<dependency>
<artifactId>sqs</artifactId>
<groupId>software.amazon.awssdk</groupId>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.6.4</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration> <outputDirectory>${project.build.directory}/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>com.aws.tutorial.sqs.main.SasquatchFinder</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>
SasquatchFinder
- First create a com.aws.tutorial.sqs.main package.
- Next create a class named SasquatchFinder in the package.
- Create a main method in the class and have it printout that it ran.
package com.aws.tutorial.sqs.main;
public class SasquatchFinder {
public static void main(String[] args) {
System.out.println("SasquatchFinder running....");
}
}- Build the project.
$ mvn clean compile package- After building the project, execute the program from the command-line.
$ java -jar SQSTutorialConsumer-0.0.1-SNAPSHOT.jar
SasquatchFinder running....Now that we have the project’s basic outline, we can add code to receive messages.
Receive Message
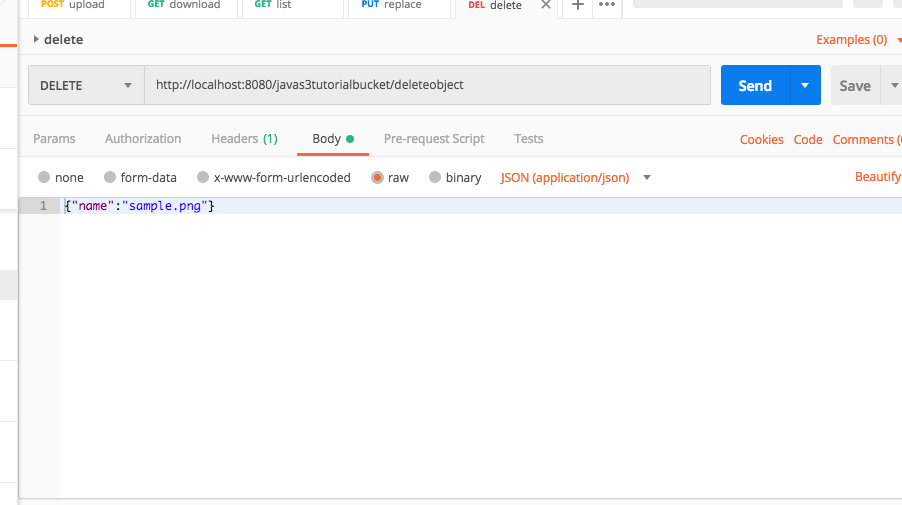
- As with the Station in the SQSTutorialProducer project, create member variables.
- Create a main method that initializes the SqsClient. Be certain to use the consumer’s credentials and not the producer’s.
- Create a new method named processMessage and have it use a ReceiveMessageRequest to receive a message.
- Create a new method named deleteMessage and have it use a DeleteMessageRequest to delete a message.
- Modify processMessage to call deleteMessage after a delay.
- Modify main to loop continuously processing messages.
