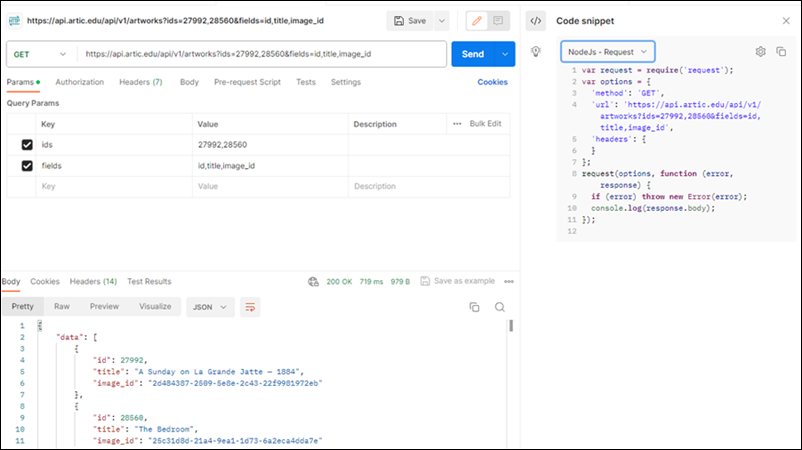
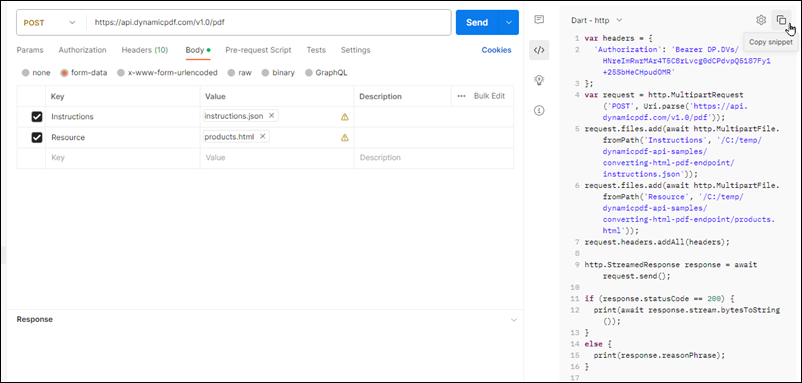
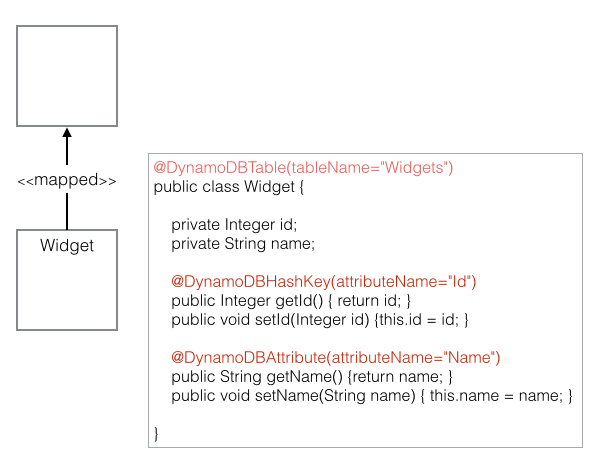
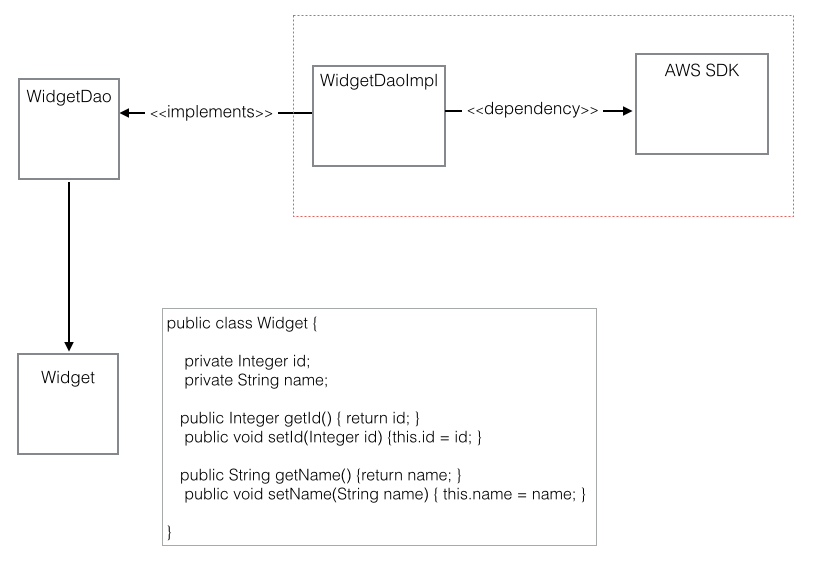
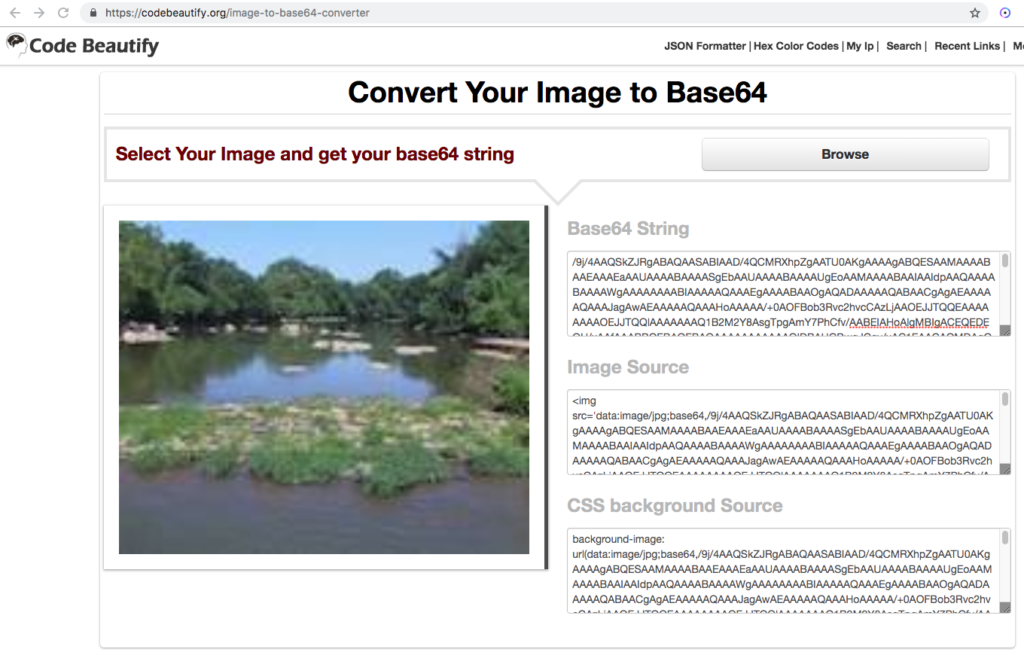
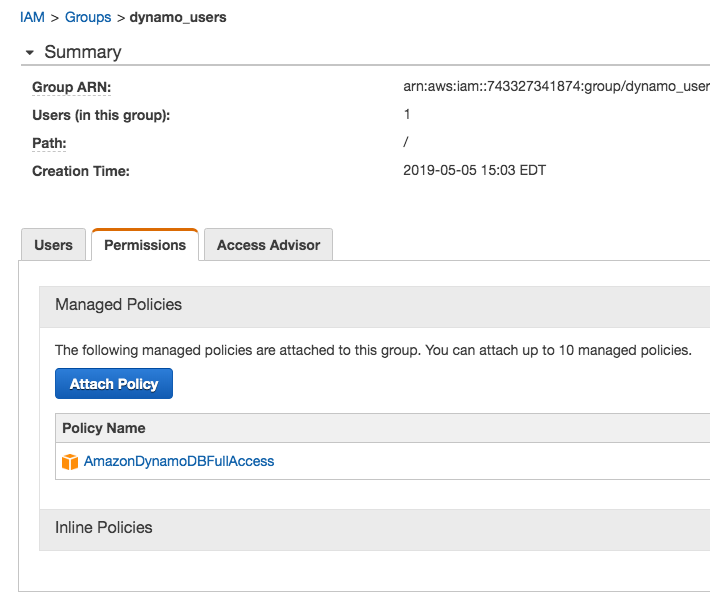
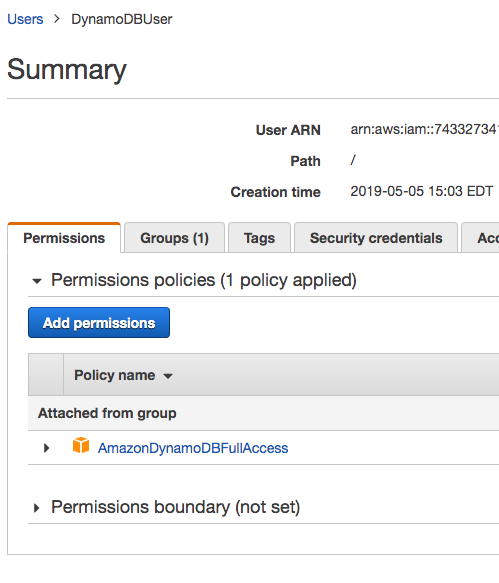
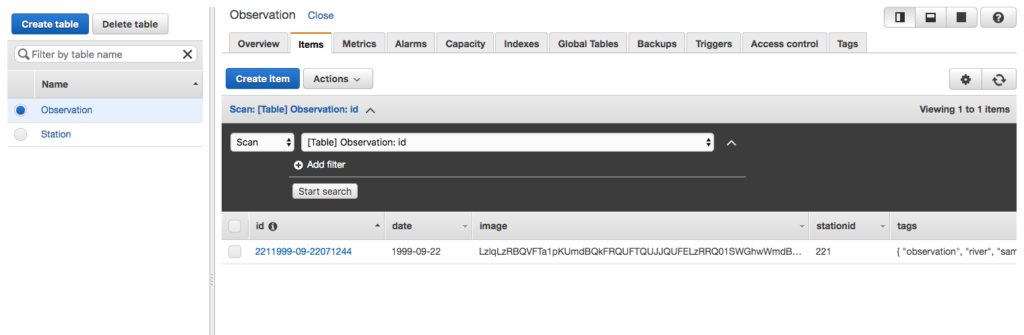
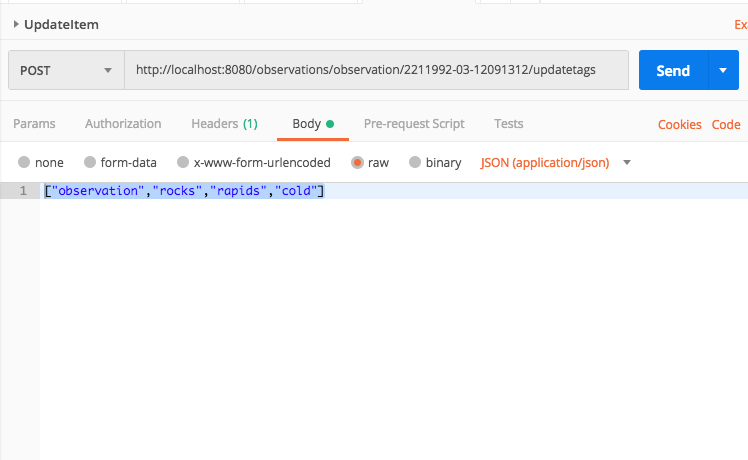
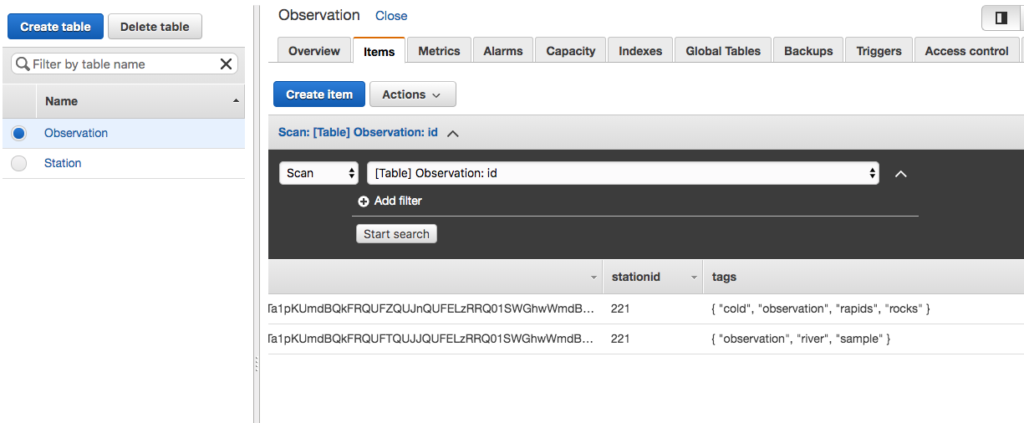
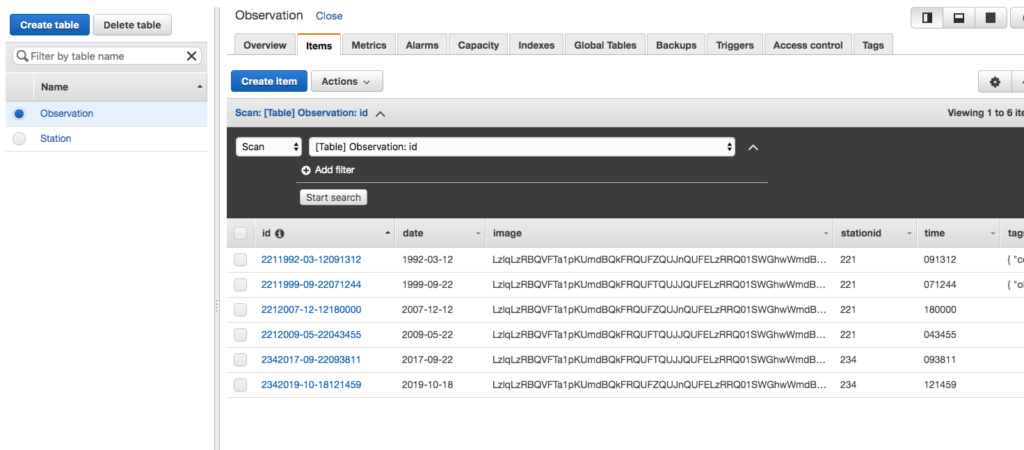
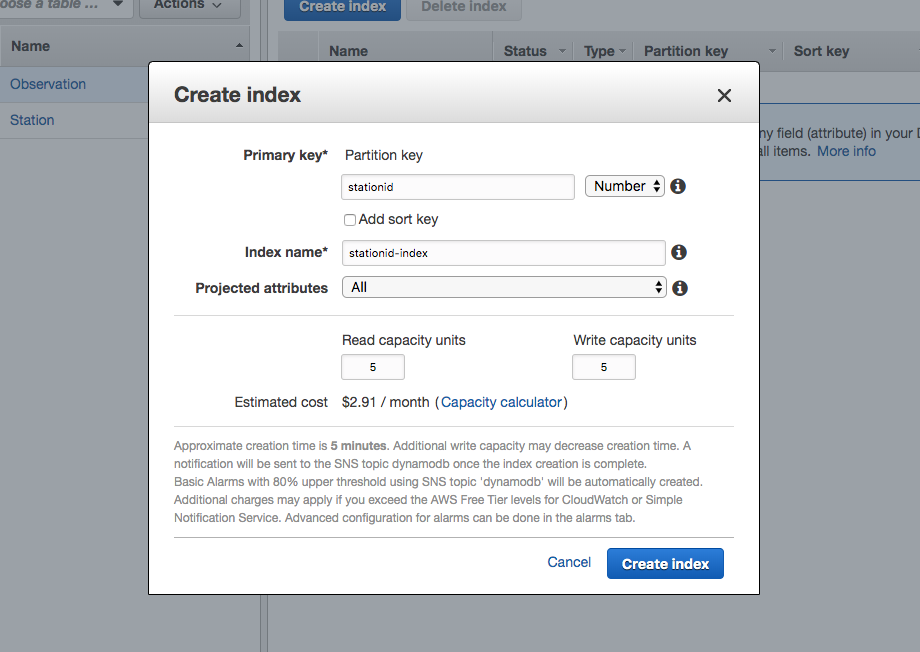
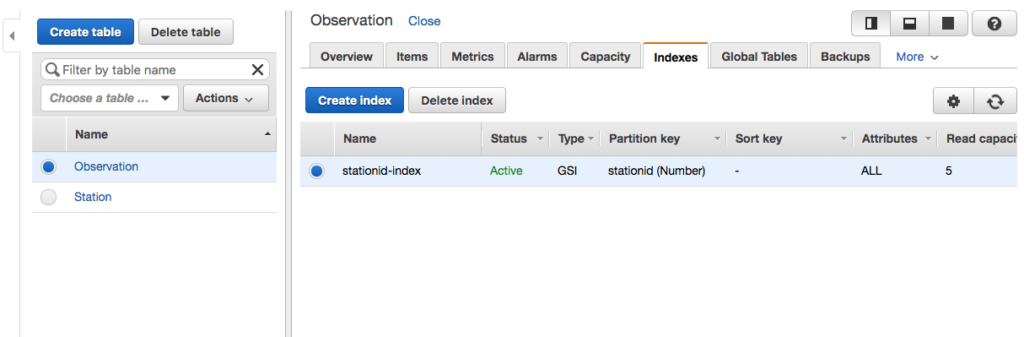
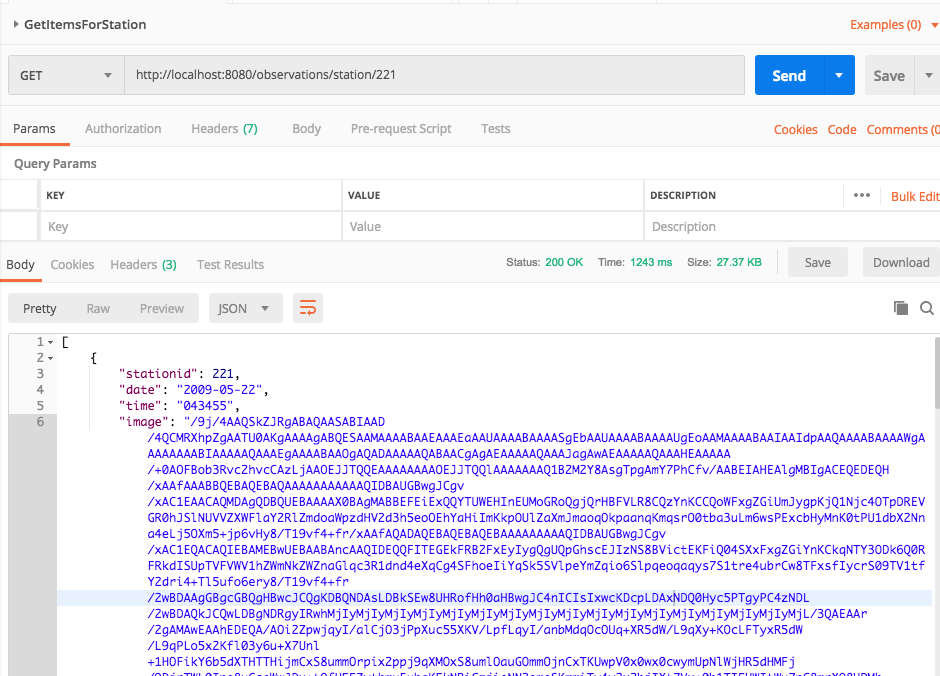
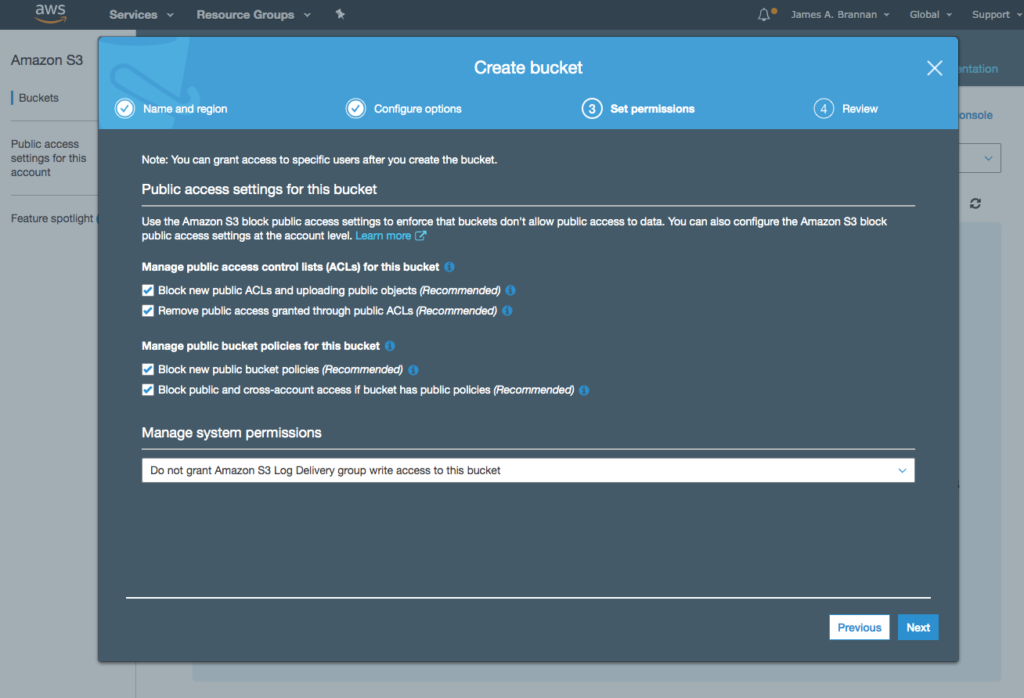
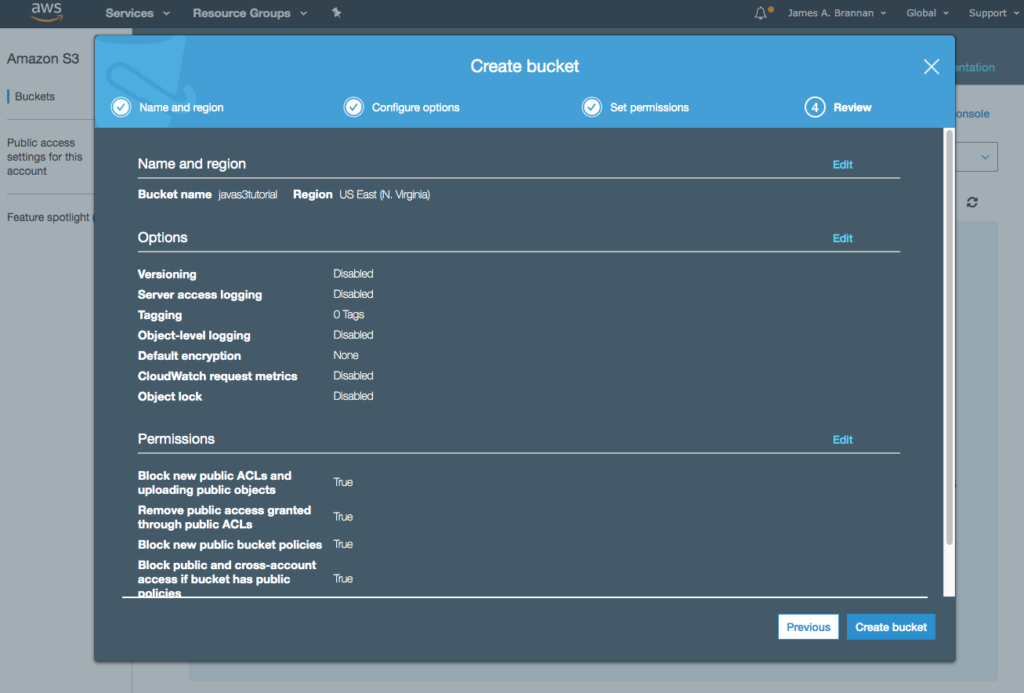
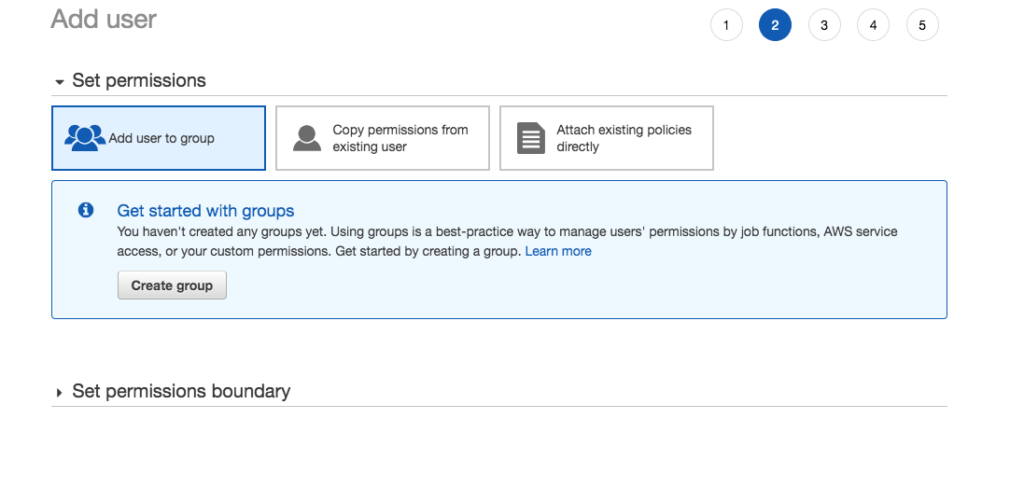
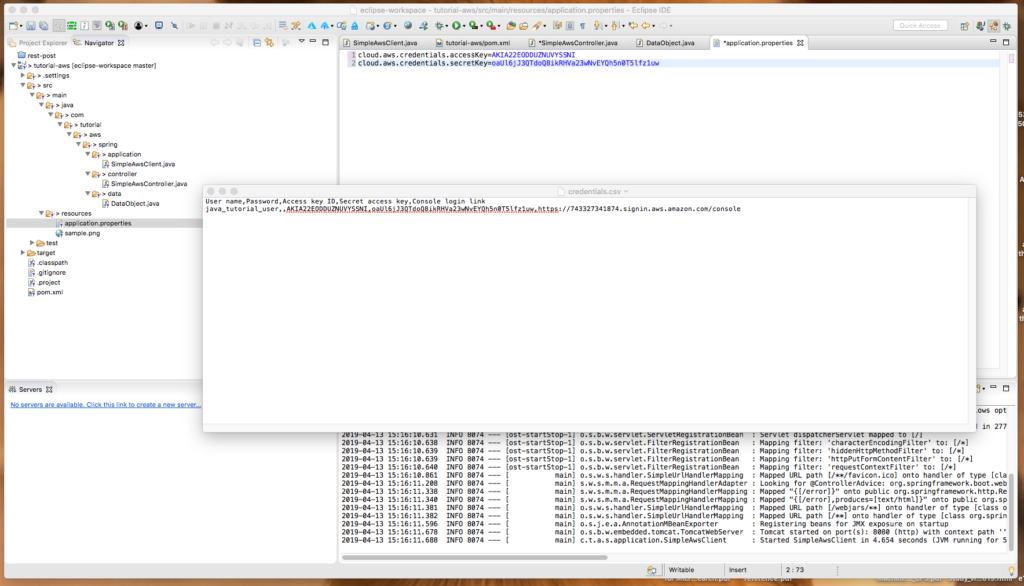
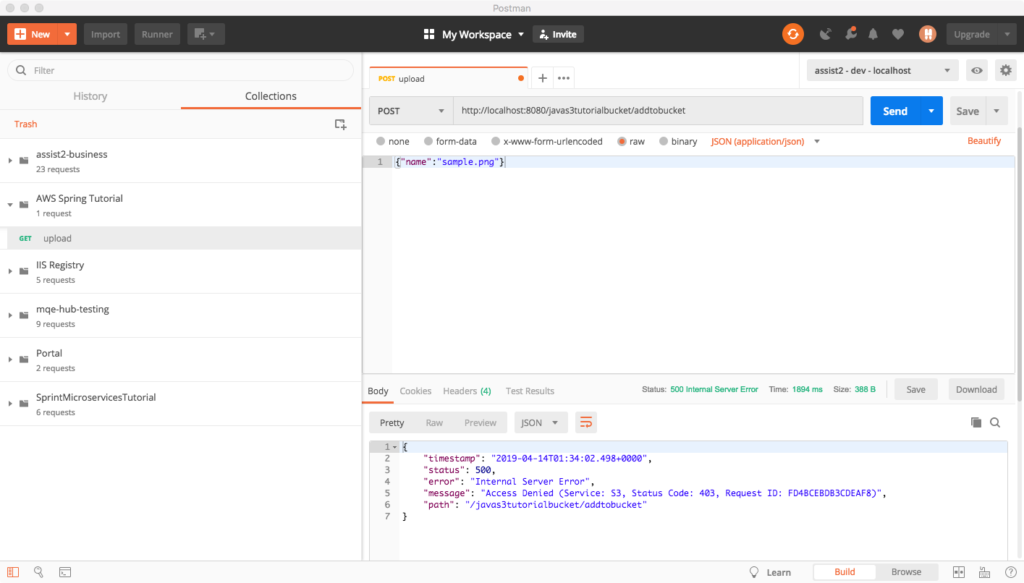
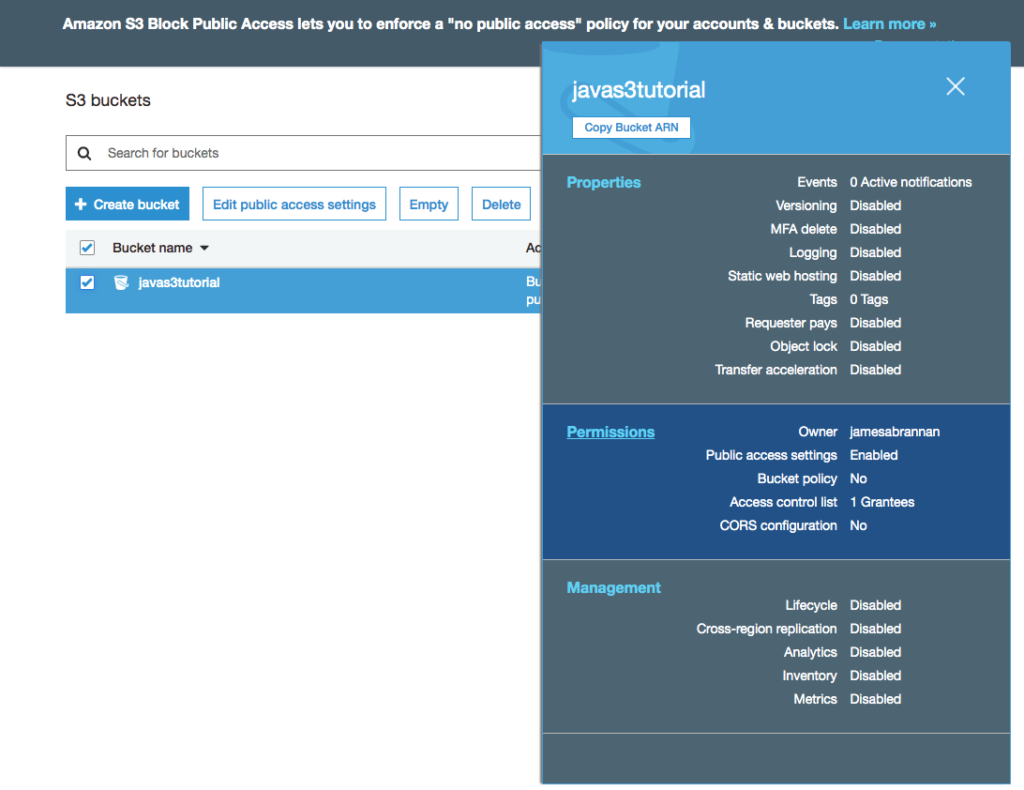
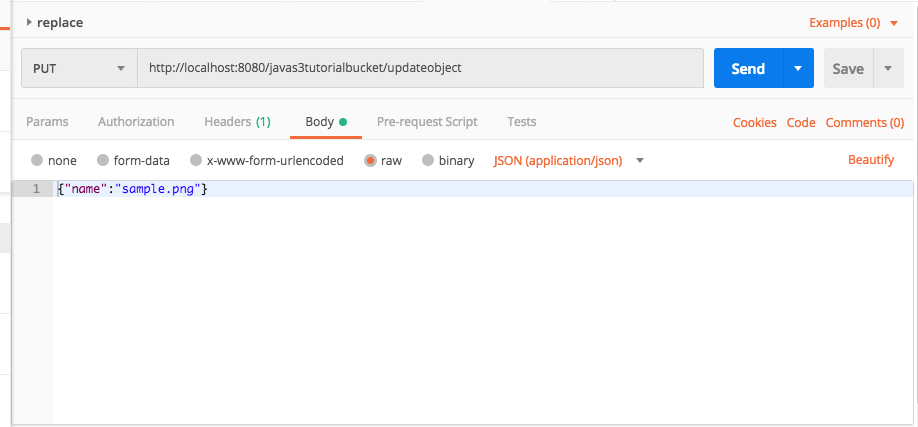
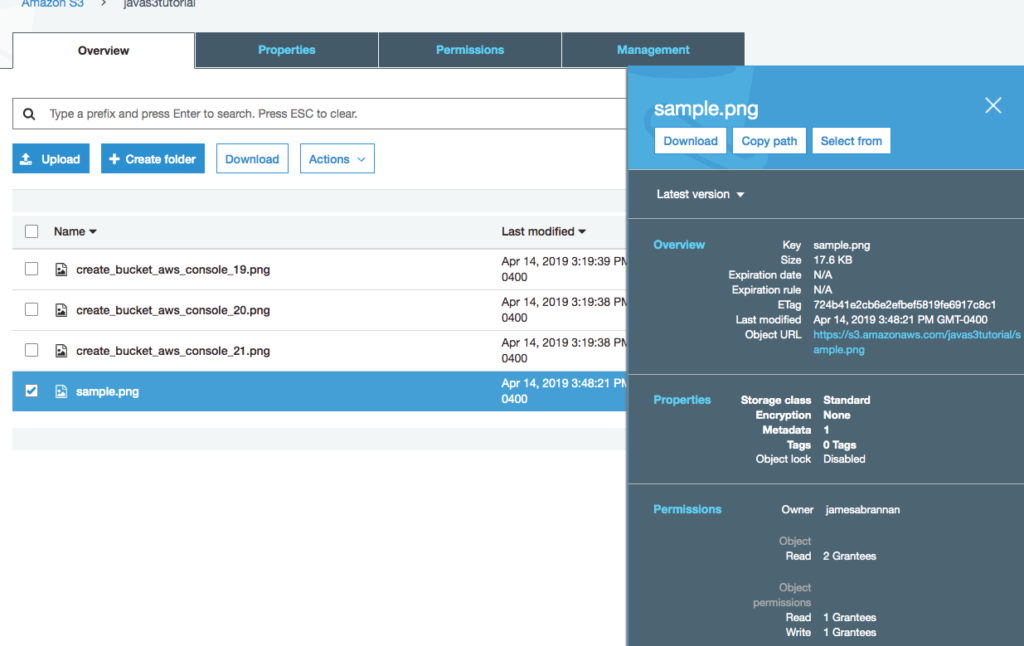
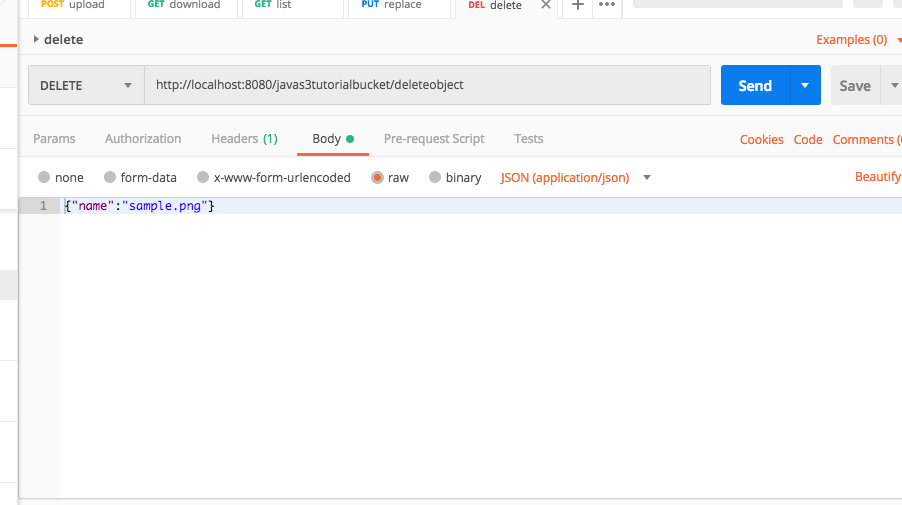
The other day I was supporting a client in my day job by helping him use Postman to generate HTTP Post requests. The problem was, that his language of choice was Dart, a language I had never heard of, much less used. I’ve worked with Postman for quite some time, but I never clicked this discrete link to the right of the request.
Imagine my surprise when I clicked that link and a code snippet showing the Dart code.
It generates cURL requests,
Python code snippets,
Node.js code snippets,
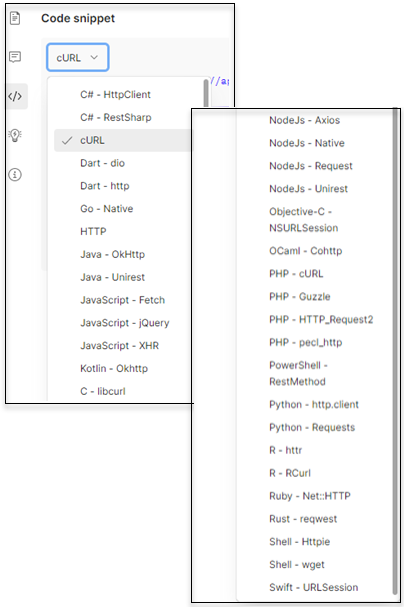
and many more. For example, Postman can generate snippets for over 30 different languages or frameworks.
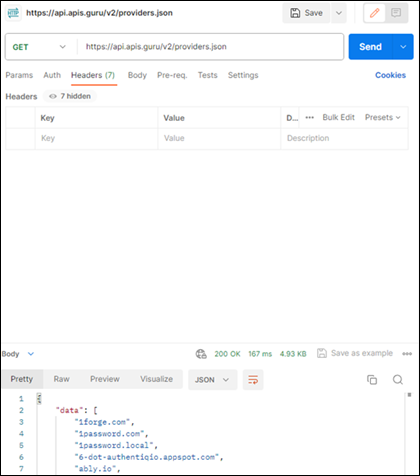
How to Generate Python Code Snippets
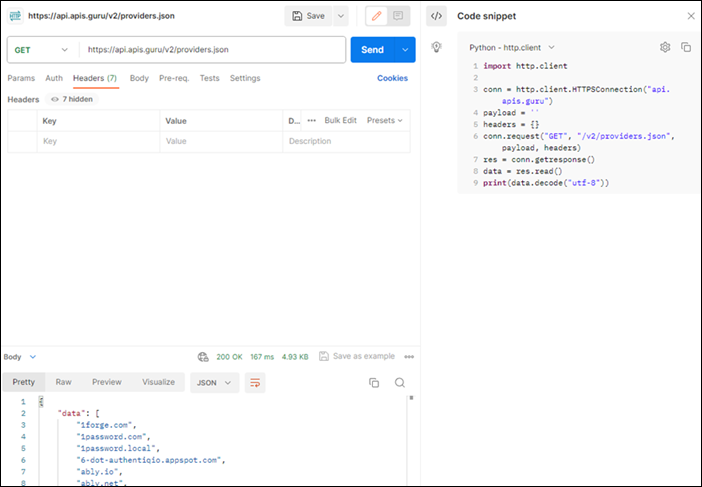
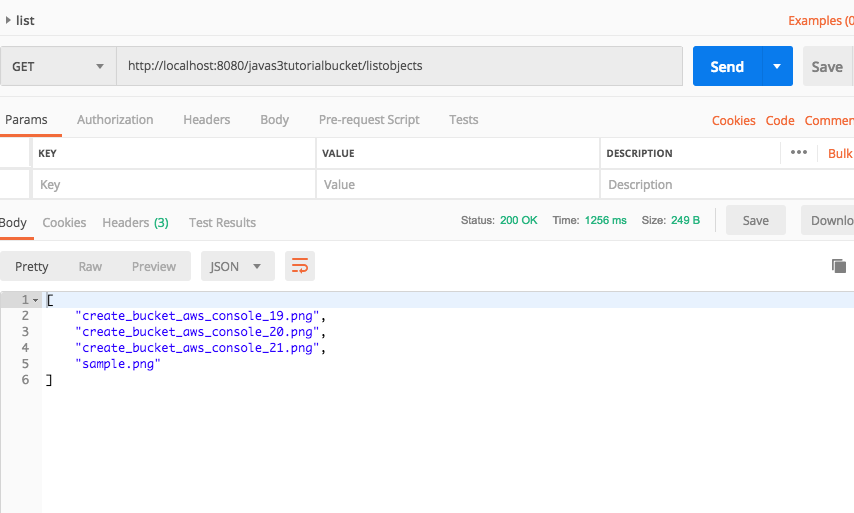
Create the request you desire, for example, the following is a simple GET request listing available APIs on the API Guru website.
Click the small Code generate button.
Select your desired language or framework.
Click the copy icon to copy the code snippet to your clipboard.
Here’s a video by a member of the Postman team showing how to use the code snippet generation feature.
I’ve been working as the Developer Evangelist for DynamicPDF for some time now. As well as our desktop/server product, we offer a cloud version of our software: DynamicPDF Cloud API. It’s a powerful cloud API for creating and manipulating PDFs for your business. In this post, I outline some of its features and why you should use it if you create PDFs for your organization.
The cloud API is built on the powerful DynamicPDF Core Suite, a software platform that has been used for several decades by many of the world’s largest corporations.
Returns a PDF after performing one of the PDF endpoint’s tasks (page, dlex, html, word, image) or merging.
REST Endpoint documentation
DynamicPDF Designer Online
DynamiciPDF Cloud API also offers the following client libraries to make using the endpoints easier.
C#
Java
Node.js
PHP
Go
Python
It also offers – arguably the most powerful tool available anywhere online – DynamicPDF Designer Online, a graphical tool for creating rich PDF documents using your organization’s business data.
The API is free to try, and the documentation and support are top-notch. I should know – I wrote most the documentation, tutorials, and example code. There are tons of tutorials, and our support is great.
Here you use the put_record and the put_record_batch functions to write data to the Kinesis Firehose client using Python. If after completing the previous tutorial you wish to refer to more information on using Python with AWS, refer to the following two information sources.
In the previous tutorial you created an AWS Kinesis Firehose stream for streaming data to an S3 bucket. Moreover, you wrote a Lambda function that transformed temperature data from Celsius or Fahrenheit to Kelvin. You also sent individual records to the stream using the Command Line Interface (CLI) and its firehose put-record function.
In this tutorial you write a simple Kinesis Firehose client using Python to the stream created in the last tutorial (sending data to Kinesis Firehose using Python). Specifically, you use the put-record and put-record-batch functions to send individual records and then batched records respectively.
Creating Sample Data
Navigate to mockaroo.com and create a free account.
Click Schemas to create a new schema.