package com.aws.tutorial.sqs.main;
import java.util.List;
import software.amazon.awssdk.auth.credentials.AwsBasicCredentials;
import software.amazon.awssdk.auth.credentials.StaticCredentialsProvider;
import software.amazon.awssdk.regions.Region;
import software.amazon.awssdk.services.sqs.SqsClient;
import software.amazon.awssdk.services.sqs.model.DeleteMessageRequest;
import software.amazon.awssdk.services.sqs.model.Message;
import software.amazon.awssdk.services.sqs.model.ReceiveMessageRequest;
public class SasquatchFinder {
private SqsClient sqsClient;
private String queueUrl;
public static int finderId = 1;
public SasquatchFinder(String key, String secretKey, String queueUrl) {
AwsBasicCredentials awsCreds = AwsBasicCredentials.create(key, secretKey);
this.sqsClient = SqsClient.builder().credentialsProvider(StaticCredentialsProvider.create(awsCreds))
.region(Region.US_EAST_1).build();
this.queueUrl = queueUrl;
}
public void processMessage() {
ReceiveMessageRequest receiveMessageRequest = ReceiveMessageRequest.builder().queueUrl(this.queueUrl)
.maxNumberOfMessages(1).build();
List<Message> messages = this.sqsClient.receiveMessage(receiveMessageRequest).messages();
if(messages == null || messages.size() == 0) return;
messages.stream().map(s -> s.body()).forEach(System.out::println);
try {
System.out.println("sleeping for 10 seconds...");
Thread.sleep(10000);
this.deleteMessage(messages);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void deleteMessage(List<Message> messages) {
String receiptHandle = messages.get(0).receiptHandle();
DeleteMessageRequest deleteRequest = DeleteMessageRequest.builder().queueUrl(this.queueUrl)
.receiptHandle(receiptHandle).build();
this.sqsClient.deleteMessage(deleteRequest);
}
public static void main(String[] args) {
System.out.println("SasquatchFinder " + SasquatchFinder.finderId + " running....");
SasquatchFinder finder = new SasquatchFinder("AKIA22EODDUZAMDPWSX7", "805hbufO3Sn18eDsBDrOzCgB/eT5KVPM/AIkIpoZ",
"https://sqs.us-east-1.amazonaws.com/743327341874/SasquatchImageQueue");
try {
while (true) {
finder.processMessage();
}
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("SasquatchFinder " + SasquatchFinder.finderId + " stopped.");
}
}
- Compile and run the producer and, if you had ran the consumer in the previous section, you should see the following output.
SasquatchFinder 1 running....
{
"stationid": 221,
"date": "2019-03-12",
"time": "091312",
"image": "/9j/4AAQ <snip> kf/9k="
}
sleeping for 10 seconds...
{
"stationid": 223,
"date": "2017-12-22",
"time": "091312",
"image": "/9j/4AAQ <snip> kf/9k="
}
sleeping for 10 seconds...
{
"stationid": 222,
"date": "2016-02-09",
"time": "091312",
"image": "/9j/4AAQ <snip> kf/9k="
}
sleeping for 10 seconds...- Navigate to the queue in the AWS Console and you should see no messages, as they were deleted after processing.

In this simple consumer we first create a client for interacting with the queue. We then obtain a single message from the queue. The program pauses to simulate processing. It then deletes the message from the queue by using the receiptHandle.
Because the program loops, it processes all three messages place on the queue when we created the consumer.
ReceiveMessageRequest
The ReceiveMessageRequest wraps the request to receive a message from an SQS queue. We use a builder to create the request. Then we specify the queue URL and the maximum number of messages to fetch. Finally, we specified a single message; however, you can specify multiple messages if desired.
ReceiveMessageRequest receiveMessageRequest = ReceiveMessageRequest.builder().queueUrl(this.queueUrl)
.maxNumberOfMessages(1).build();
DeleteMessageRequest
After processing the message you should delete it from the queue. We do this by obtaining the receiptHandle of the received message which is then used to delete the message.
String receiptHandle = messages.get(0).receiptHandle();
DeleteMessageRequest deleteRequest = DeleteMessageRequest.builder().queueUrl(this.queueUrl)
.receiptHandle(receiptHandle).build();The program processes all messages on the queue. This is a simple consumer, but you could have multiple consumers consuming messages from the same queue.
Message Visibility
A message might be processed twice when using a standard queue. A message, when picked up by a consumer for processing becomes invisible for a configurable time. When we created the queue we accepted the visibility timeout of 30 seconds. However, if processing takes longer than the visibility timeout, the message can be processed by another consumer. The following diagram illustrates.
There is a following wrinkle. What happens when the message is deleted from the queue a second time?
- Open the SQS Console and send a single message to the queue.