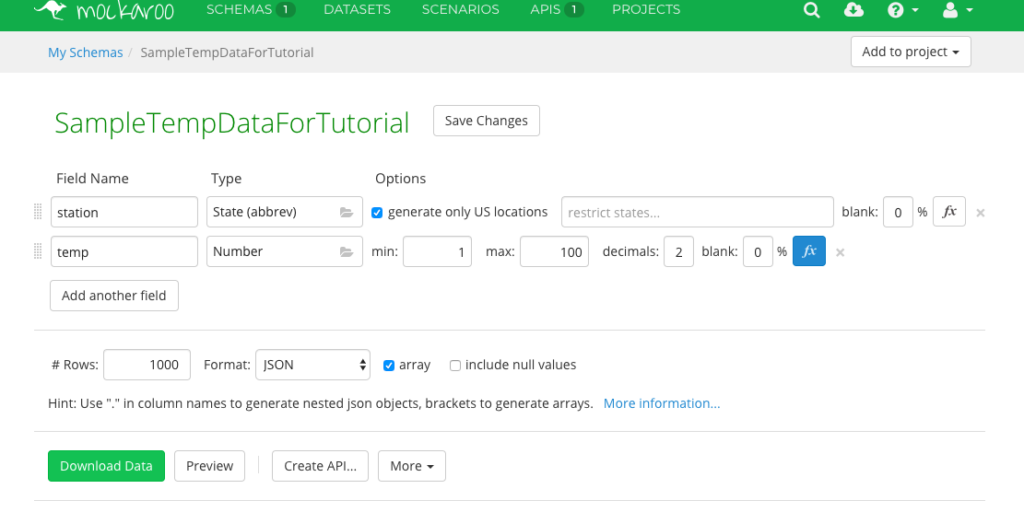
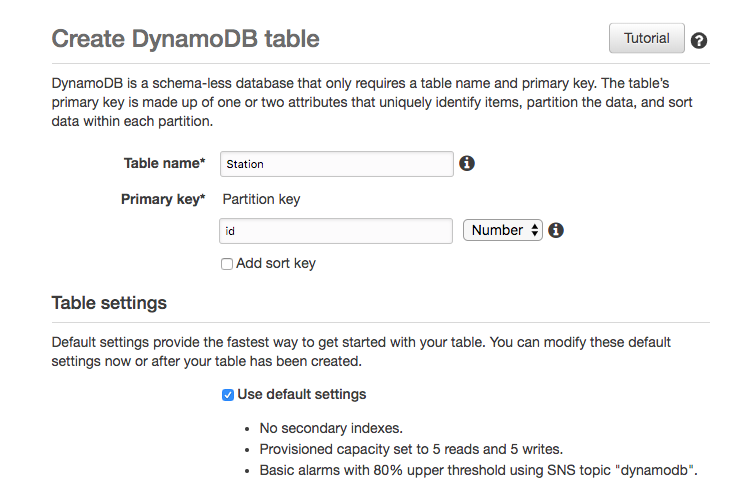
Name the schema, here I named it SampleTempDataForTutorial.
Creating a schema in Mockaroo
Create a field named station and assign its type as State (abbrev).
Create a field named temp and assign it as Number with a min of one, max of 100, and two decimals.
Creating the SampleTempDataForTutorial data in Mockaroo
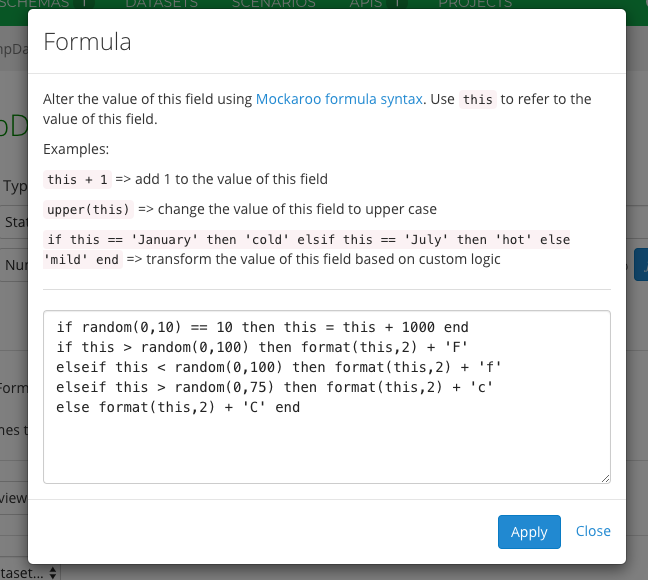
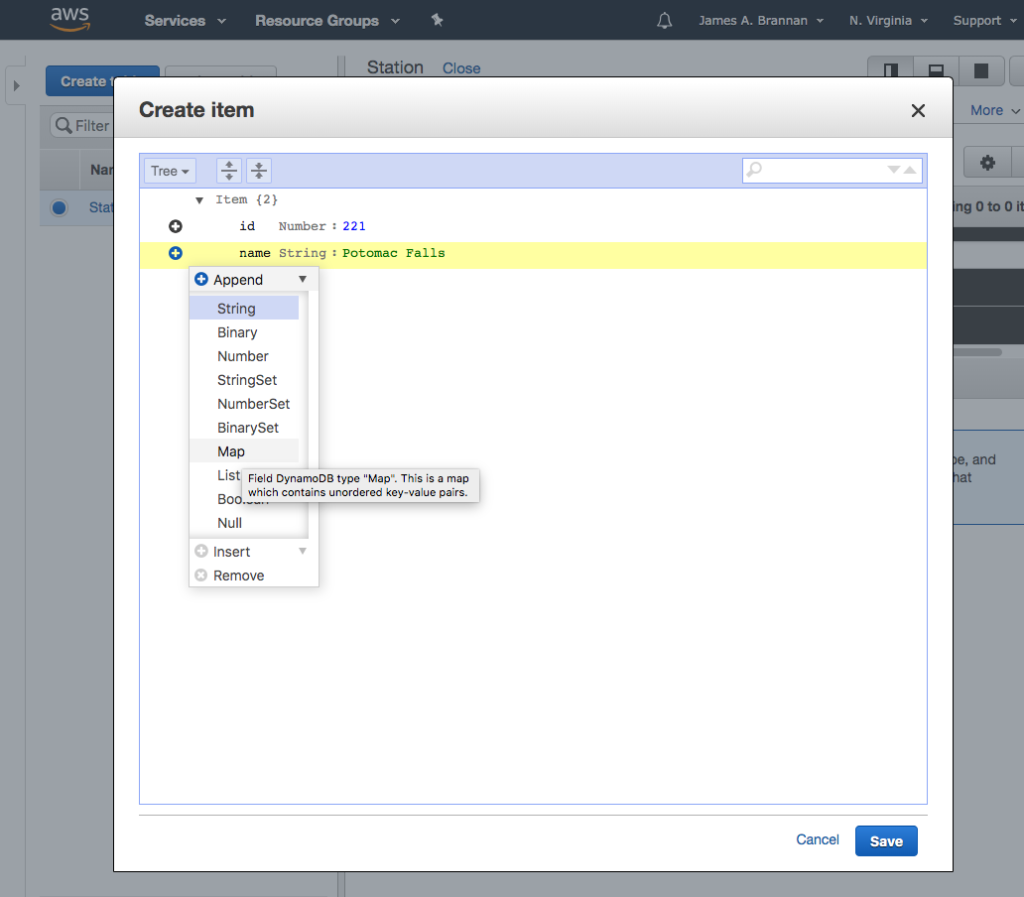
Click the fx button and create the formula as follows.
if random(0,10) == 10 then this = this + 1000 end
if this > random(0,100) then format(this,2) + 'F'
elseif this < random(0,100) then format(this,2) + 'f'
elseif this > random(0,75) then format(this,2) + 'c'
else format(this,2) + 'C' end
The formula randomly generates temperatures and randomly assigns an F, f, C, or c postfix. Note that it also generates some invalid temperatures of over 1000 degrees. You will use this aberrant data in a future tutorial illustrating Kinesis Analytics.
Creating a formula in Mockaroo for a field
Click Apply to return to the main screen.
Enter 1000 for rows, select Json as the format, and check the array checkbox.
You should have a file named SampleTempDataForTutorial.json that contains 1,000 records in Json format. Be certain the data is an array, beginning and ending with square-brackets.
Python Client (PsyCharm)
Here I assume you use PsyCharm, you can use whatever IDE you wish or the Python interactive interpreter if you wish. Let’s first use the put-record command to write records individually to Firehose and then the put-record-batch command to batch the records written to Firehose.
Writing Records Individually (put_record)
Start PsyCharm. I assume you have already installed the AWS Toolkit and configured your credentials. Note, here we are using your default developer credentials.
In production software you should use appropriate roles and and a credentials provider, do not rely upon a built-in AWS account as you do here.
Create a new Pure Python application named StreamingDataClient.
Create a new Pure Python project in PsyCharm
Create a new file named FireHoseClient.py and import Boto3 and json.
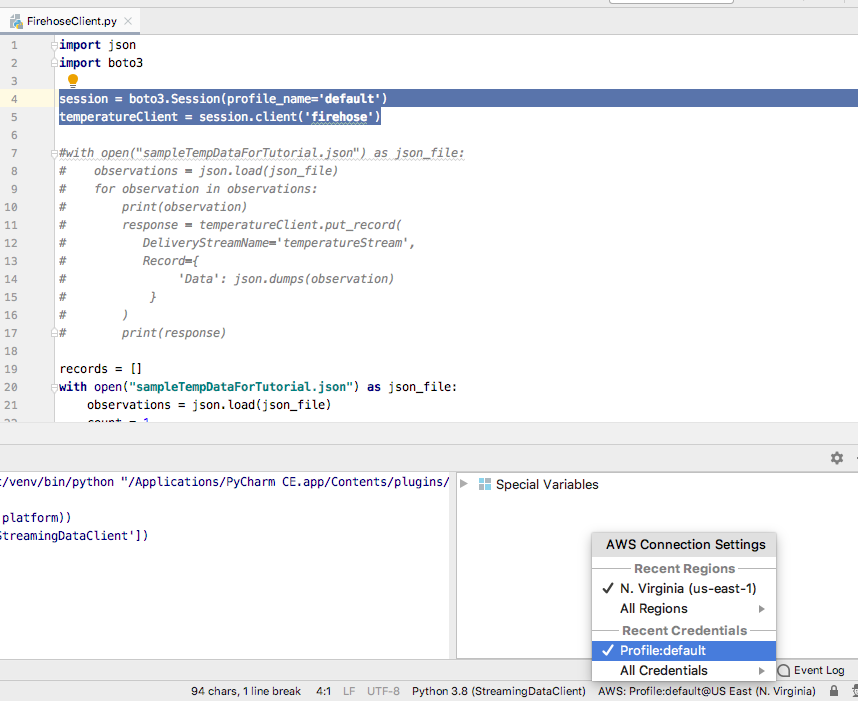
Create a new session using the AWS profile you assigned for development.
Create a new firehose client from the session.
Creating a session using default AWS credentials
Write the following code.
import json
import boto3
session = boto3.Session(profile_name='default')
temperatureClient = session.client('firehose')
with open("sampleTempDataForTutorial.json") as json_file:
observations = json.load(json_file)
for observation in observations:
print(observation)
response = temperatureClient.put_record(
DeliveryStreamName='temperatureStream',
Record={
'Data': json.dumps(observation)
}
)
print(response)
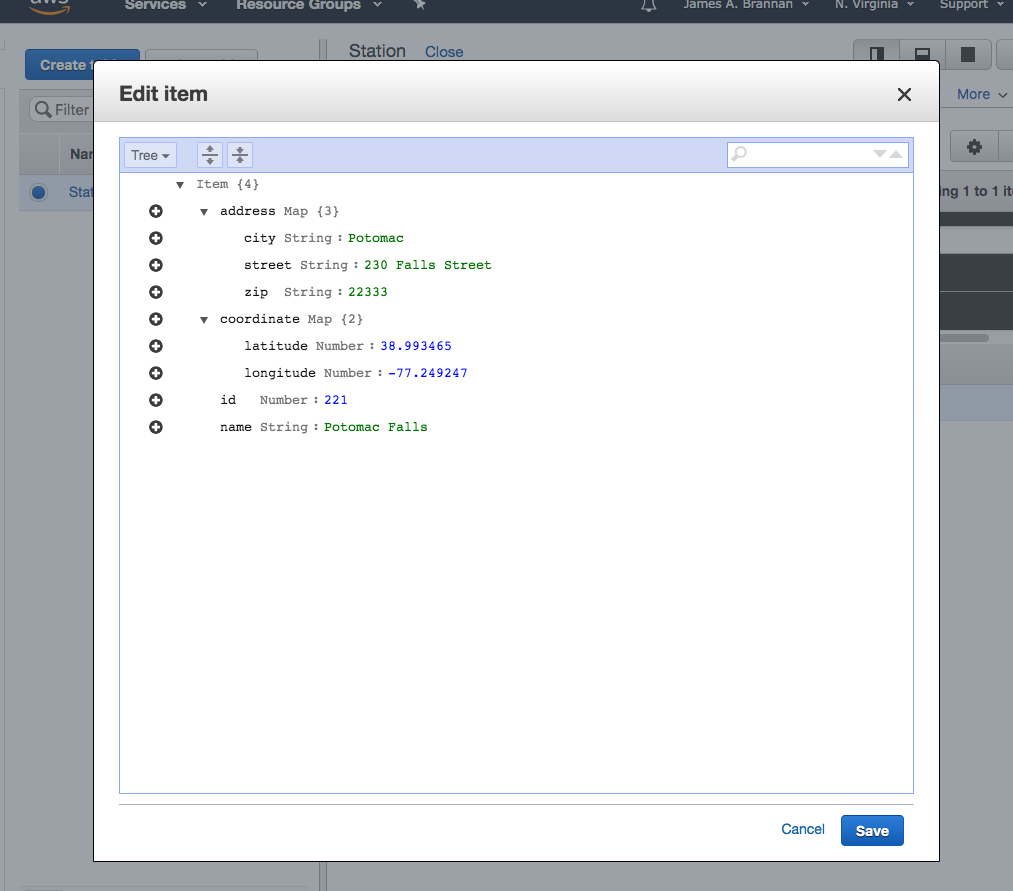
In the preceding code you open the file as a json and load it into the observations variable. You then loop through each observation and send the record to Firehose using the put_record method. Note that you output the record from json when adding the data to the Record.
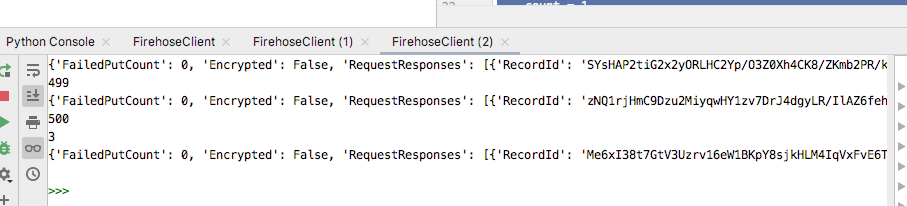
You should see the records and the response scroll through the Python Console.
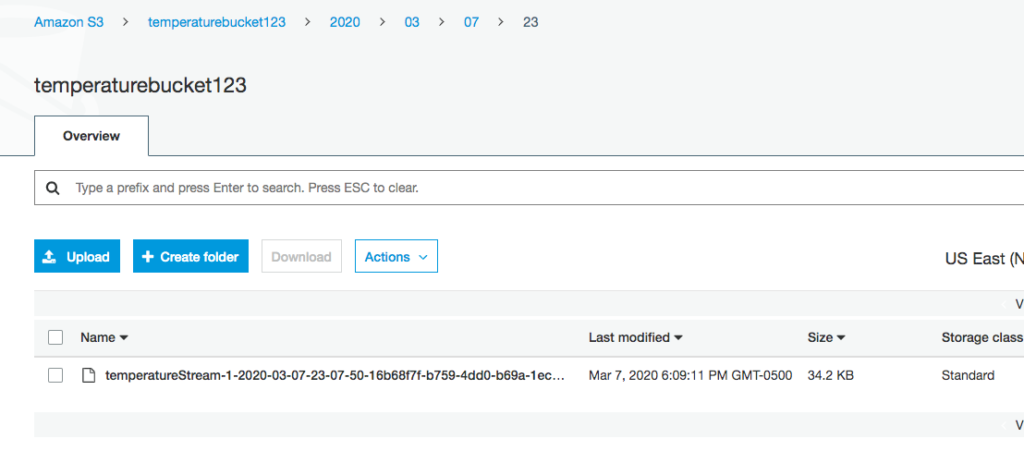
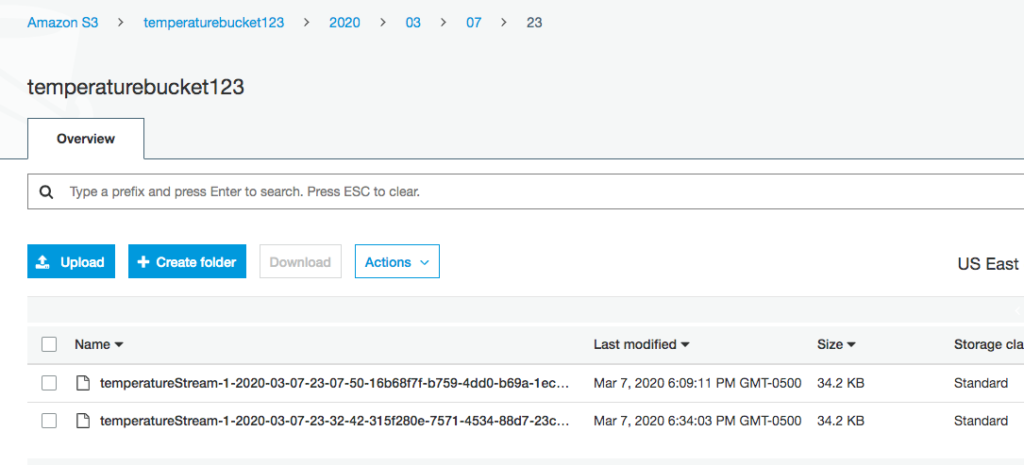
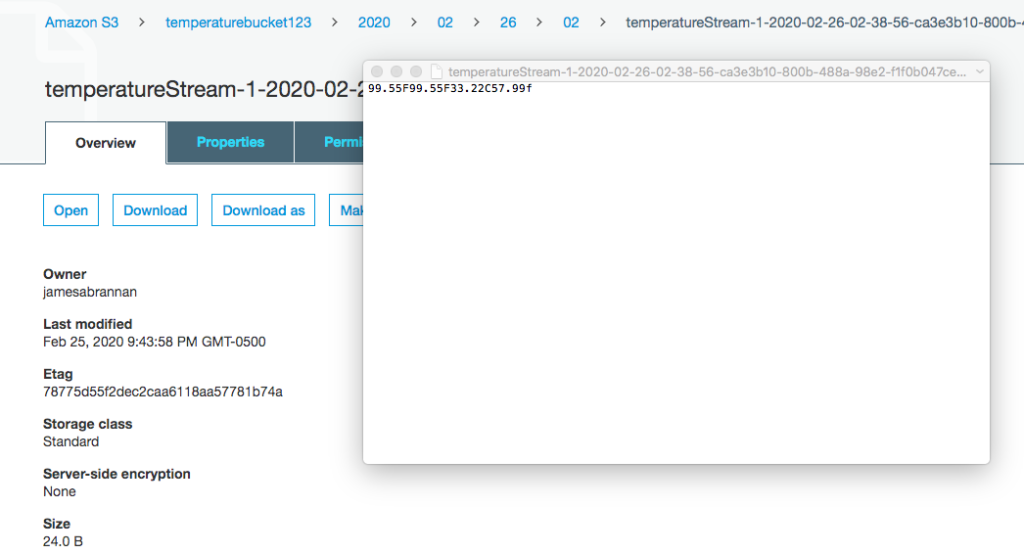
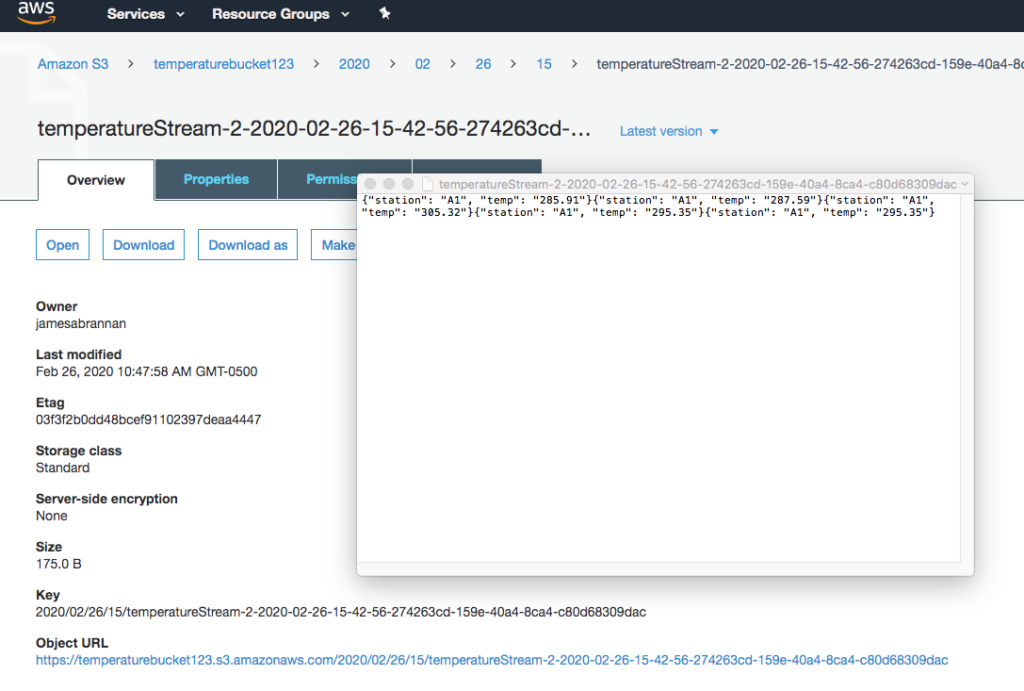
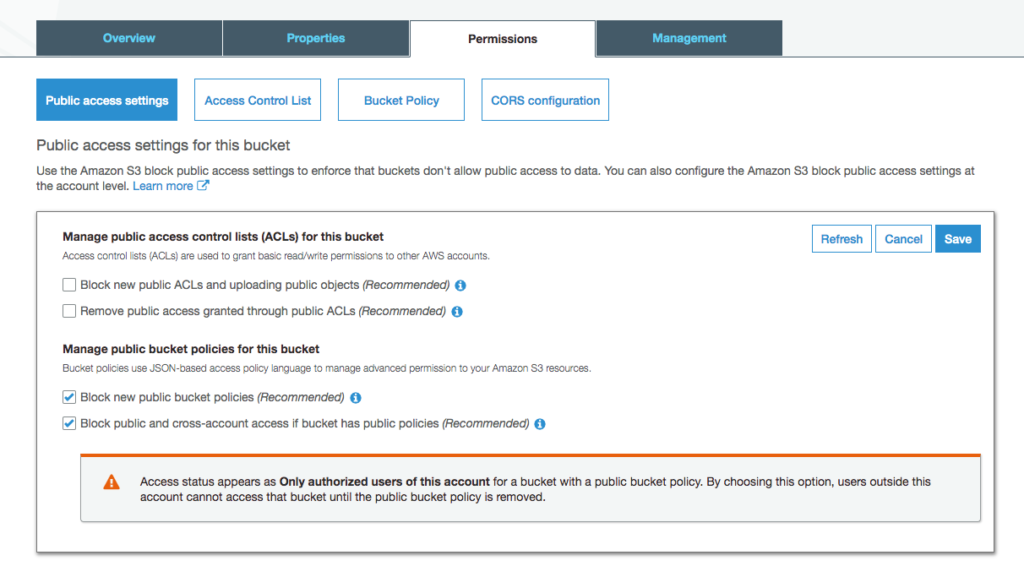
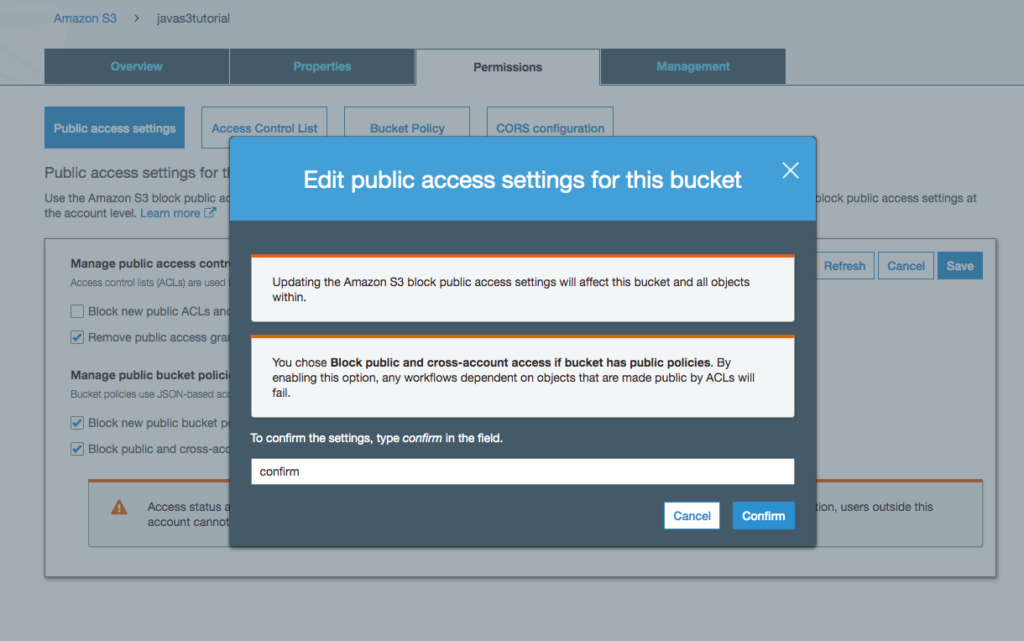
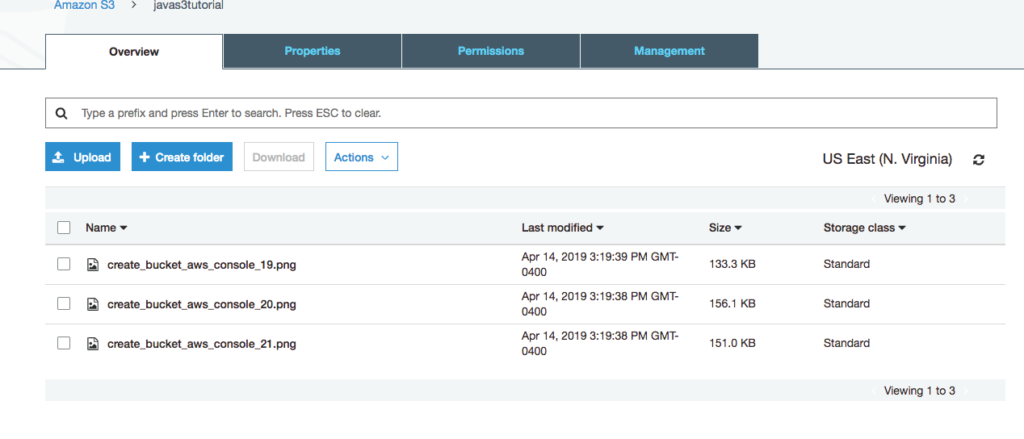
Navigate to the AWS Console and then to the S3 bucket.
Data created in S3
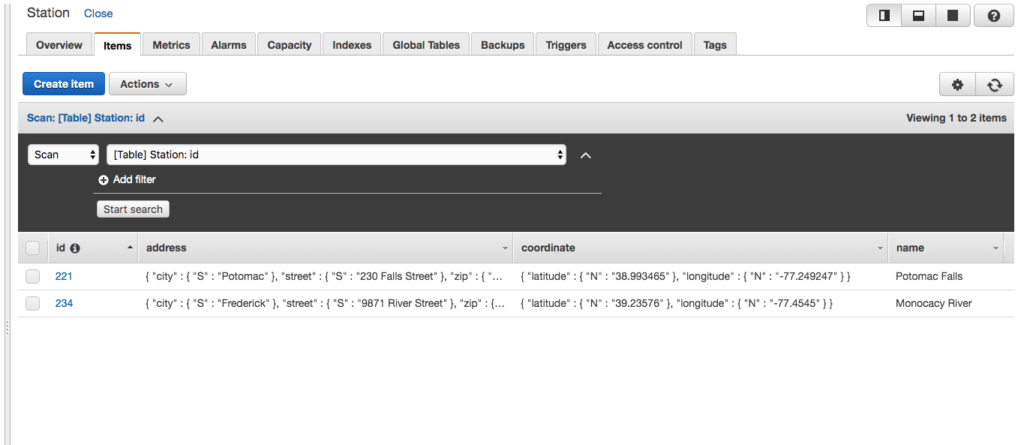
You should see the records written to the bucket.
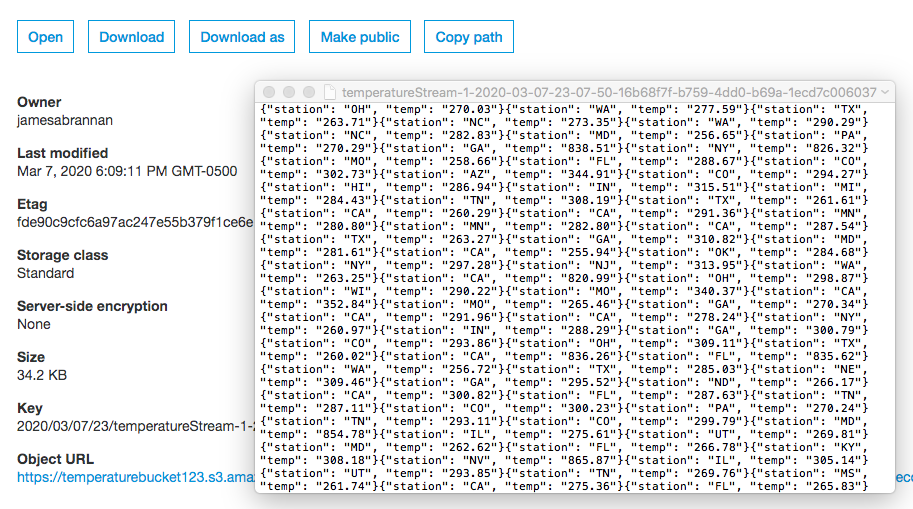
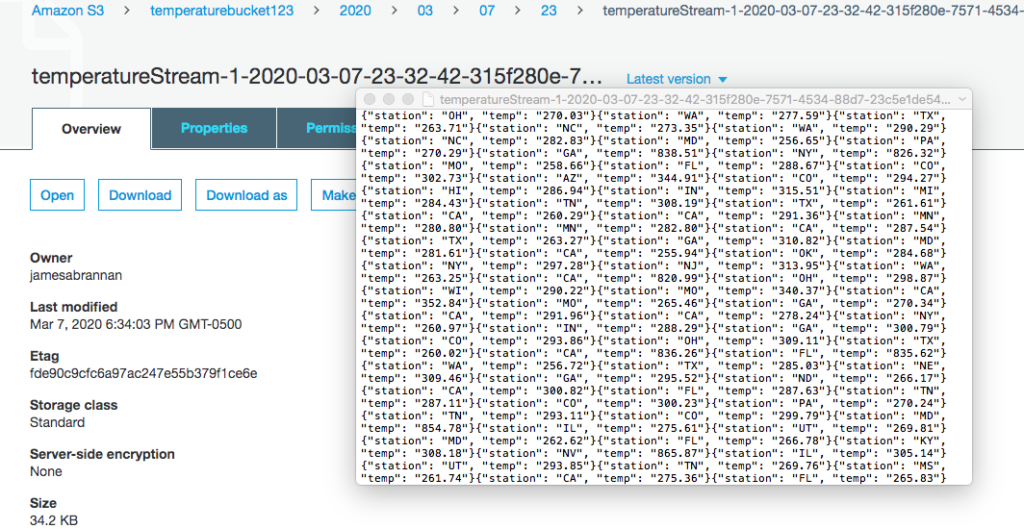
Open the file to ensure the records were transformed to kelvin.
Data converted to kelvin in S3
Batch Writing Records (put_record_batch)
Writing records individually are sufficient if your client generates data in rapid succession. However, you can also batch data to write at once to Firehose using the put-record-batch method.
Replace the code with the following code.
import json
import boto3
session = boto3.Session(profile_name='default')
temperatureClient = session.client('firehose')
records = []
with open("sampleTempDataForTutorial.json") as json_file:
observations = json.load(json_file)
count = 1
for observation in observations:
if count % 500 == 0:
response = temperatureClient.put_record_batch(
DeliveryStreamName='temperatureStream',
Records= records
)
print(response)
print(len(records))
records.clear()
record = {
"Data": json.dumps(observation)
}
records.append(record)
count = count + 1
if len(records) > 0:
print(len(records))
response = temperatureClient.put_record_batch(
DeliveryStreamName='temperatureStream',
Records= records
)
print(response)
In the preceding code you create a list named records. You also define a counter named count and initialize it to one. The code loops through the observations. Each observation is written to a record and the count is incremented. When the count is an increment of 500 the records are then written to Firehose. Note that Firehose allows a maximum batch size of 500 records. After looping through all observations, any remaining records are written to Firehose.
The data is written to Firehose using the put_record_batch method. Instead of writing one record, you write list of records to Firehose.
Before executing the code, add three more records to the Json data file.
Run the code and you should see output similar to the following in the Python Console.
Python Console output
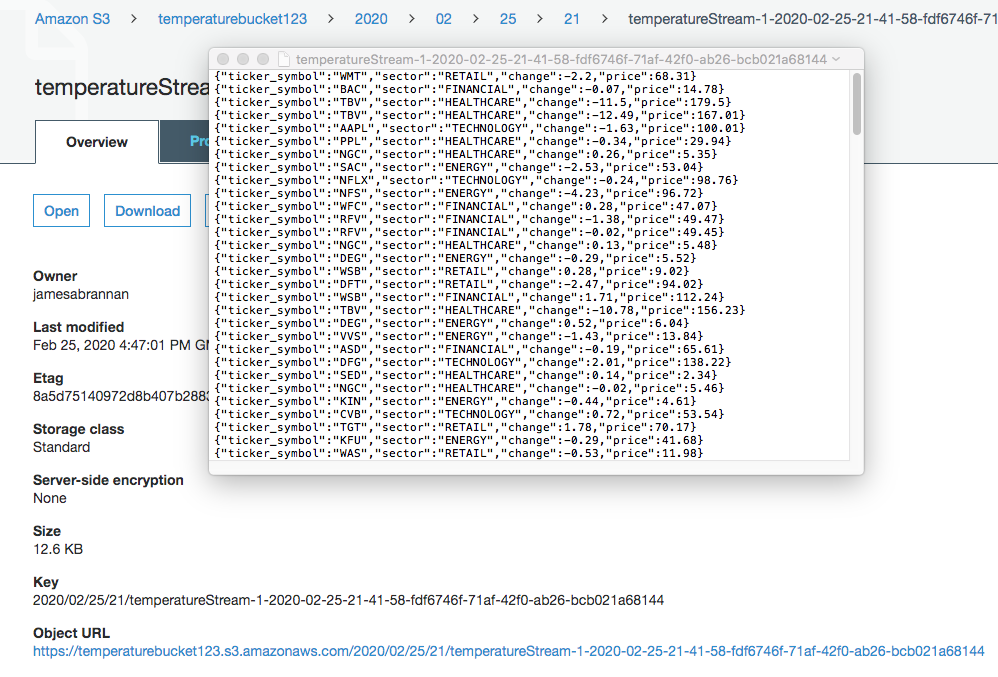
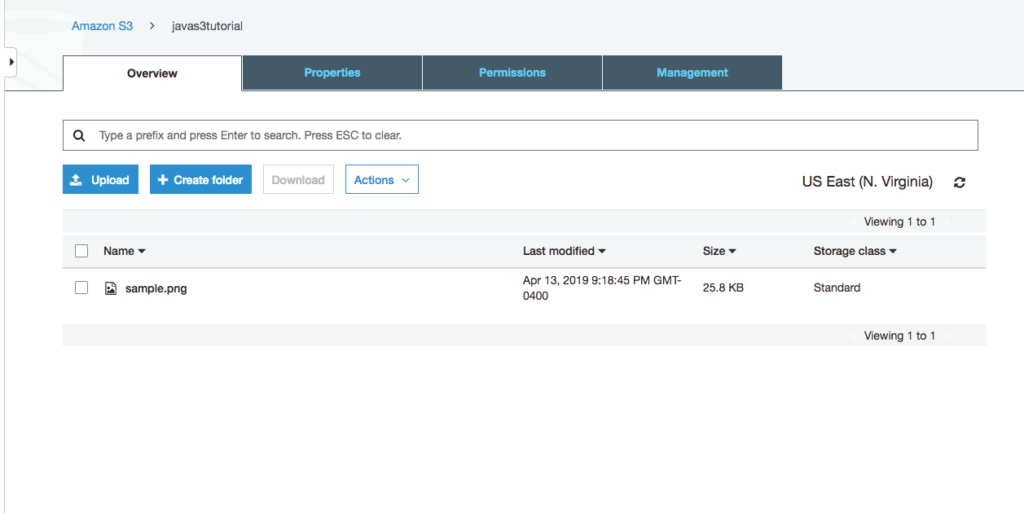
Navigate to the S3 bucket in the AWS Console and you should see the dataset written to the bucket.
Data written to S3 bucket
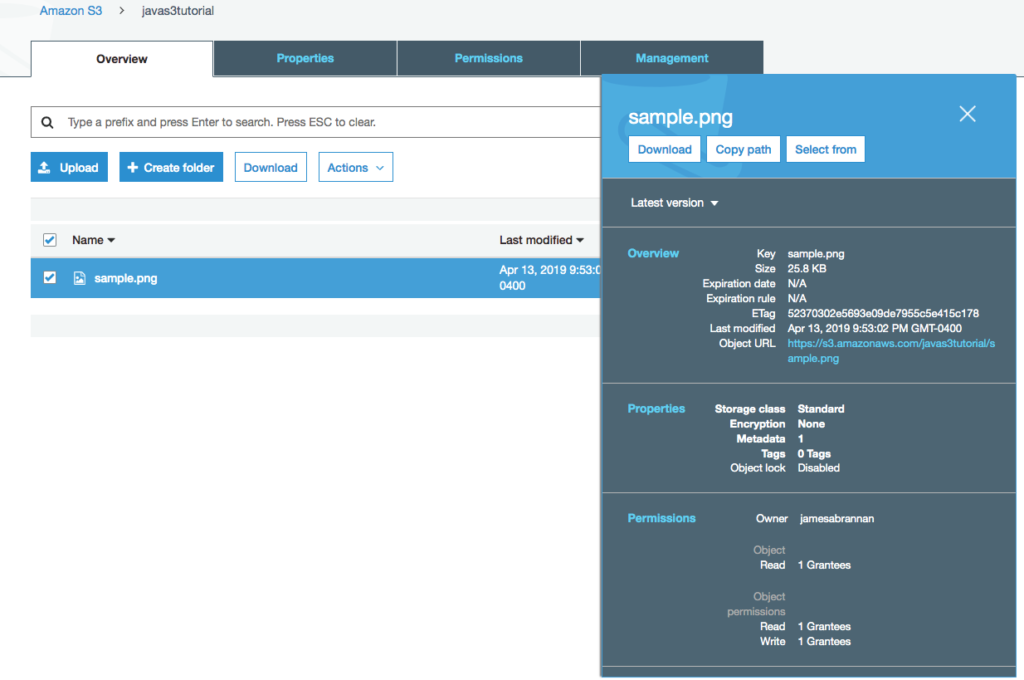
Open the records and ensure the data was converted to kelvin.
Data converted to kelvin in S3 bucket
Summary
This tutorial was on sending data to Kinesis Firehose using Python. You wrote a simple python client that wrote records individually to Firehose. You then wrote a simple python client that batched the records and wrote the records as a batch to Firehose. Refer to the Python documentation for more information on both commands. In the next tutorial you will create a Kinesis Analytics Application to perform some analysis to the firehose data stream.
Warning – Kinesis Firehose Stream Lambda function tutorial could incur an excess cost. Unless you plan on performing the other tutorials, delete your AWS resources to avoid incurring a cost.
This tutorial was tested on OS-X and Windows 10.
In this tutorial you create a semi-realistic example of using AWS Kinesis Firehose. You also create a Kinesis Firehose Stream Lambda function using the AWS Toolkit for Pycharm to create a Lambda transformation function that is deployed to AWS CloudFormation using a Serverless Application Model (SAM) template. After that, you then create the Kinesis Firehose stream and attach the lambda function to the stream to transform the data.
Introduction
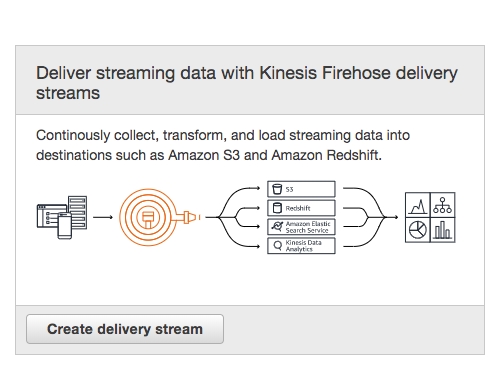
Amazon Web Services Kinesis Firehose is a service offered by Amazon for streaming large amounts of data in near real-time. Streaming data is continuously generated data that can be originated by many sources and can be sent simultaneously and in small payloads. Logs, Internet of Things (IoT) devices, and stock market data are three obvious data stream examples. Kinesis Streams Firehose manages scaling for you transparently. Firehose allows you to load streaming data into Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, and Splunk. You can also transform the data using a Lambda function. Firehose also allows easy encryption of data and compressing the data so that data is secure and takes less space. For more information, refer to Amazon’s introduction to Kinesis Firehose.
If you prefer watching a video introduction, the following is a good Kinesis Firehose overview.
AWS Introduction to Kinesis Firehose
Other Tutorials
Although this tutorial stands alone, you might wish to view some more straight-forward tutorials on Kinesis Firehose before continuing with this tutorial. Here we add complexity by using Pycharm and an AWS Serverless Application Model (SAM) template to deploy a Lambda function.
The following is a good video demonstration of using Kinesis Firehose by Arpan Solanki. The example project focuses on the out of the box functionality of Kinesis Firehose and will make this tutorial easier to understand.
AWS Kinesis Firehose demo by Arpan Solanki
Tasks Performed Here
In this tutorial you add more complexity to the more straightforward demonstrations on using Kinesis Firehose. Rather than creating the Lambda function while creating the Kinesis Stream, you create a more realistic Lambda function using Pycharm. Moreover, you deploy that function using an AWS Serverless Application Model (SAM) template. We will perform the following tasks in this tutorial.
Create and test a Kinesis Firehose stream.
Create a Lambda function that applies a transformation to the stream data.
Deploy the Lambda function using a Serverless Application Model (SAM) template.
Modify the Kinesis Firehose stream to use the Lambda data transformer.
Test the Kinesis Firehose stream.
Trace and fix an error in the Lambda function.
Redeploy the Lambda function.
Test the Kinesis Firehose stream
Sample Project Architecture
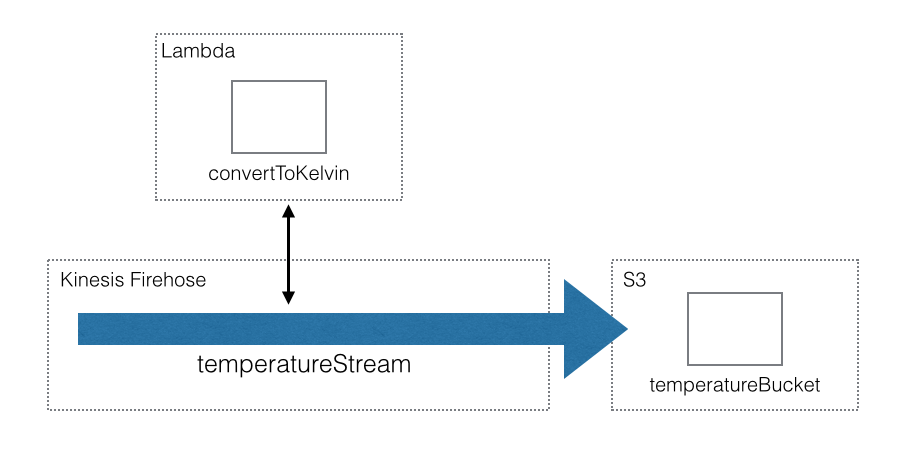
Assume we have many locations that record the ambient temperature. We need to aggregate this data from the many different locations in almost real-time. We decide to use AWS Kinesis Firehose to stream data to an S3 bucket for further back-end processing.