- Modify SasquatchFinder to sleep for 40 seconds between each message.
public void processMessage() {
ReceiveMessageRequest receiveMessageRequest = ReceiveMessageRequest
.builder().queueUrl(this.queueUrl).maxNumberOfMessages(1).build();
List<Message> messages = this.sqsClient
.receiveMessage(receiveMessageRequest).messages();
if(messages == null || messages.size() == 0){
return;
}
messages.stream().map(s -> s.body()).forEach(System.out::println);
try {
System.out.println("sleeping for 40 seconds...");
Thread.sleep(40000);
this.deleteMessage(messages);
} catch (InterruptedException e) {
e.printStackTrace();
}
}- After building the application, open two command-line windows and execute the program in the two different windows at the same time.
One running instance gets the message from the queue. The message’s visibility timeout set at 30 seconds begins. The instance sleeps for 40 seconds to simulate processing.
$ java -jar SQSTutorialConsumer-0.0.1-SNAPSHOT.jar 2
SasquatchFinder 2 running....
mymessage
sleeping for 40 seconds...The other instance finds no message on the queue, as the message is not visible.
$ java -jar SQSTutorialConsumer-0.0.1-SNAPSHOT.jar 1
SasquatchFinder 1 running....However, after thirty seconds the message is visible again on the queue and it is picked up and processed by the other instance.
$ java -jar SQSTutorialConsumer-0.0.1-SNAPSHOT.jar 1
SasquatchFinder 1 running....
mymessage
sleeping for 40 seconds...Meanwhile, the instance that first picked up the message finishes processing and deletes the message. In reality, it attempts to delete the message. But, as the other process already requested the message and a new receipt handle was issued, the message is not truly deleted.
$ java -jar SQSTutorialConsumer-0.0.1-SNAPSHOT.jar 2
SasquatchFinder 2 running....
mymessage
sleeping for 40 seconds...
Deleted message AQEB3/lhW8cY2cTsl2gd/GOsyPrt1J/SQn+ZR06ngf24aL5C8SqfUSPZfAl4uc2IwuZuLhZ/5BXYLWVU7AvmgSf0kb4zm0owKh01EXC4pGhvtNSsioLnk3nd4KiS5YEUO/EssCnRM1we7rXw0eLyd2LehOpPOZ49893lIJ6opy1vamQxxk6C+7iGcWbY0dMNTvrZqVaZw2JW/eZV5wI99rdUwRP16+RFj7XWsxEI5KJcExgnWY3jDRQv1mXqe5ZgWI9M7mqPH/rrx8afBdV2P53B7OK0uRm3vUGMzmW/xUgbsxsy5UB0+DZGLaccUAbegtC74LQ6BLZs64VlFxc8jAC2sp2gheLAZ849j4JkMrA8nWf+P+xKCjqdALeGrN754DcxnvhZv79R6sOGcp2lBtTOsA== by SasquatchFinder 2As the message is still being processed by the second instance, the first does not see the message. The second instance then deletes the message.
$ java -jar SQSTutorialConsumer-0.0.1-SNAPSHOT.jar 1
SasquatchFinder 1 running....
mymessage
sleeping for 40 seconds...
Deleted message AQEBgZK7kq12asCcVVNbFQNlQmmgYTXXO8OzgoJzHpAnqdsBtMnaBxSBvjjgyVqO3nqYwuhFoxPWgXhUoUcgDzejHHSG6dM/VNG1Wdv3Q93THsJPj6BSQSH/sLjX7qvdFYT20Es0jdhN4dQTNMPyaA3sA7a2x025cUYLsegKfMlWVfCDThABbn+0evwgkn3hmzwLBvAWZEGIp0mooZvYf6WiLcblbqCnx+Gh5j5/XvmIpWuT9ux3DQSTYH+f+XdfUxclXP6exwAYyyFm7xHJnlF9LXcRcKmv2QitpQjgjK3yQBLrogU6dPf8Zp34K8iwMr1TBXEi5mZnfPSA7Cl3a4N2c+MxB+OupGIGGY6uoy2gFLSiaaunsij/weB0FFaYaE/MFhMsXdMMhNho2o/lrq6SOA== by SasquatchFinder 1Notice that both messages have a different receiptHandle. The queue has an internal mechanism to avoid errors when a message is processed and subsequently deleted twice. However, it does not prevent processing a message multiple times. If we manipulated the processing time and/or the visibility timeout, we could have the message processed even more times.
To actually delete the underlying message, the most recent receipt handle must be provided. So in our example above, the first attempt to delete the message came after the second receipt handle was returned and so the message was not deleted. But the second attempt to delete the message was the most recent receipt handle and so the message was deleted. To delete a message you must pass the most recently issued receipt handle.
You should design your system to not be dependent upon the number of times a message is processed. Your system should be idempotent. If you need strict processing of once and only once, then use a FIFO queue.
Message Attributes & Dead Letter Queue
Let’s explore two topics important when working with AWS SQS queues: message attributes and dead letter queues. A message can have associated metadata. However, to receive messages with associated metadata the ReceiveMessageRequest must be explicitly instructed to fetch the associated metadata in addition to the message itself. A message might not be successfully processed. Rather than leaving the message on the queue to fail indefinitely, a dead letter queue can be configured to send message that fail a configurable number of times.
DeadLetter Queue
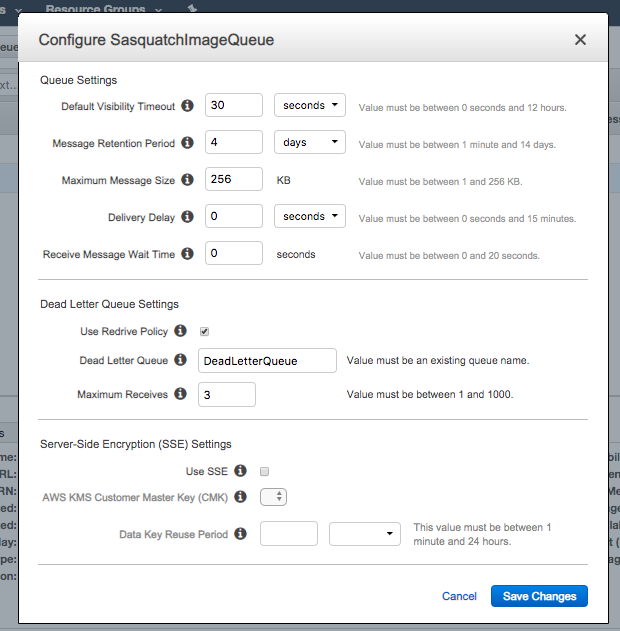
- Create a new standard queue named DeadLetterQueue.
- SelectSasquatchImageQueue and from the Queue Actions dropdown select Configure Queue.

- Modify SasquatchImageQueue to use DeadLetterQueue for its Dead Letter Queue.
Message Attributes
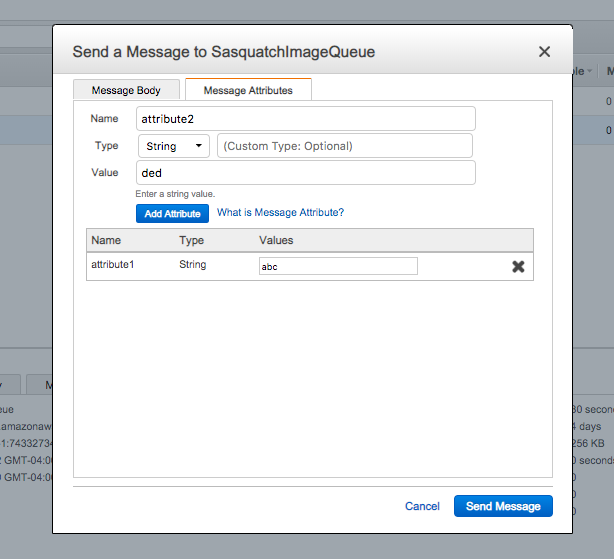
- Select SasquatchImageQueue and send a new message.
- When creating the message, add two message attributes.