Data is recorded as either fahrenheit or celsius depending upon the location sending the data. But the back-end needs the data standardized as kelvin. To transform data in a Kinesis Firehose stream we use a Lambda transform function. The following illustrates the application’s architecture.
Tutorial application architecture
Prerequisites
This tutorial expects you to have an AWS developer account and knowledge of the AWS console. You should have PyCharm with the AWS Toolkit installed and the AWS CLI also installed.
This tutorial requires a rudimentary knowledge of S3, CloudFormation and SAM templates, Lambda functions, and of course, Python. The following links should help if you are missing prerequisites.
Log in to the AWS Console and select Services and then Kinesis.
Click Get Started if first time visiting Kinesis.
Click Create delivery stream in the Firehose panel.
Create delivery stream option on Amazon Kinesis dashboard (if no defined streams)
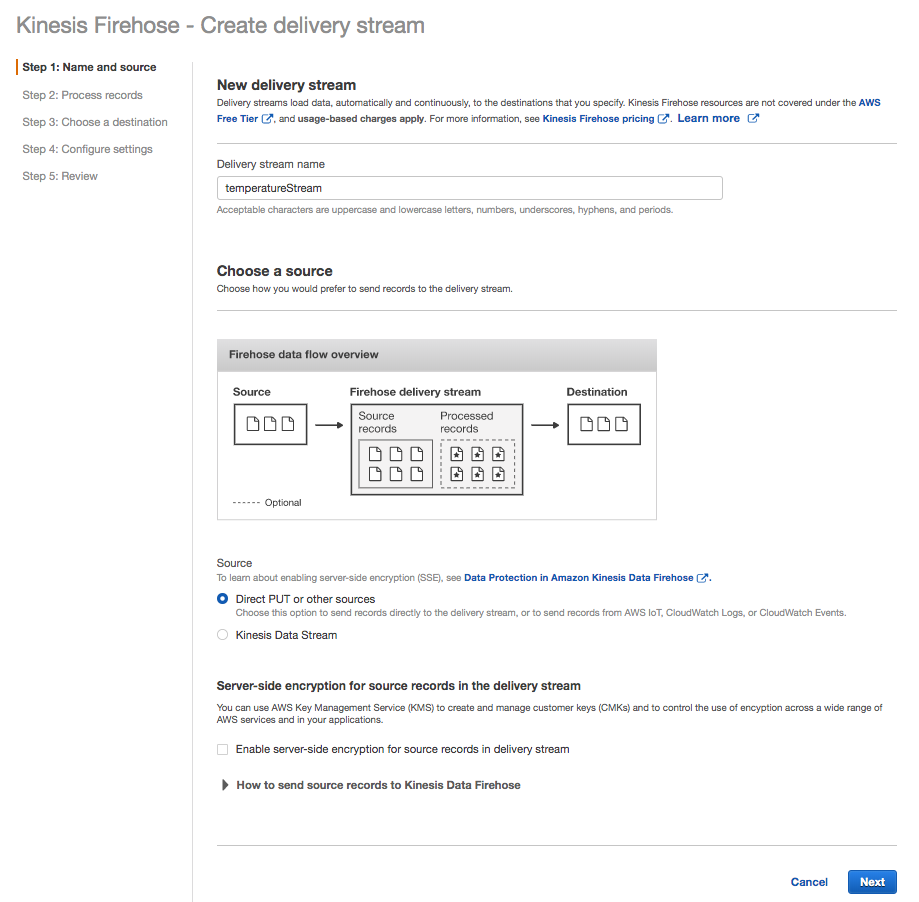
Name the Stream
Name the delivery stream temperatureStream.
Accept the default values for the remaining settings.
Click Next.
Create delivery stream – first step
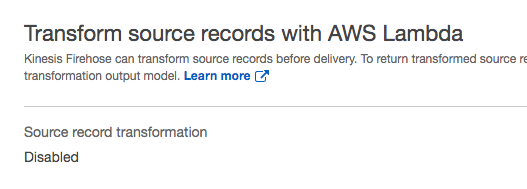
A data producer is any application that sends data records to Kinesis Firehose. By selecting Direct PUT or other sources you are allowing producers to write records directly to the stream.
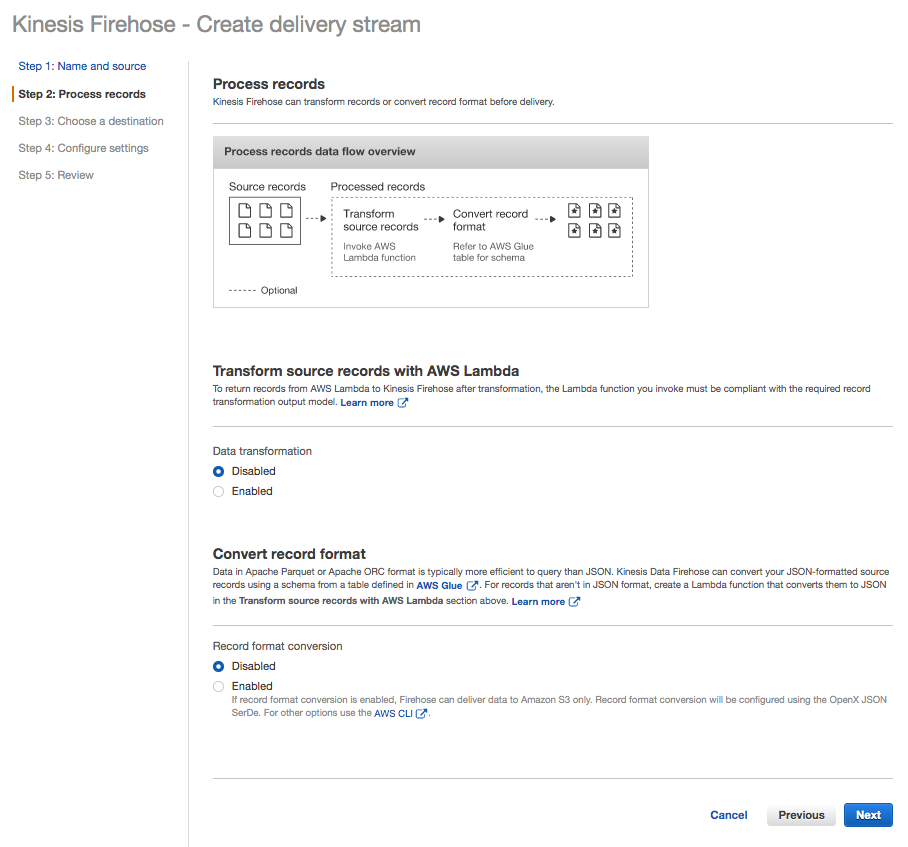
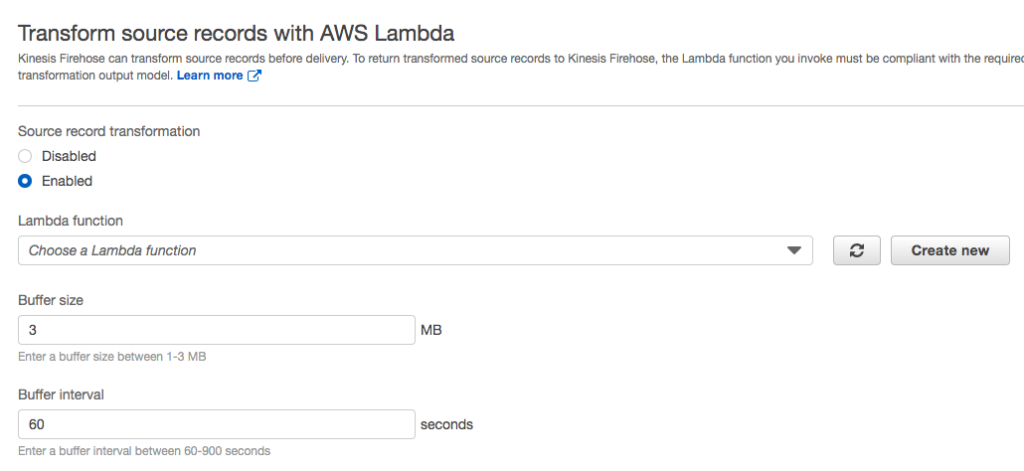
Accept the default setting of Disabled for Transform source records with AWS Lambda and Convert record format.
Click Next.
Create delivery stream – second step
The Transform source records with AWS Lambda allows you to define a Lambda function. Later in this tutorial you will change this setting and define a Lambda function. For now, leave it disabled.
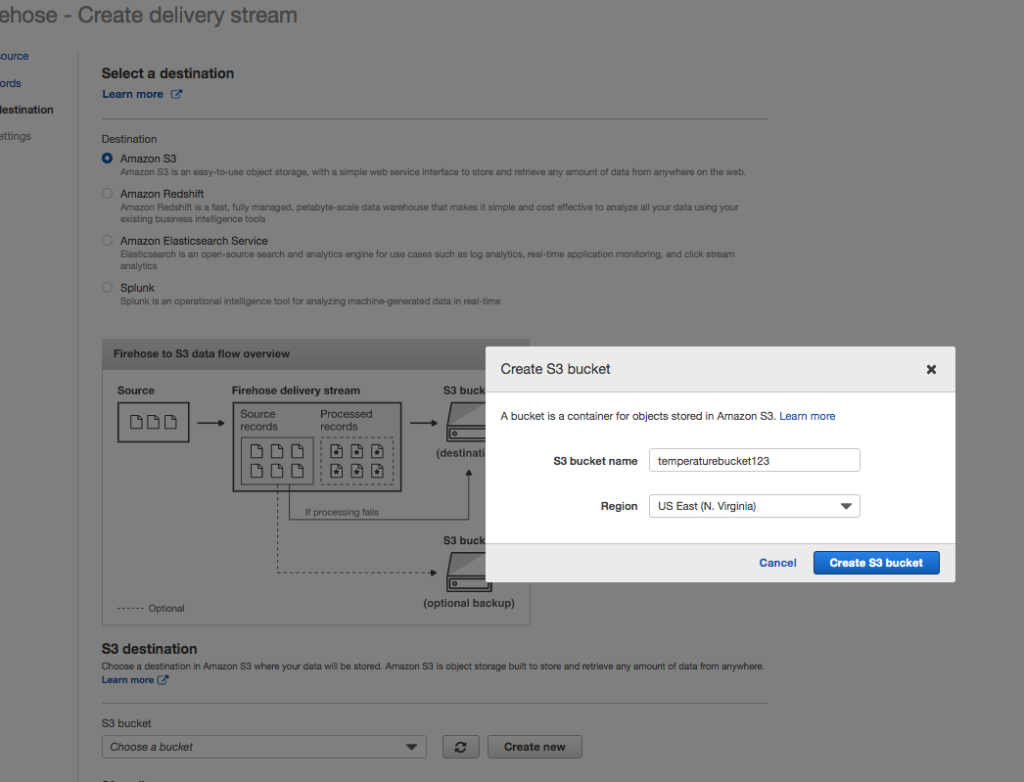
Configure S3 Bucket
Select Amazon S3 as the Destination.
Under the S3 destination, click Create new.
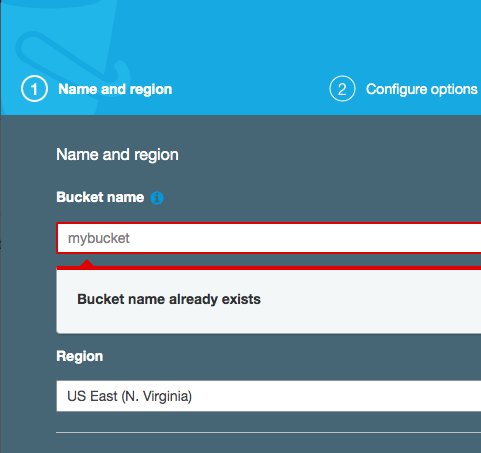
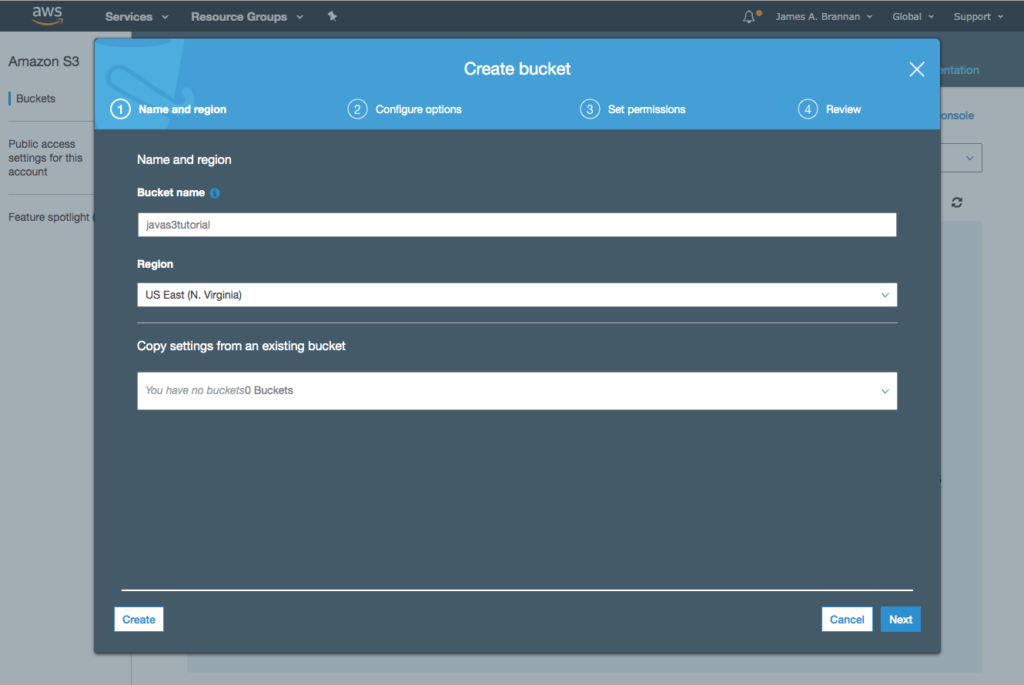
Name the S3 bucket with a reasonable name (remember all names must be globally unique in S3). Here I use the name temperaturebucket123 as the bucket name and select the appropriate Region.
Create S3 bucket for stream
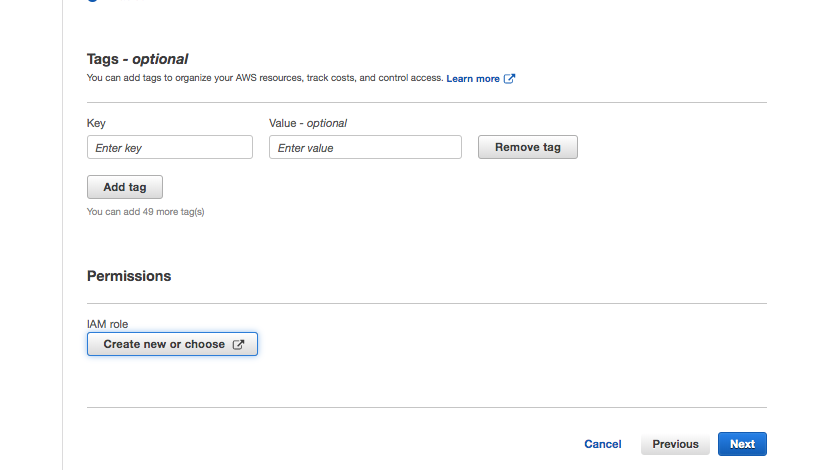
Configure Permissions
Click Next.
Accept the defaults and scroll to the Permissions section.
Click Create new or choose to associate an IAM role to the stream.
Create new or choose IAM role for stream
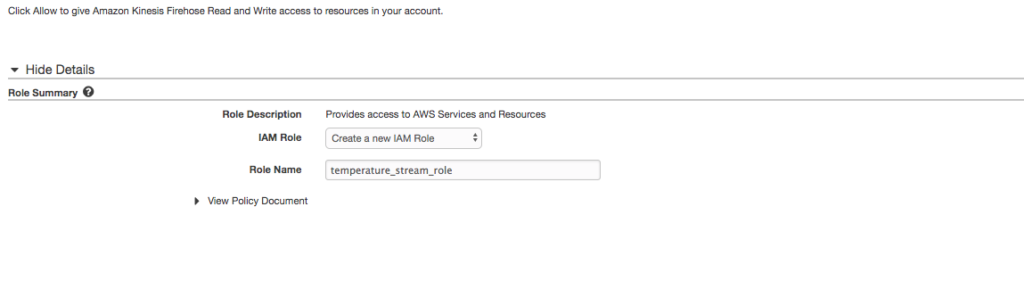
Create a role named temperature_stream_role (we return to this role in a moment) by accepting the defaults.
Click Allow.
Click Next after returned to the stream creation.
Create Role
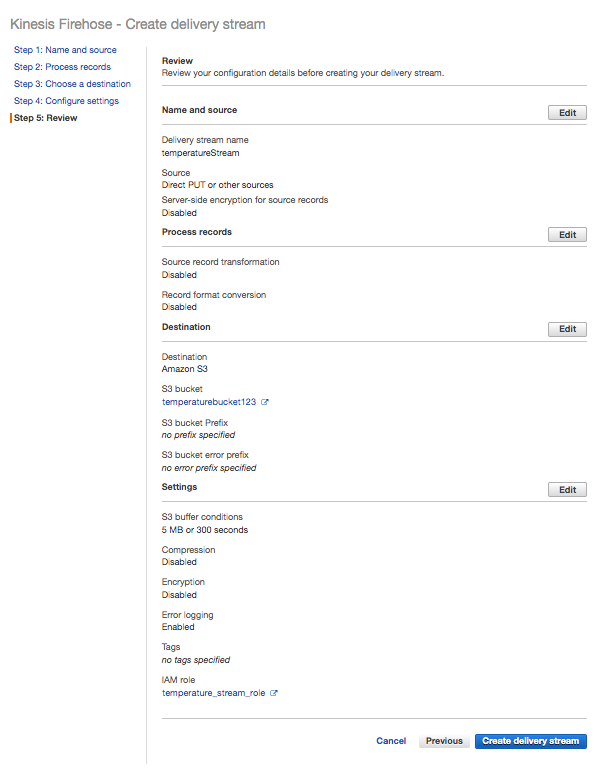
Review the delivery stream and click Create delivery stream to create the stream.
Select newly created role by clicking temperature_stream_role
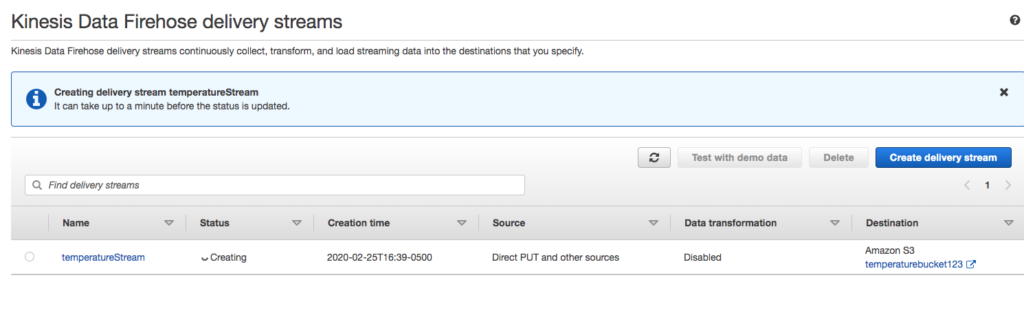
You should be taken to the list of streams and the Status of temperatureStream should be …Creating.
Delivery stream console after created.
After the stream’s status is Active, click on temperatureStream to be taken to the stream’s configuration page.
Click on the IAM role to return to the role settings in IAM.
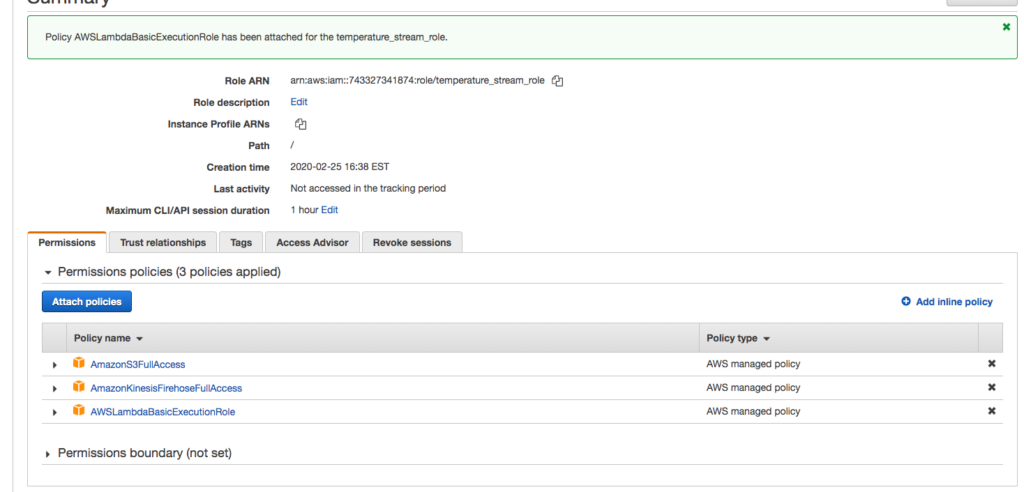
Now, we are being very lazy…you would not do this in production, but delete the attached policy and attach the AWSLambdaFullAccess, AmazonS3FullAccess, and AmazonKinesisFirehoseFullAccess roles.
Here we are granting the role too much access. In reality, you should grant the minimal access needed in a production setting.
For simplicity (not for production use), delete policy and add the following three policies to role
Test Stream
For a simple stream such as what you just developed AWS provides an easy means of testing your data. Let’s test your data before continuing development.
If not on the stream configuration screen, select the stream on the Kinesis dashboard to navigate to the stream’s configuration screen.
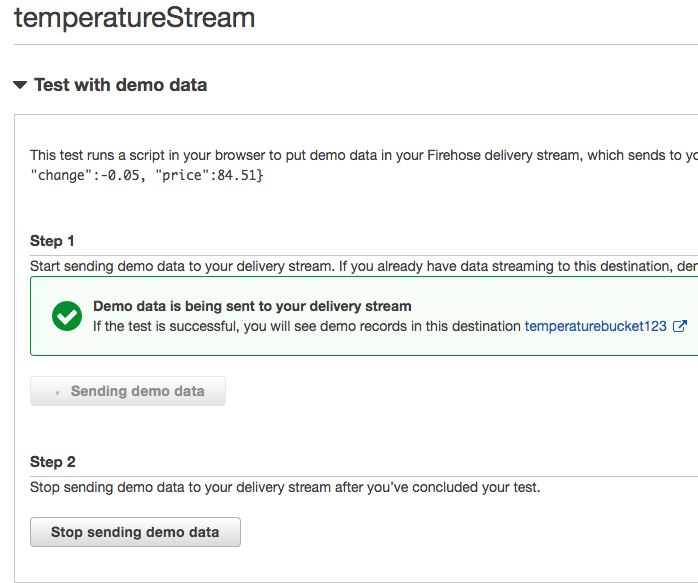
Expand the Test with demo data section.
Click the Start sending demo data button.
Wait about a minute and click the Stop sending demo data button.
Test data option on stream summary on AWS console
From the Amazon S3 destination section click on the bucket name to navigate to the S3 bucket. Be certain to wait five minutes to give the data time to stream to the S3 bucket.
If you tire of waiting five minutes, return to the stream’s configuration and change the buffer time to a smaller interval than 300 seconds.
The Buffer interval allows configuring the time frame for buffering data.S3 bucket link on stream summary on AWS console
Click on the sub-folders until taken to the data file. If you do not see the top level folder, then wait five minutes and refresh the page. Remember, the data is buffered.
S3 Bucket top level folder after test data written
Open the file and you should see the test records written to the file.
Test data written to S3 bucket by Kinesis Firehose
Navigate to the top level folder and delete the test data. Be certain you delete the top level folder and not the bucket itself.
Delete test data by deleting top level folder
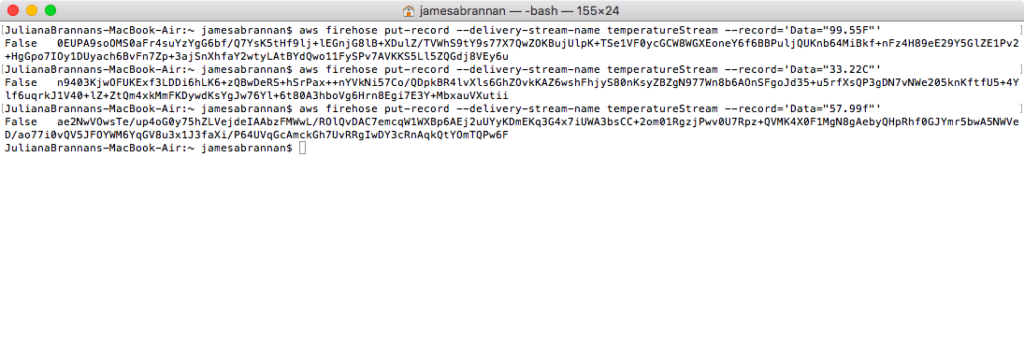
Open a command-line terminal on your computer and enter the following aws firehose put-record commands.
These commands worked with cli 1.18.11 on OS-X and they worked in Git-Bash on Windows 10. If you can get these working in Windows 10 command-line, please post in comments, as I wasted hours trying to send using cmd.
Return to the AWS Console and navigate to the S3 bucket and note the data was written to the bucket. Remember to allow the records time to process by waiting five minutes.
Rather than sending a simple string, modify the commands to send Json. Note that you escape the double-quotes.
See warning above regarding instability of cli accepted input.
Return to the AWS Console and you should see a file in the S3 bucket with data formatted as follows. Do not forget to give the record time to stream before checking the S3 bucket.
In the sample architecture note that the you need to convert the temperature data to kelvin. To accomplish this transformation you create a Lambda transform function for the Kinesis Firehose stream.
Lambda Function
Recall when creating the stream you were provided the option of transforming the data.
Transform source records option
Although you left this feature disabled, the requirements dictate that you need to modify temperature readings from fahrenheit or celsius to kelvin. Kinesis firehose provides an easy way to transform data using a Lambda function. If you referred to any of the linked tutorials above then you know that you can create and edit the Lambda function directly in the AWS console.
Here you develop the Lambda function in a local development environment, debug the function, and then deploy the function to AWS. Here you develop a Python Lambda function locally and deploy it to AWS using a CloudFormation SAM template.
PyCharm
Hopefully you have installed PyCharm and the AWS Toolkit. If not, do so now. Refer to the prerequisites above for information on installing both.
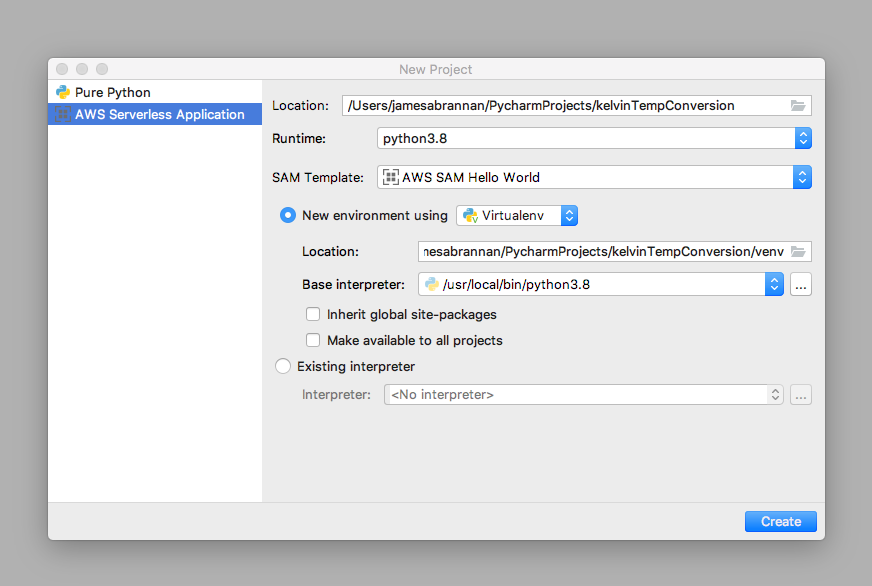
Start PyCharm.
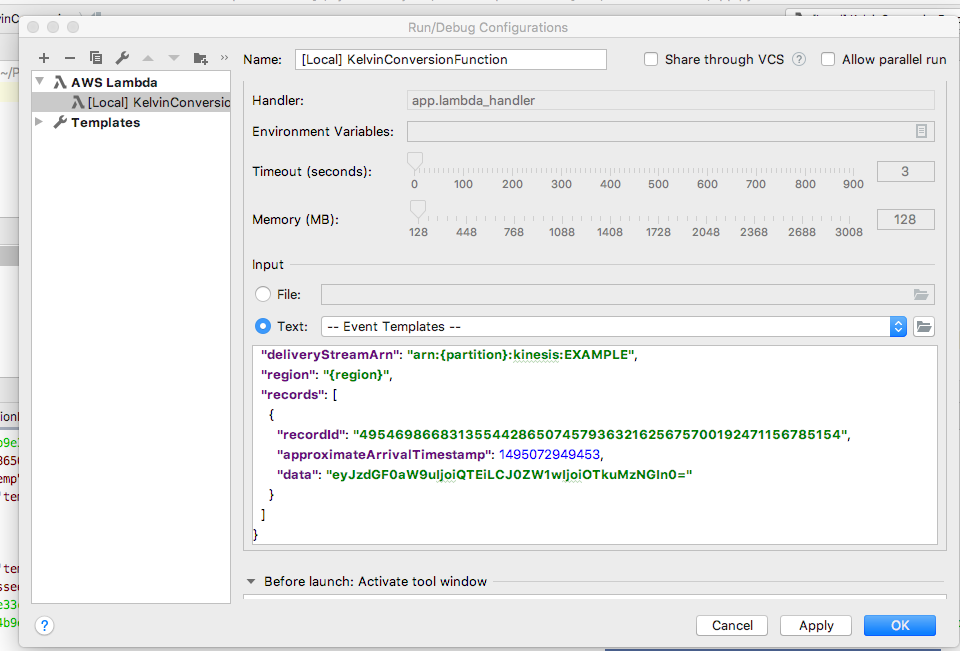
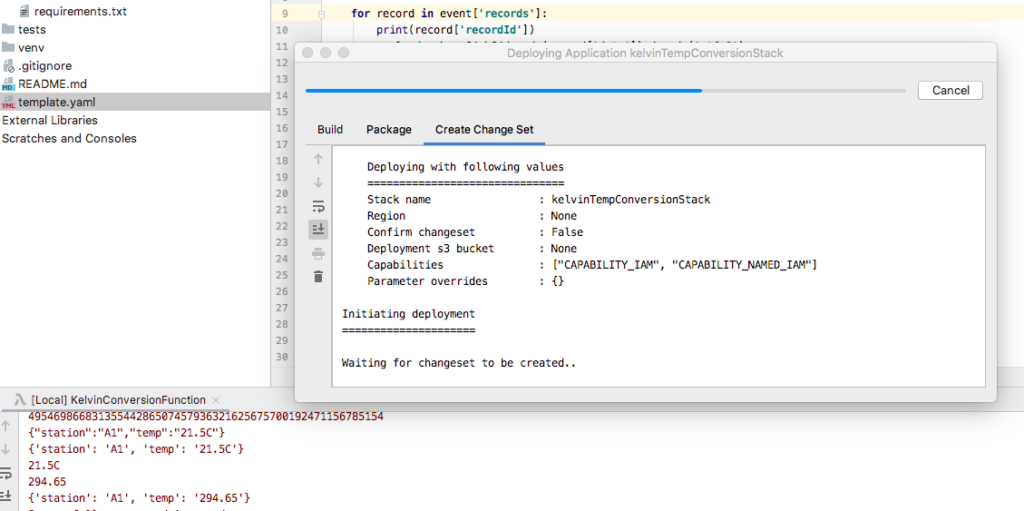
Create a new AWS Serverless Application named kelvinTempConversion.
Creating a new AWS SAM Project
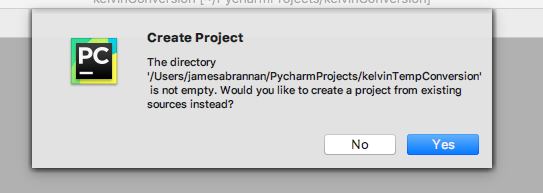
Click No if the following Create Project popup appears.
Select No to this dialog to create a project with new resources
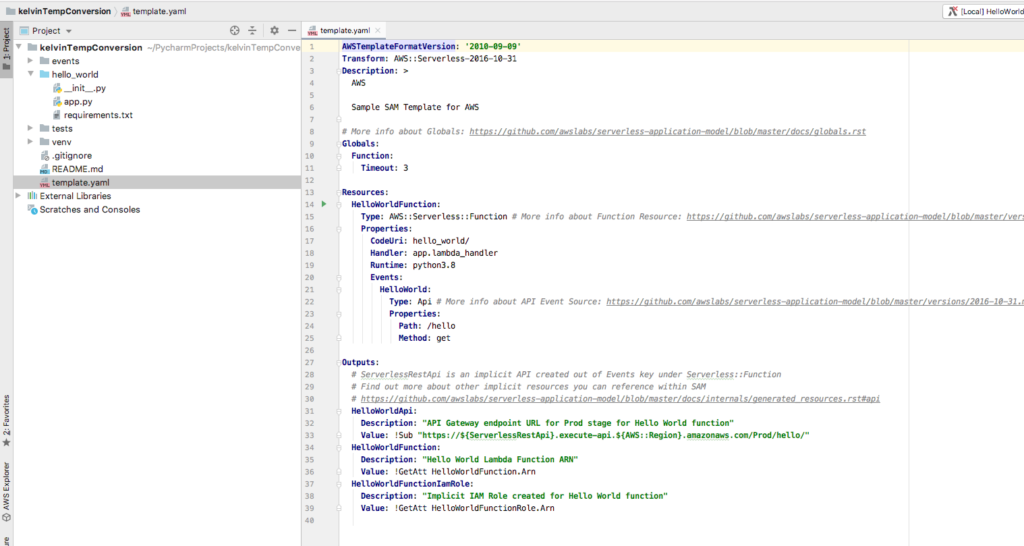
Open the template.yaml folder and notice the generated SAM template.
Modify the timeout from 3 to 60 seconds (Kinesis Firehose requires a 60 second timeout).
SAM template generated by PyCharm
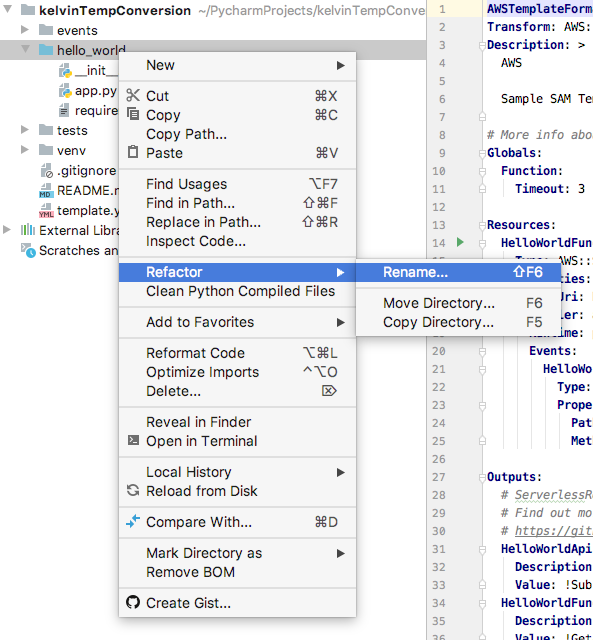
Right click the hello_world folder and select Refactor | Rename to rename the folder to kelvinConversion.
After reviewing the changes to be made, click the Do Refactor button.
Refactoring Hello World to kelvinConversion
Change all instances of HelloWorld with KelvinConversion in template.yaml.
Modify the function timeout (Globals:Function:Timeout:) to 60 seconds, the minimum for Kinesis Firehose.
Remove the Events section and the KelvinConversionApi section. These two sections are for building a public rest API. As we are developing a transformation function for our stream, neither is needed.
After modifying all instances of the hello world text, template.yaml should appear similar to the following.
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
AWS
Sample SAM Template for AWS
Globals:
Function:
Timeout: 60
Resources:
KelvinConversionFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: kelvinConversion/
Handler: app.lambda_handler
Runtime: python3.8
Outputs:
KelvinConversionFunction:
Description: "Kelvin Conversion Lambda Function ARN"
Value: !GetAtt KelvinConversionFunction.Arn
KelvinConversionFunctionIamRole:
Description: "Implicit IAM Role created for Kelvin Conversion function"
Value: !GetAtt KelvinConversionFunctionRole.Arn
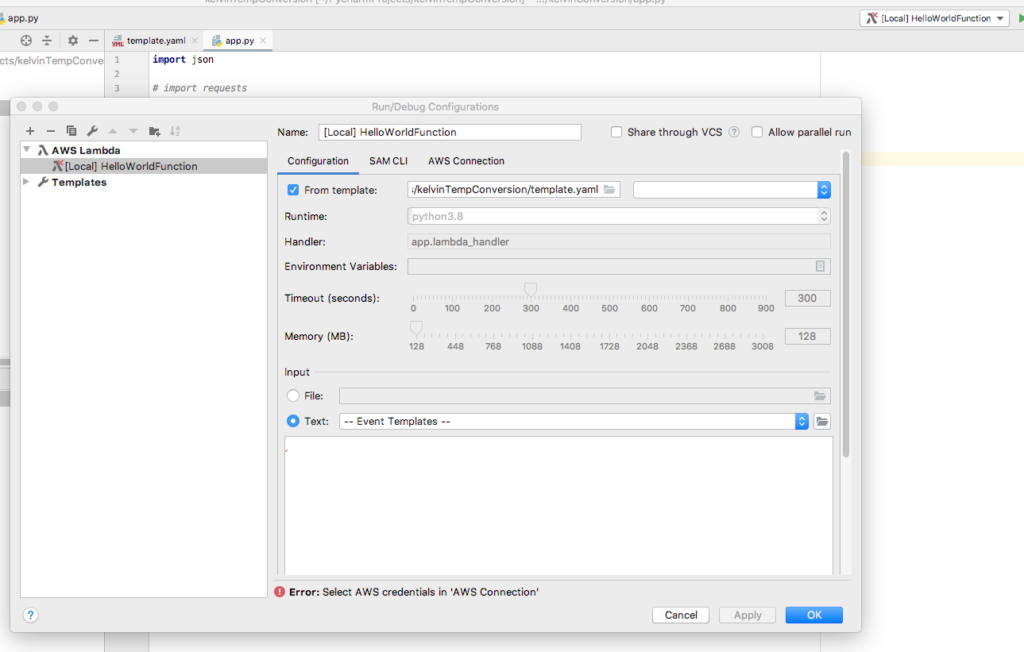
From the upper right drop down, select Edit Configurations.
Modify the template to reflect the new folder.
Click Ok.
Runtime configuration
Select the dropdown item and click the green arrow to run the application.
/usr/local/bin/sam local invoke --template /Users/jamesabrannan/PycharmProjects/kelvinTempConversion/.aws-sam/build/template.yaml --event "/private/var/folders/xr/j9kyhs2n3gqcc0n1mct4g3lr0000gp/T/[Local] KelvinConversionFunction-event.json" KelvinConversionFunction
Invoking app.lambda_handler (python3.8)
Fetching lambci/lambda:python3.8 Docker container image......
Mounting /Users/jamesabrannan/PycharmProjects/kelvinTempConversion/.aws-sam/build/KelvinConversionFunction as /var/task:ro,delegated inside runtime container
START RequestId: 1ffa20fa-486e-1827-e987-e92f16101778 Version: $LATEST
END RequestId: 1ffa20fa-486e-1827-e987-e92f16101778
REPORT RequestId: 1ffa20fa-486e-1827-e987-e92f16101778 Init Duration: 531.94 ms Duration: 14.75 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 24 MB
{"statusCode":200,"body":"{\"message\": \"hello world\"}"}
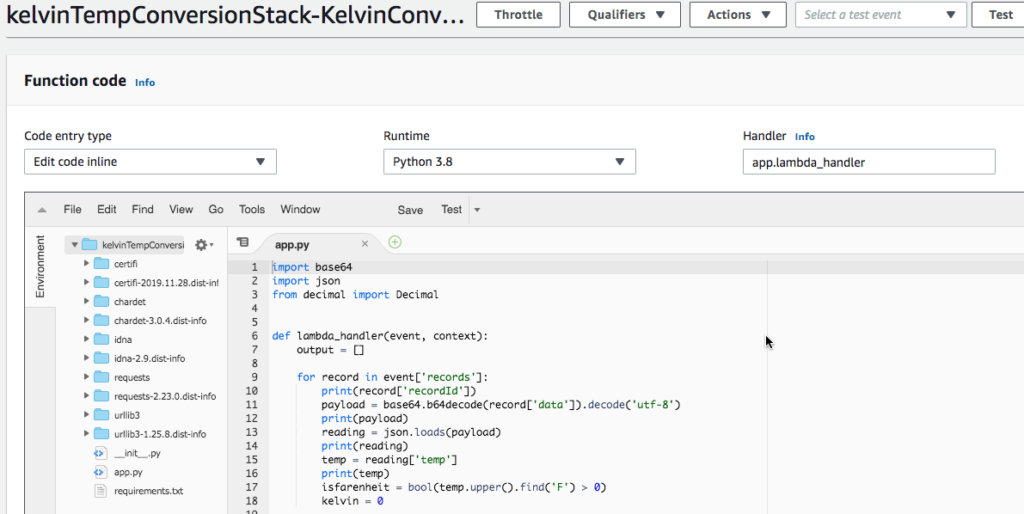
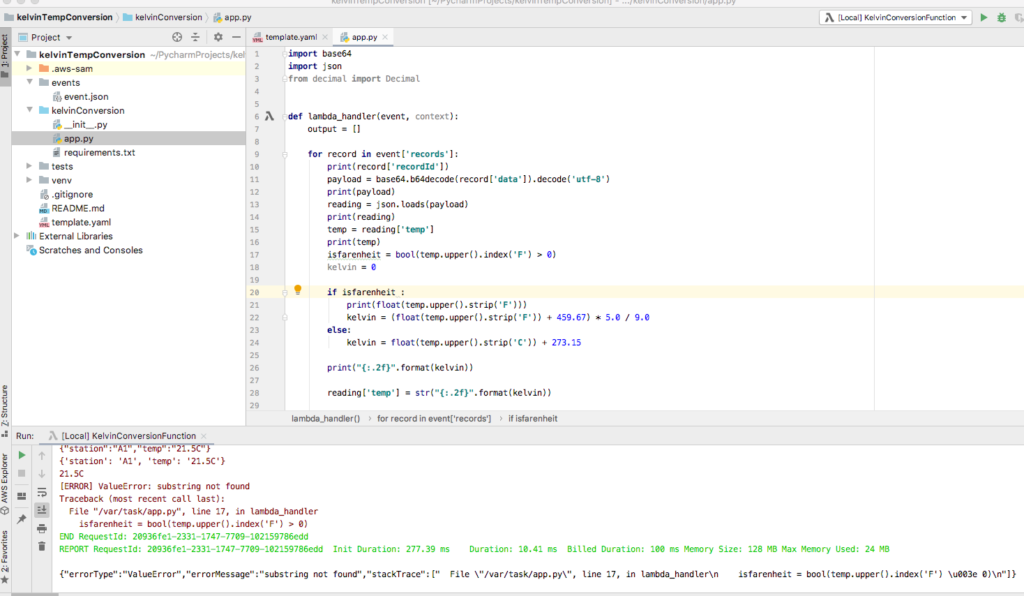
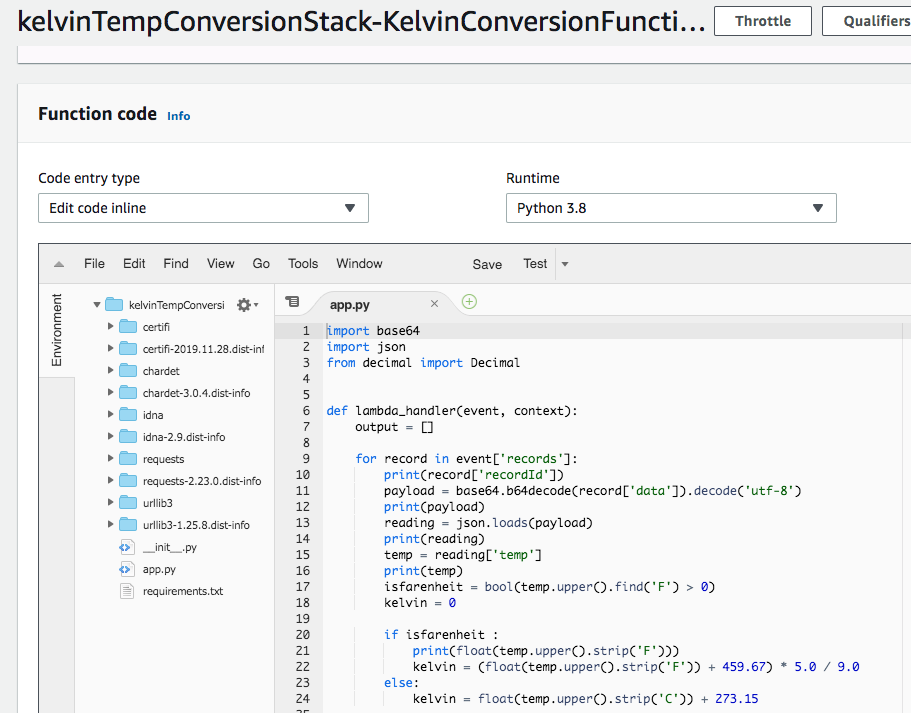
Now that you are assured the project is configured correctly and executes locally, open app.py and replace the sample code with the following. Note that the line using the index string function is in error. This error is by design and you will fix it later in the tutorial.