- Open the SQSTutorialConsumer project and modify the processMessage method in SasquatchFinder. Note that you comment the call to delete the message.
public void processMessage() {
ReceiveMessageRequest receiveMessageRequest =
ReceiveMessageRequest.builder().queueUrl(this.queueUrl)
.maxNumberOfMessages(1).messageAttributeNames("*").build();
List<Message> messages =
this.sqsClient.receiveMessage(receiveMessageRequest)
.messages();
if (messages == null || messages.size() == 0) {
return;
}
messages.stream().map(s -> s.body()).forEach(System.out::println);
for (Message message : messages) {
System.out.println(message.messageId());
Map<String, MessageAttributeValue> attributes = message
.messageAttributes();
Set<String> keys = attributes.keySet();
for (String key : keys) {
System.out.println(key + ":" + attributes.get(key).stringValue());
}
}
try {
System.out.println("sleeping for 10 seconds...");
Thread.sleep(10000);
//this.deleteMessage(messages);
} catch (InterruptedException e) {
e.printStackTrace();
}
}- Compile and run the application. The message should process three times.
SasquatchFinder 1 running....
abc
e6ede972-9a6d-4c86-8c00-b16fe18977ff
attribute1:abc
attribute2:ded
sleeping for 10 seconds...
abc
e6ede972-9a6d-4c86-8c00-b16fe18977ff
attribute1:abc
attribute2:ded
sleeping for 10 seconds...
abc
e6ede972-9a6d-4c86-8c00-b16fe18977ff
attribute1:abc
attribute2:ded
sleeping for 10 seconds...- Return to the AWS Console and you should see that the message is placed on DeadLetterQueue.

To receive message attributes we were required to build the ReceiveMessageRequest with the explicit instruction to receive the message attributes by specifying messageAttributeNames. That method can take one or more attribute names, or a * to signify all attributes.
The message was sent to DeadLetterQueue, the queue configured as the SasquatchImageQueue dead letter queue.
If you wish to learn more about message attributes, here is a tutorial on Amazon’s website: Sending a Message with Attributes to an Amazon SQS Queue.
If you wish to learn more about dead-letter queues, here is a tutorial on Amazon’s website: Configuring an Amazon SQS Dead-Letter Queue.
maxNumberOfMessages
The ReceiveMessageRequest can receive more than one message at a time if more are available on a queue. Above we set the maximum number of messages as one. Let’s explore what happens we change the setting to more messages.
- Modify the SasquatchFinder class by creating a new method called deleteMessages.
- Have the method iterate over all received messages.
public void deleteMessages(List<Message> messages) {
for(Message message:messages) {
String receiptHandle = message.receiptHandle();
DeleteMessageRequest deleteRequest =
DeleteMessageRequest.builder().queueUrl(this.queueUrl)
.receiptHandle(receiptHandle).build();
this.sqsClient.deleteMessage(deleteRequest);
System.out.println("Deleted message " + receiptHandle
+ " by SasquatchFinder " + SasquatchFinder.finderId);
}
}- Modify processMessage to call deleteMessages rather than deleteMessage.
public void processMessage() {
ReceiveMessageRequest receiveMessageRequest =
ReceiveMessageRequest.builder().queueUrl(this.queueUrl)
.maxNumberOfMessages(10).messageAttributeNames("*").build();
List<Message> messages = this.sqsClient
.receiveMessage(receiveMessageRequest).messages();
if (messages == null || messages.size() == 0) {
return;
}
messages.stream().map(s -> s.body()).forEach(System.out::println);
for (Message message : messages) {
System.out.println(message.messageId());
Map<String, MessageAttributeValue> attributes = message
.messageAttributes();
Set<String> keys = attributes.keySet();
for (String key : keys) {
System.out.println(key + ":" + attributes.get(key).stringValue());
}
}
try {
System.out.println("sleeping for 10 seconds...");
Thread.sleep(10000);
this.deleteMessages(messages);
} catch (InterruptedException e) {
e.printStackTrace();
}
}- Compile the application.