import base64
import json
from decimal import Decimal
def lambda_handler(event, context):
output = []
for record in event['records'] :
print(record['recordId'])
payload = base64.b64decode(record['data']).decode('utf-8')
print(payload)
reading = json.loads(payload)
print(reading)
temp = reading['temp']
print(temp)
# note: this is in error, if celcius this causes error
# this is fixed later in tutorial
isfarenheit = bool(temp.upper().index('F') > 0)
kelvin = 0
if isfarenheit:
print(float(temp.upper().strip('F')))
kelvin = (float(temp.upper().strip('F')) + 459.67) * 5.0 / 9.0
else:
kelvin = float(temp.upper().strip('C')) + 273.15
print("{:.2f}".format(kelvin))
reading['temp'] = str("{:.2f}".format(kelvin))
print(reading)
output_record = {
'recordId': record['recordId'],
'result': 'Ok',
'data': base64.b64encode(json.dumps(reading).encode('UTF-8'))
}
output.append(output_record)
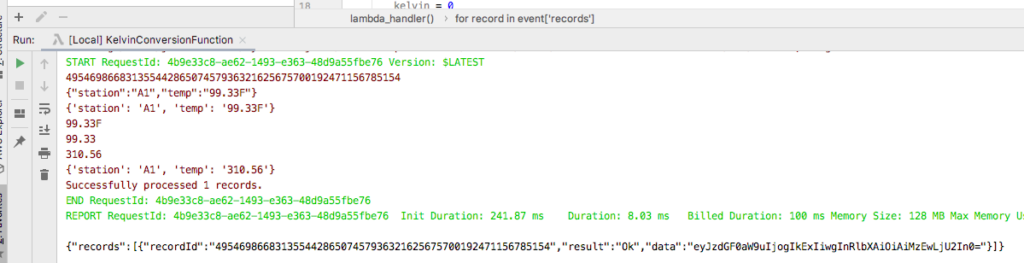
print('Processed {} records.'.format(len(event['records'])))
return {'records': output}
Local Testing
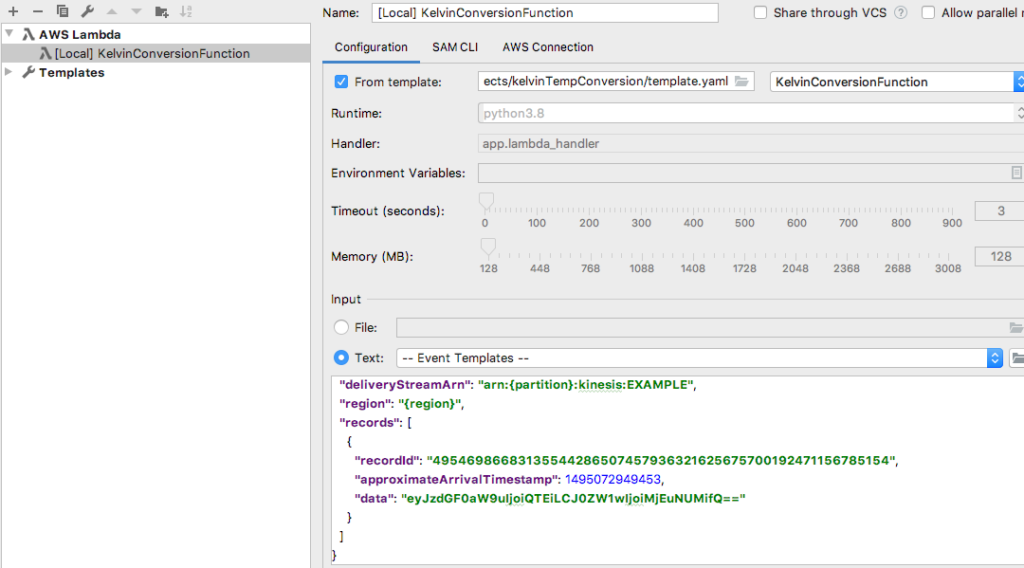
To test the record you need to use an event template. There are event types you can choose, depending upon how the Lambda function is to be used.
From Event Templates select Kinesis Firehose.
Select Kinesis Firehose template to generate test data
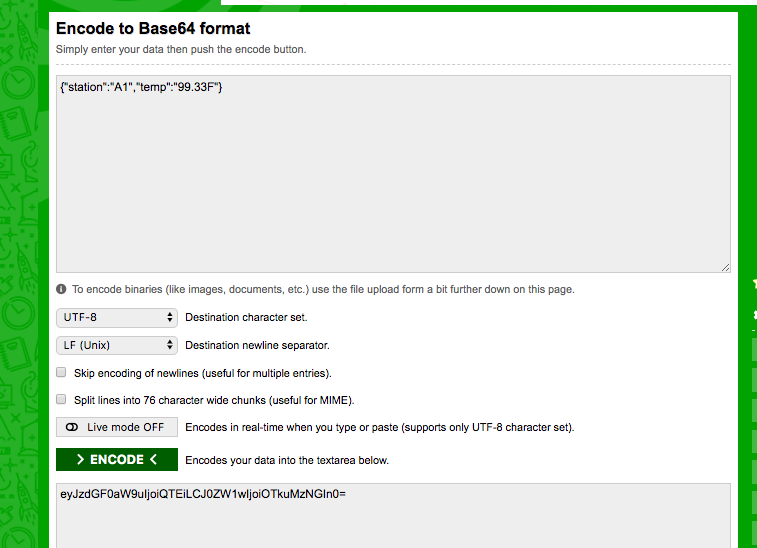
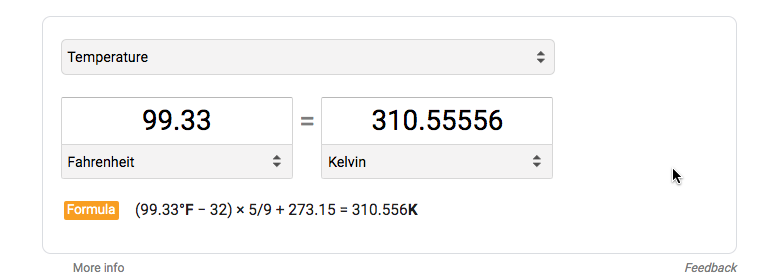
Create the sample record {“station”:”A1″,”temp”:”99.33F”} and base64 encode the record. A good site to encode and decode is the base64encode.org website.
Encoding a simple Json record to Base64
Replace the data string generated when you selected the Kinesis Firehose Event Template and replace it with the base64 encoded string.
Modify data value with the newly encoded value
Run the application locally and you should see the returned record.
Console output from running application locally
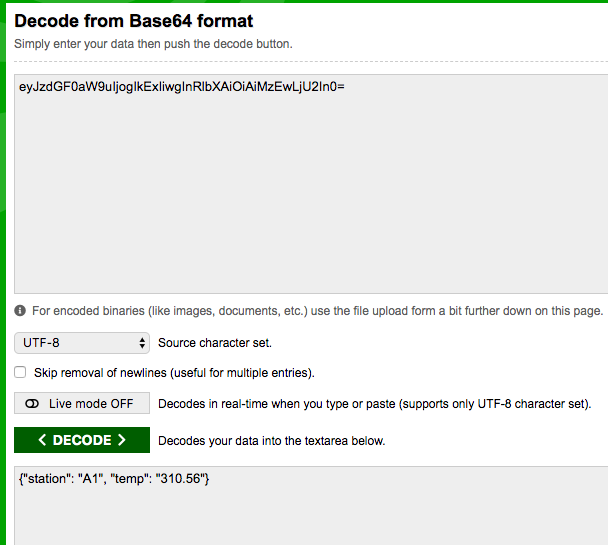
Copy the data string and decode the record from base64.
Decode result from Base64 to string
Validate the converted kelvin measurement is correct.
Note, you only tested fahrenheit. This is by design to illustrate debugging in the AWS Console. You fix this error later in this tutorial.
Deploying Serverless Application
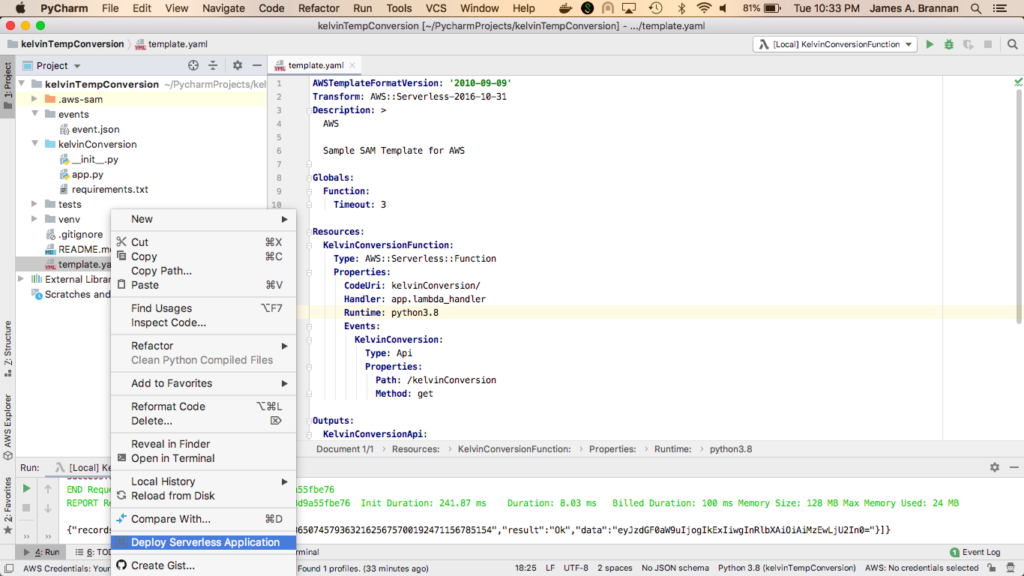
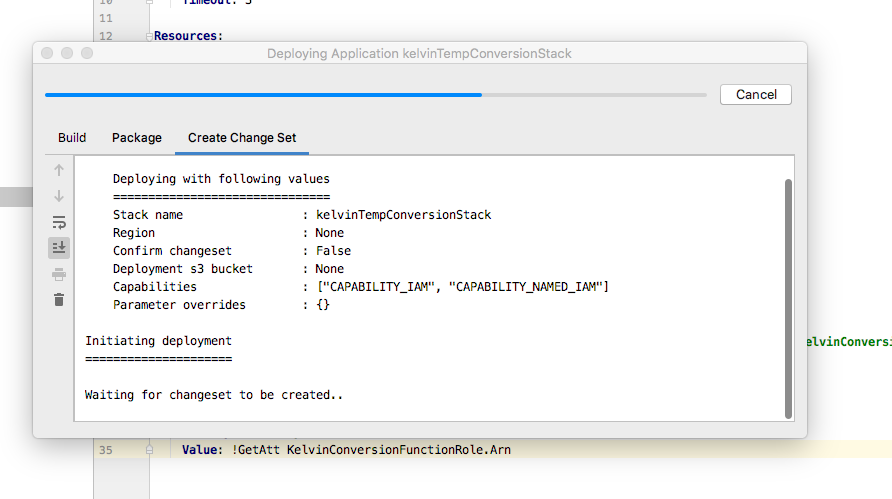
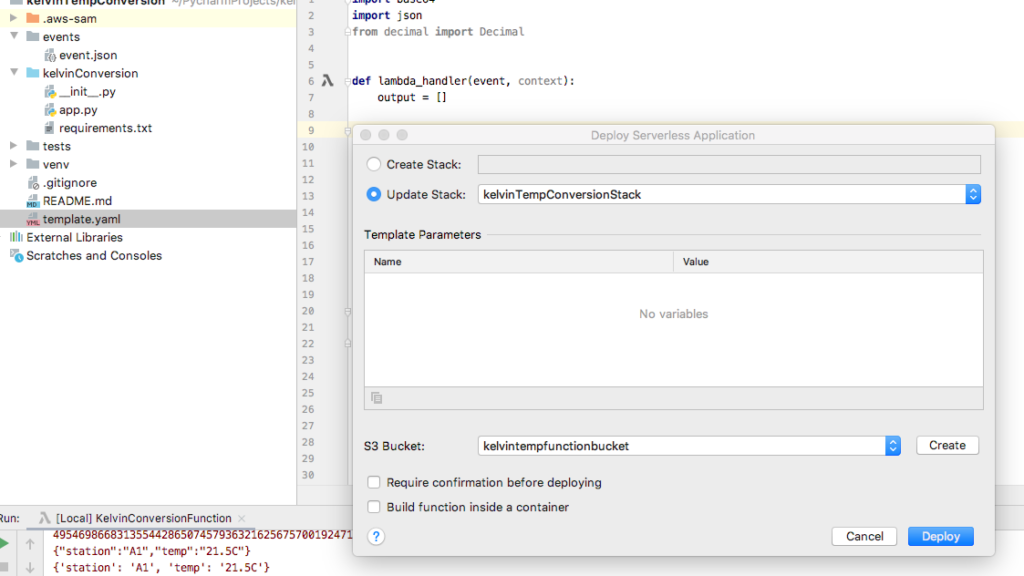
Right click on template.yaml and select Deploy Serverless Application from the popup menu.
Right click on template.yaml and select Deploy Serverless Application
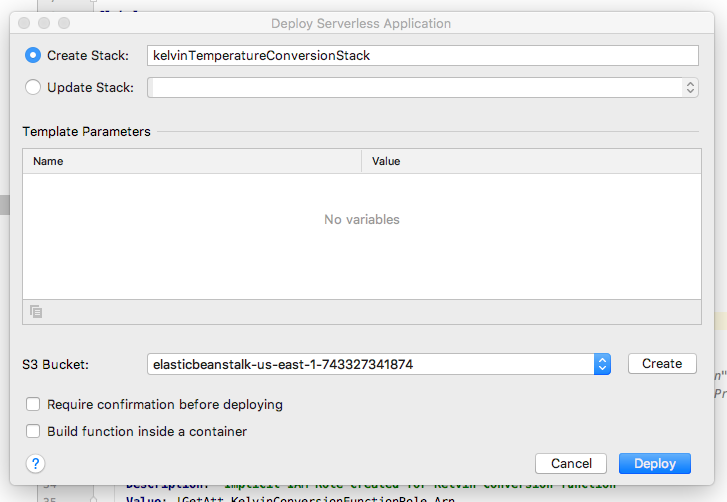
Select Create Stack and name the stack kelvinTemperatureConversionStack.
Select or create an S3 Bucket.
Click Deploy.
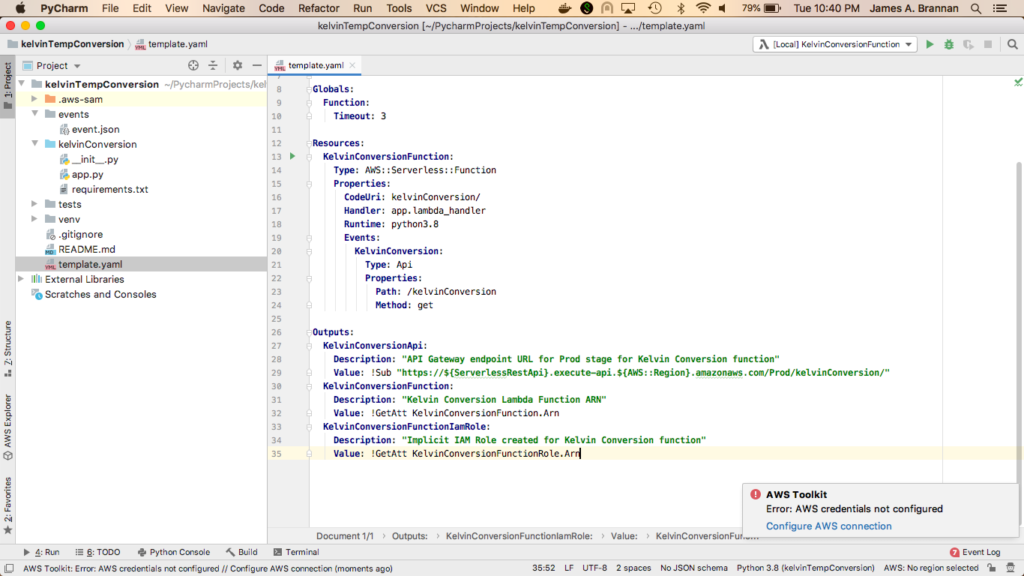
If you receive a credentials error, then you need to configure the AWS Toolkit correctly.
At the extreme lower right of the window, click the message telling you the issue.
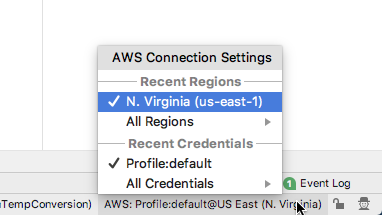
Error if AWS Toolkit credentials are not configured correctlyProfile settings configured for AWS Toolkit
After fixing credentials (if applicable) then try again. A dialog window should appear informing you of the deployment progress.
Notice that the window is using CLI Sam commands to deploy the function to AWS.
Navigate to the temperatureStream configuration page.
Click Edit.
Enable source record transformation in the Transform source records with AWS Lambda section.
Select the Lambda function created and deployed by PyCharm.
Click Save.
Testing Kinesis Firehose Stream Using CLI
Open a command-line window and send several records to the stream. Be certain to escape the double-quotes, with the exception of the double quotes surrounding the data record.
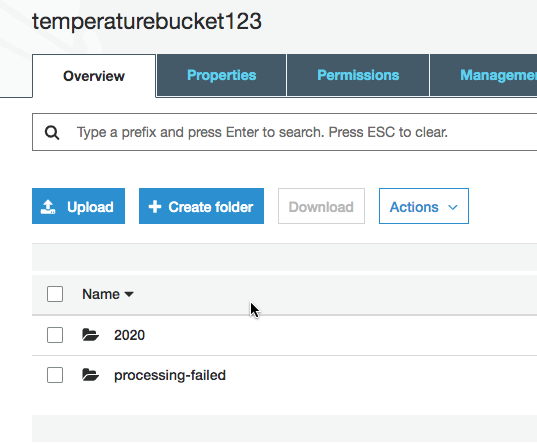
After waiting five minutes, navigate to the S3 bucket and you should see a new folder entitled processing-failed.
Processing-failed folder when Kinesis Firehose fails
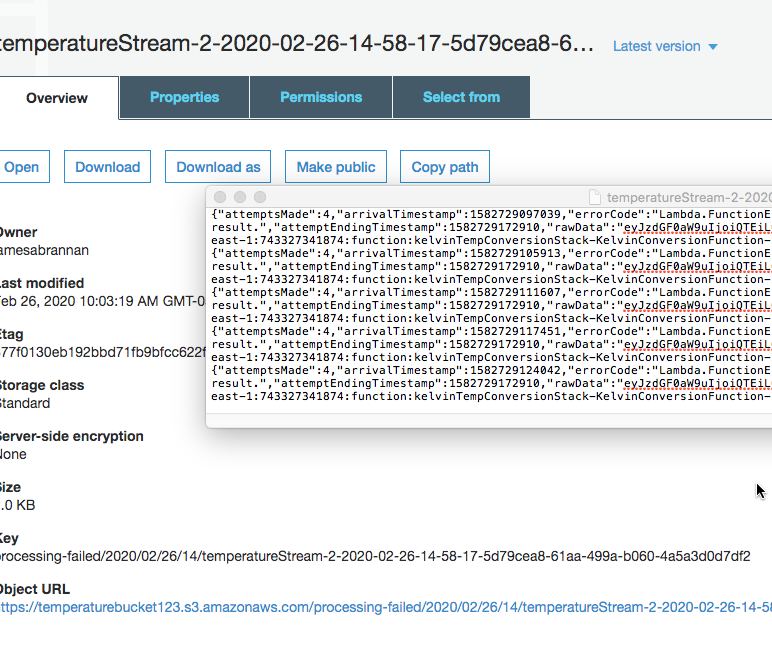
Navigate down the processing-failed folder hierarchy and open the failure records.