- After compiling, navigate to the AWS SQS Console and add five messages to the queue, with the message body of a1, a2, a3, a4, and a5 respectively.

- Run the application and you should see output similar to the following.
SasquatchFinder 1 running....
a4
98a42736-e4b5-4dfd-9428-3e32d2ea145d
sleeping for 10 seconds...
Deleted message AQEBqmAqpGs85ERM2Y8EnD4zjBPO1KxomlhJgQCPQ+JO3gjYhRcZbflS1gKJT1kas0JId7bX4X+OmFWQfC8r+gZGr02jwBcKlhvSUIv0tx13Q88EPpzMJDNbB9w9oKbgR+hc8c0nZQPPjJ2uHu7KeQfTmIdK/dt49cs/GHFRZeq3pIUWN2jJO8h0UdlpLeFKbB96WjPvakAnXDFd46meejQvBod0x18L1Y1dBt6cZc5+9AbB6eb4bJjV5dKvyDCtIUP2XFZ8iwtZF1lxntzqXxdMGYCjzaQ/oqQ5EmVJ/pFMTgWlUTks+qVFMu7a/sOCfQm7bFwE3AofXQROAK3B0crssZTbzoqQ9oJv+nj0kn596gidN+gygrISvF9vESIG1M5Ll+Lk2ADWQeO+2UA/AJax3A== by SasquatchFinder 1
a1
a5
c167bb7a-f356-4d5b-aa0f-ea90075cef50
f0d79263-05da-485e-bf6a-fa6b3f9fe92a
sleeping for 10 seconds...
Deleted message AQEBGwtlQPM080KnHDAOWUsZKUQ4PWfLP2g/AFn0sr9ERDOJFssjl7rNXl3mL6ryqoH9EgiPEGyGXwPm6n/FSsfbPA9OSMJYLq0Fho9qtpkcoI0mmAqRPQ/7h0J++zAmmf3bflcD9BqJS+hz4a/Di8Eo6GB0oWJUFZEFYcKWnIUGMNgnQfY3xs1DF9UuNZdsu7h3KN9hGGy3vSTuLvJJox7DDHSgY+QU3nisT5dTSfltKc9vJMQq2mPxB/f2EUmgwKQ82f10A6lPlSjVuiyNtGkKVau3BorKINz3dtG+xAHd5wWfALFExyip7zFZl6wVsnzfKox9QBaxRSrukIfx3+w5rIilq1QujPpNqLKItlxOvaXvDvxi/8lWv31S5UNlY7ooEOYSIkh1wnNwXKY7ZP4aQQ== by SasquatchFinder 1
Deleted message AQEBLIUJqmODdigrnQ88hzta9Zr+PaQnctLqmYrQT0iU5ZxvaLPy0PGNTe7eKwLHbBvc+WdDbLXK951WaPYWoY9dbMJZMyRNnjEj3doGoUkmBOm0LzTs1xDkV+QPb3fGH3s+mxh2TFhX3KFOwXrvf4uqkpx9mHdGioMWa86NSsCUUEQ3vXGUXprSdGsSqXUsoAug7v6wBU3QIPzeQm8pRLmjbZPdx+ndeV80FwnFkxDfNx/mtpAibum4ON4CxDUB66jLC7nVRe0XxXBllM2G/brS7jseqbz+Q61qbFjLNWKo96kTBIrYDjvZEmcSQdp37cYMf4rO/vsr+/XCNUtbtcD8h9Xk8Fc+atcIsuQSlrLbYMplVgN3EwogYlXJsB9GSOlVQVpO+gwOLBXonXJ6i3EAbQ== by SasquatchFinder 1
a2
a5
e65fbcc2-2c4a-42f6-8b61-ca97dad4826e
b2bc665c-4c1c-42c7-b3d2-c1d5bf048ee9
sleeping for 10 seconds...
Deleted message AQEB2FZyDGQEOUgLxR9wIxAiJbk++Ktec9RLon3nAZr7bPeQu2QJ8iVxRMNg92ZgvoPY5qsBndcRGEQjI5zKHQ/r62tg4+LMWwFLSDBhDF3d55w6OosgLf+K7AIBICGAeTJanTkhCzQlWYM+HCDFEve+NhPsr5+/zabaeZrkKwSBh8E2jTCmr29LmNR6ld9Bz0NSboj5gi+Gxa3dTu+xPGMLMjANVQ1Qa1BhoYEI0QP8kl9gL8aBpLhkeW1eWXgRaRtRcTAVpjxF73ZlUEFVNyYeE/Mwz9ZT2lWRftj6dv5p2PUG5Z6VtbbBw/9AXQElJUTgfHKGd4iGEjo4A3l6ff6g/NVJzm/LkGq6909txbTIk8PSp5istS4bM318W6VG2ten9jYSU7+pj8H809AHoW3VEw== by SasquatchFinder 1
Deleted message AQEBMdzd33/uz7jNQMnBJu1ne7GRh9g2xHx6X0cPWLsU0emEN0G5SGbr3nF/9QklDrrW42BX1HW6IDWxvhlI4/bOByZobYOfjmv5Cr8rDEJYnNKWxqxBZeQqjArKTy90WeEs0puUw4l6PouEZOv35daHO0h01A8Dpk/oMlVBi/OZFCIM4fetG2tUxwa7eU15WiEF4mklZqqJx2bVTbdiZqwhOucgqXlyXK3IJ5FtBFd6ACtEyX1tQmIBn6njmk/CBuX0v5+LzaxlntHy9Q+FpjuPLEyyE5wGqIk9B8Kcqv469pnaE3UJJaCK7DxgG70rF/7M1kYzaDRbRBYJB9jS3W9b8qZpj1JU4JM4euH9xBP4j59MvdwgIs4lSPvO1F3NtdCuNeOOMF15/n1WvU2U31jSeg== by SasquatchFinder 1
As the example illustrates, you can specify the maximum number of messages to process, but not the number of messages. This should seem reasonable, as the consumer does not know how many messages are in the queue before processing. As an aside, note that the messages were not processed in the same order they were received in the listing above.
First In First Out (FIFO) Queue
Let’s modify the project to use a FIFO queue and rerun the two consumer instances simultaneously. Note that neither the consumer nor the producer know they queue’s type. They only know it’s url.
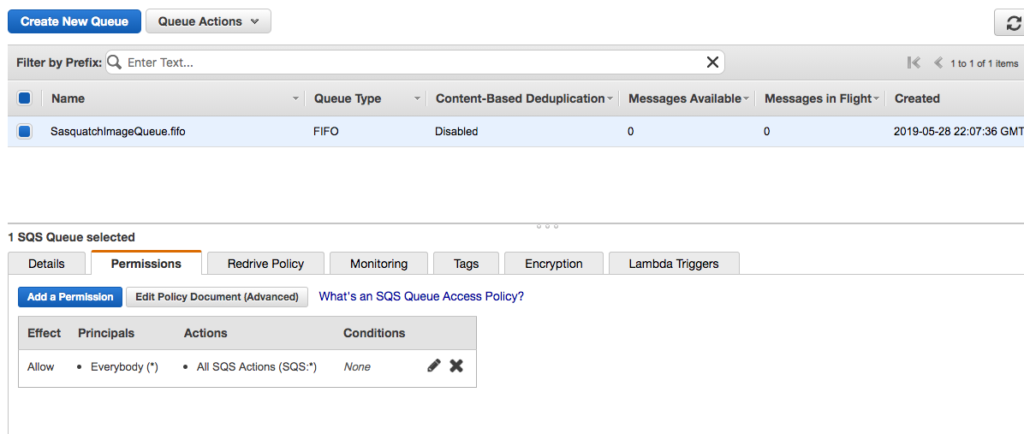
- Create a new queue named SasquatchImageQueue.fifo of type FIFO Queue.
- Click Quick-Create Queue.
- Create a new permission, but let’s be lazy and check the Everybody checkbox and the All SQS Actions checkbox. You would obviously not do this in production.
- Modify both the consumer and producer to use this queue’s URL.
https://sqs.us-east-1.amazonaws.com/743327341874/SasquatchImageQueue.fifo- Modify the sendMessage method in the producer. Note the removal of the delaySeconds and the addition of the messageGroupId.
public String sendMessage(String message) {
SendMessageRequest request = SendMessageRequest.builder()
.queueUrl(this.queueUrl).messageBody(message)
.messageGroupId("mygroup").build();
SendMessageResponse response = this.sqsClient.sendMessage(request);
return response.messageId();
}
- Compile and run the producer application after changing the queue and the three messages are sent to the queue.
- Compile and run the consumer application and the three messages are processed in the same order they were received.
Message Visibility
- Modify SasquatchFinder processMessage to simulate processing by sleeping for 40 seconds.
public void processMessage() {
ReceiveMessageRequest receiveMessageRequest =
ReceiveMessageRequest.builder().queueUrl(this.queueUrl)
.maxNumberOfMessages(1).build();
List<Message> messages = this.sqsClient
.receiveMessage(receiveMessageRequest).messages();
if(messages == null || messages.size() == 0) {
return;
}
messages.stream().map(s -> s.body()).forEach(System.out::println);
try {
System.out.println("sleeping for 40 seconds...");
Thread.sleep(40000);
this.deleteMessage(messages);
} catch (InterruptedException e) {
e.printStackTrace();
}
}- Compile and run the application. Note you get an SqsException.
SasquatchFinder 2 running....
messageMine
sleeping for 40 seconds...
software.amazon.awssdk.services.sqs.model.SqsException: Value AQEBBJL+BlwyhRLnQGxaIKDkkrEv1sU6VnHzYM51Q0UFdx2lDyWvKoI/JYcs7MktVJ1Nmyr1mCVX/cpcqS9dMqq7Ual92VLEXDS9hEYM/qg1vdEGHB60OktMzpidyWBenQQyybzXofO+pAdKOYpC/wiEw8GBPsmFDCHpVn1hxHeLSNJyw10SwNv3DTXQXk4Pe+v3yGf23bf8sDk7Rx7ApqWYi8n8z9uijZAQBdwuFpUrZslivMWCzid6AFOXI/k83+/tKnSMyT0/Mx0rng0v1k4WliSgv5YJo5HyEZTt+cOBwfA= for parameter ReceiptHandle is invalid. Reason: The receipt handle has expired. (Service: Sqs, Status Code: 400, Request ID: 845b9538-4104-5428-aa2f-c05092244385)
at software.amazon.awssdk.core.internal.http.pipeline.stages.HandleResponseStage.handl <snip> at com.aws.tutorial.sqs.main.SasquatchFinder.main(SasquatchFinder.java:58)
SasquatchFinder 2 stopped.
Attempting to delete messages fail when executed after the visibility timeout window if using FIFO queues.
Conclusions
In this tutorial we created an Amazon SQS Queue. After creating the queue, we created a message producer and a message consumer using the AWS Java 2 SDK. We then explored several topics such as message attributes, dead-letter queues, and message visibility. We also created a FIFO queue.
Amazon’s SQS Queue is a easy to use queue that takes the infrastructure management hassle away from the organization. In this tutorial we only examined SQS basics. For more information, refer to both the Java 2 SDK Developer’s Guide and the SQS Developer’s Guide. Remember, the API from version 1 to 2 changed, so when in doubt, assume you need a builder for an object and that you must configure the object when building it. However, the API is consistent and once you start working with the API translating 1.1. code to 2 is intuitive.
- Amazon Simple Queue Service: Developer Guide
- Amazon Simple Queue Service: API Reference
- AWS SDK for Java 2.0 Developer Guide
- AWS SDK for Java 2.0 API Reference
GitHub Project
The GitHub Project, SQSTutorial is available here.