Errors written to S3 Bucket
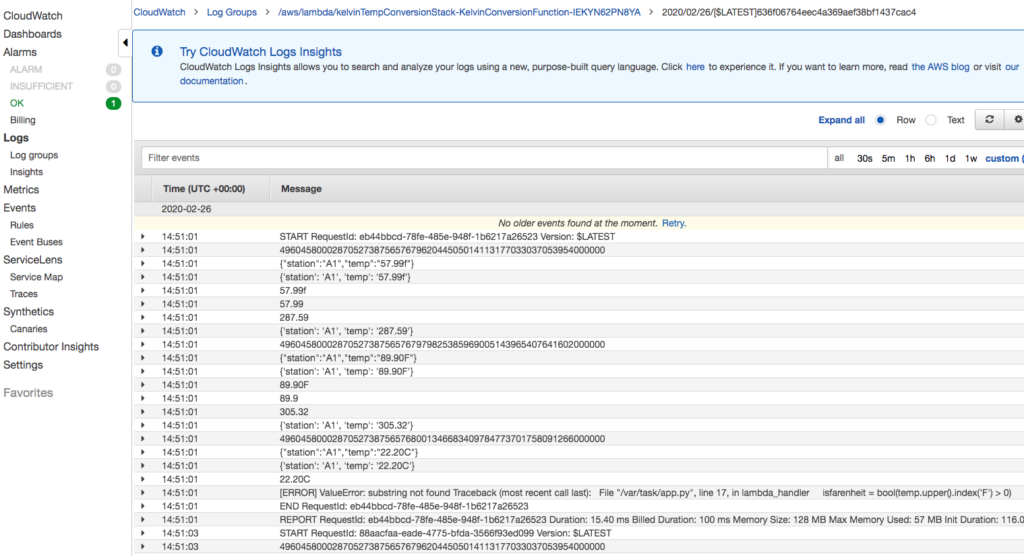
The error messages are not very informative. But at least they tell you the Lambda function processing caused the error.
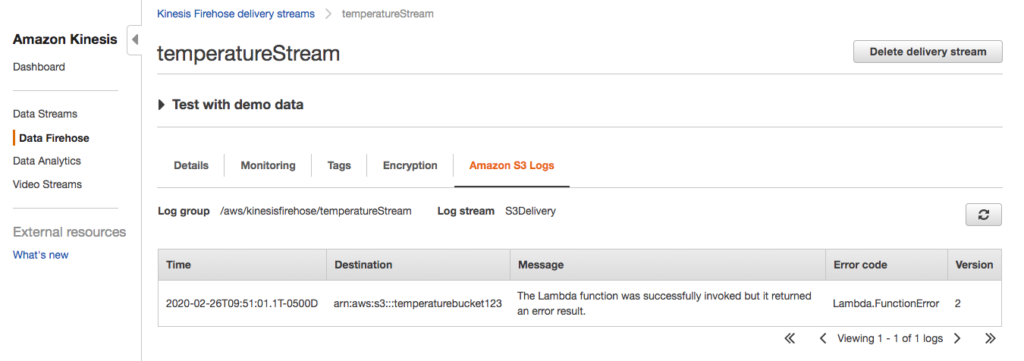
Navigate to the stream and select Amazon S3 Logs.
The log message is also not very informative.
Navigate to the Lambda function details.
Select the LogStream from the most recent invocation of the Lambda function.
The detailed log records the exact cause of the error, the index function. Unlike some languages such as Java, the Python index function returns an error if the string is not found.
Fixing Error
Return to the PyCharm project to fix the error and redeploy the Lambda function to AWS.
You might notice that you can edit a function directly in the AWS Console. DO NOT EDIT! Remember, you deployed this application using SAM in CloudFormation. The correct process is to fix the function and then redeploy it using SAM.
Python implementation in the AWS ConsoleData replaced with celcius value after encoding
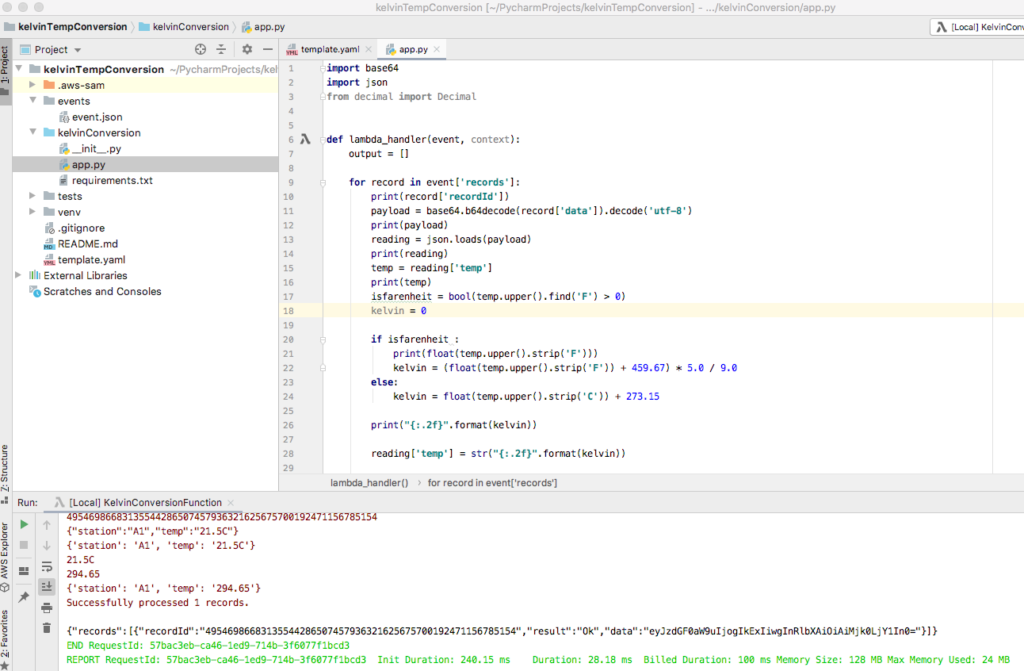
Modify the function to use find rather than the index function.
isfarenheit = bool(temp.upper().find('F') > 0)
Lambda function results in error due to the index function
Run the application locally using a celsius value. As before encode and decode and test the converted value.
Lambda function successfully ran with celcius data
After testing, right click on template.yaml and redeploy the serverless application.
Accept the Update Stack defaults.
Update Stack option in Deploy Serverless Application
After clicking Deploy a popup window informs you of the deployment progress.
Redeploying SAM application to AWS
Navigate to the Lambda function details in the AWS Console and you should see the corrected source code.
Transformation function reflects changes made in PyCharm
From your command-line send several records to the stream.
Navigate to the S3 bucket and you should see the transformed records.
Data streamed to S3 bucket
Summary
In this tutorial you created a Kinesis FIrehose stream and created a Lambda transformation function. You configured the stream manually and used SAM to deploy the Lambda function. An obvious next step would be to add the creation of the Kinesis Firehose and associated bucket to the Cloudformation template in your PysCharm project. This tutorial was sparse on explanation, so refer to the many linked resources to understand the technologies demonstrated here better. However, this tutorial was intended to provide a variation on the numerous more straightforward Kinesis Firehose tutorials available.
Attached find my study notes for the AWS Certified Developer Associate Exam. These notes were written in September 2019. The test may have changed considerably since then, so be certain to consult other sources.
I prepared for the AWS Certified Developer Associate exam through a combination of the A Cloud Guru’s Video course on Udemy, Whizlab’s practice exams, and my own study notes. I passed by the way.
In this tutorial we explore the AWS Key Management System (AWS KMS) to encrypt and decrypt data via the AWS Java 2 SDK. This tutorial encrypts/decrypts two different ways. We first encrypt and decrypt data directly using an AWS customer-managed key (CMK). We then encrypt and decrypt the data using a data key that was generated by the AWS CMK. Of the two, the second is more secure, and the preferred way to encrypt data. Although a CMK can encrypt and decrypt data, a better practice is to use the CMK to generate data keys, which are in turn used with the relevant data. However, for demonstration, we also use the CMK directly.
Introduction to AWS KMS
In this tutorial we use the AWS SDK for Java version 2.x and the AWS KMS for encrypting and decrypting resources.
AWS SDK for Java Version 2.x
In this tutorial we use the Java Version 2.x of the AWS SDK. The SDK provides a convenient wrapper around the AWS services’ lower-level REST calls. Be certain you use version 2.x and not 1.x, as 2.x is a rewrite of the API and so there are considerable differences between the two API versions.
AWS KMS is a service that enables generating, storing, and managing symmetric keys. The service is integrated with other Amazon offerings such as S3. Actually, most AWS services are integrated with KMS, as this list of over 50 services illustrates. However, KMS can also be used to generate and manage your own application’s keys even if that application is independent of other AWS services.
A symmetric key is a single key used to encrypt/decrypt data. This is in contrast to an asymmetric key, where a private key and public key encrypt/decrypt data. Wikipedia has a good general introduction to key encryption: Key (Cryptography). A typical strategy for symmetric key encryption is as follows. A single master key is used to encrypt/decrypt data encryption keys. These data keys encrypt/decrypt your application’s data. To ensure security, when not in use, the data keys are encrypted/decrypted by the master key. The master key is then stored in a safe location so it can be used as needed.
AWS KMS provides a secure location to store and manage your master keys. CMKs cannot be exported from KMS and can only be used by users with appropriate permissions assigned. The KMS FAQ summarizes KMS.
AWS KMS is a managed service that enables you to easily encrypt your data. AWS KMS provides a highly available key storage, management, and auditing solution for you to encrypt data within your own applications and control the encryption of stored data across AWS services.
AWS Key Management Service FAQs
AWS KMS offers many benefits for developers using AWS services.
If you are a developer who needs to encrypt data in your applications, you should use the AWS Encryption SDK with AWS KMS support to easily use and protect encryption keys. If you’re an IT administrator looking for a scalable key management infrastructure to support your developers and their growing number of applications, you should use AWS KMS to reduce your licensing costs and operational burden. If you’re responsible for proving data security for regulatory or compliance purposes, you should use AWS KMS to verify that data is encrypted consistently across the applications where it is used and stored.
AWS Key Management Service FAQs
AWS KMS offers an integrated cloud environment for managing keys.
You can perform the following key management functions in AWS KMS:
Create keys with a unique alias and description Import your own key material Define which IAM users and roles can manage keys Define which IAM users and roles can use keys to encrypt and decrypt data Choose to have AWS KMS automatically rotate your keys on an annual basis Temporarily disable keys so they cannot be used by anyone Re-enable disabled keys Delete keys that you no longer use Audit use of keys by inspecting logs in AWS CloudTrail Create custom key stores* Connect and disconnect custom key stores* Delete custom key stores*
* The use of custom key stores requires CloudHSM resources to be available in your account.
AWS KMS FAQ.
For more introductory information refer to The AWS Key Management Features webpage maintained by Amazon. Also refer to the videos embedded at the end of this tutorial.
In this tutorial we perform the following tasks:
create two users, one to manage a CMK and another to use the CMK,
create a CMK and assign the users to the key,
build an application that uses the CMK directly to encrypt/decrypt data,
discuss why using the CMK directly is not an optimal encryption strategy,
and create an application that uses the CMK to create a data key to encrypt/decrypt data.
In this tutorial we limit using KMS to generating a data key and to encrypting/decrypting data. You can also manage keys through the Java SDK; however, this tutorial does not cover key management, assuming instead you will do so through the AWS console or AWS Command-line Interface (CLI).
It is assumed you have an AWS account, know your way around the AWS Console, and have enough experience with Java programming that you do not require help using an IDE such as Eclipse.
Creating the CMK
Before using the CMK we need to create it. Although you can use the Java SDK to perform all the following tasks, we use the AWS Console for creating the required users and key.
Create Users
We need to create users for our CMK. The first user we create is the key manager. Although this tutorial does not subsequently use this user, we include it as in a real project you would eventually need this user for managing keys. The second user we create is the key user. This is the user that is allowed to use the CMK to encrypt/decrypt data. We do use this data in the Java application.
All Users, Keys, and potentially sensitive information will have been removed from my account before this tutorial is posted.
Create Manager
Let’s first create the manager user.
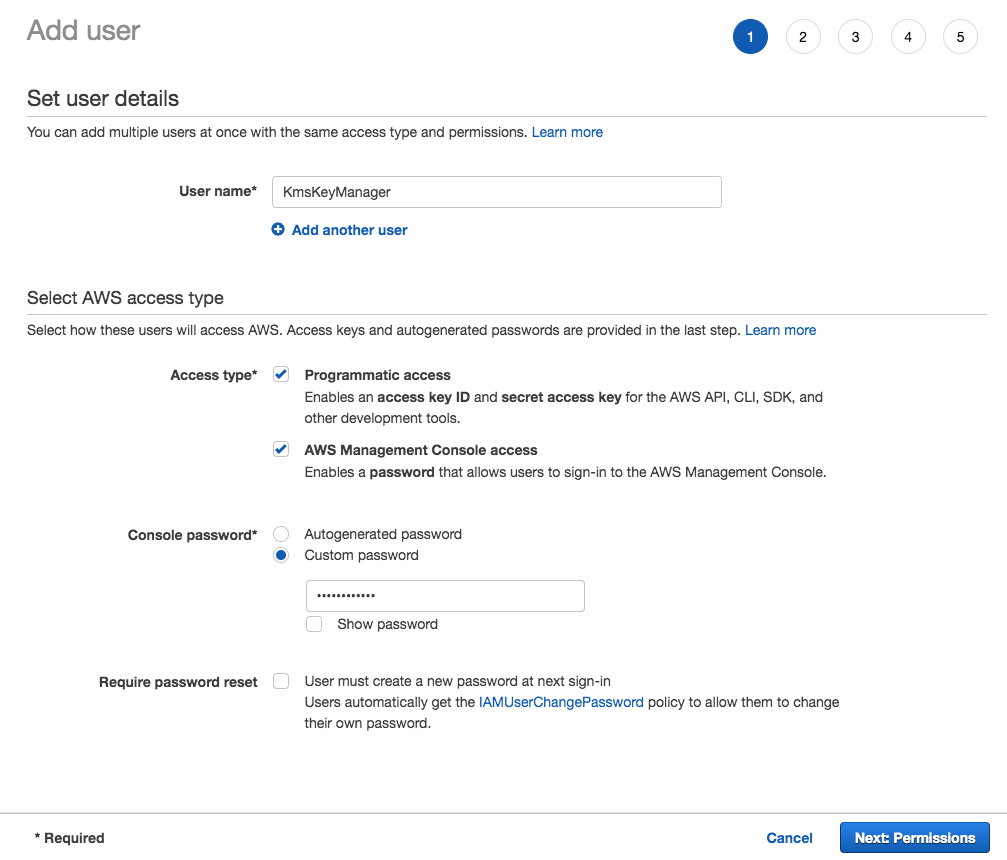
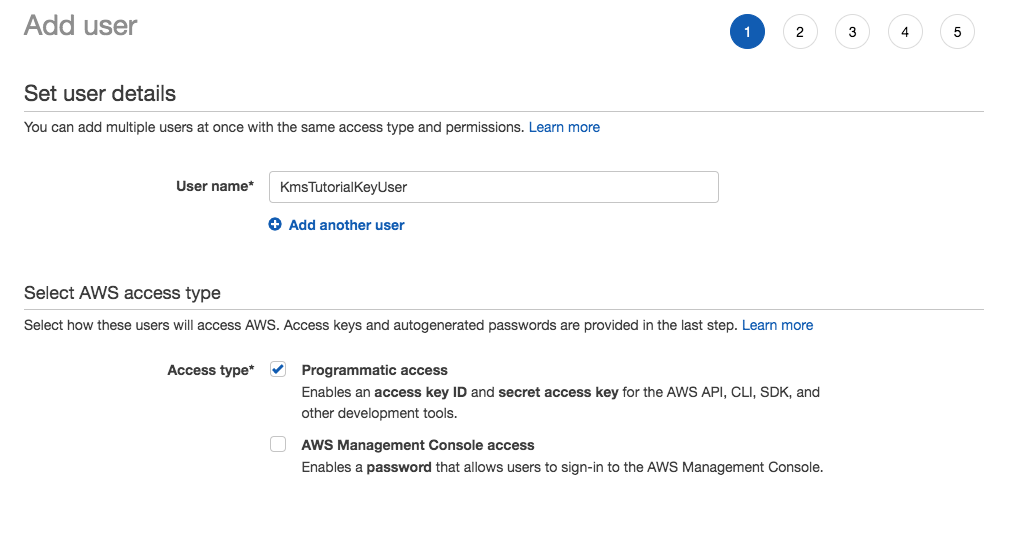
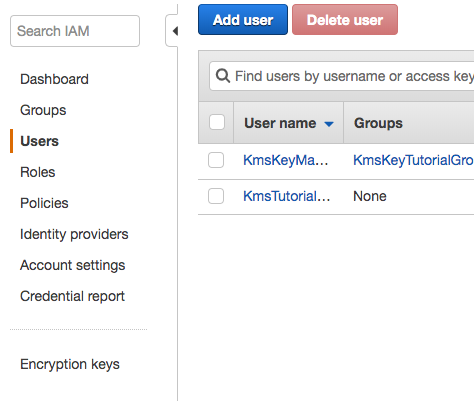
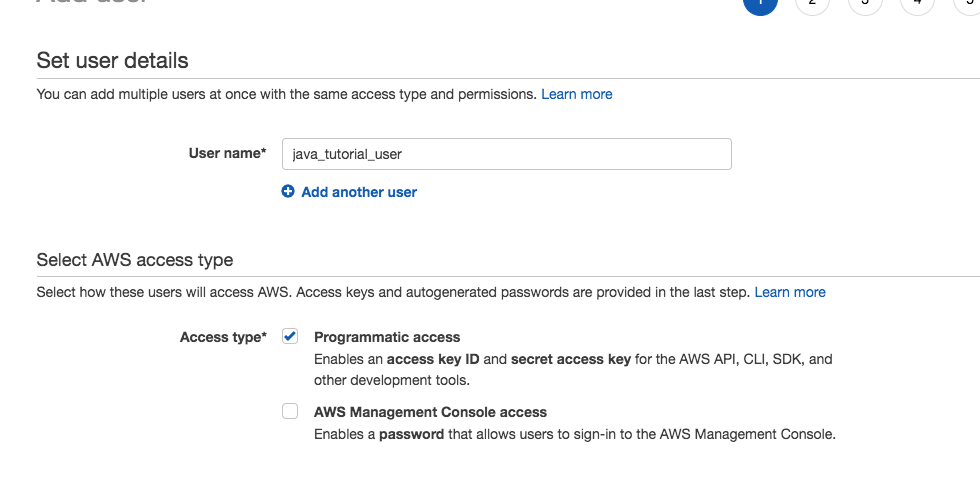
Navigate to IAM, Users, and add a User named KmsKeyManager.
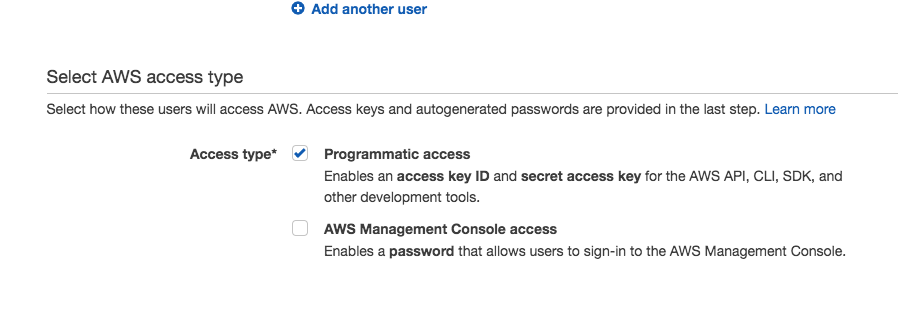
Assign the user programmatic and console access.
Create a password for the user and uncheck the Require password reset checkbox.
Adding the KmsKeyManager user via the Add user page
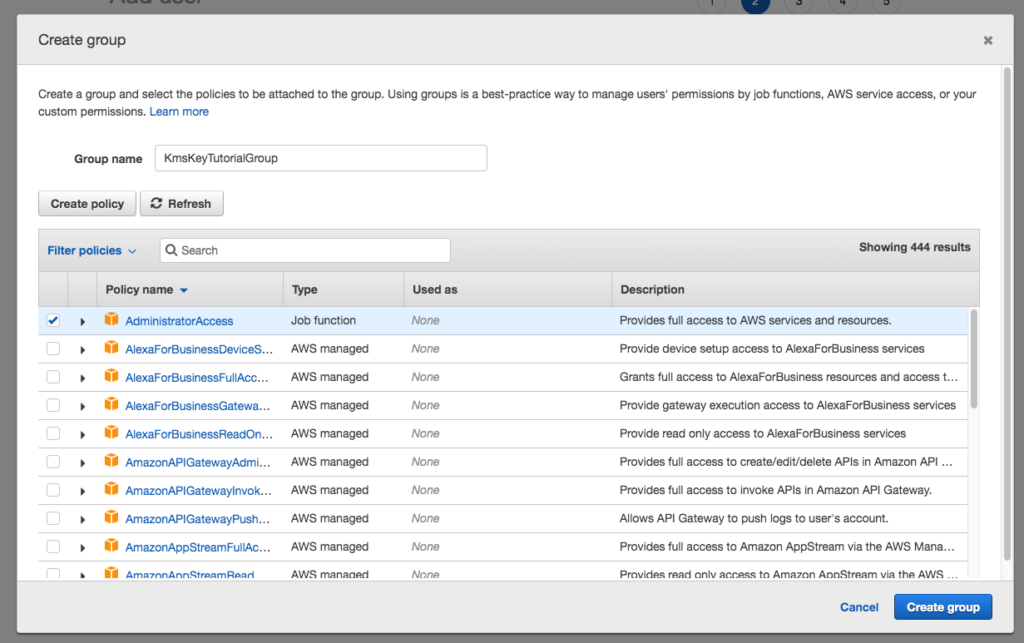
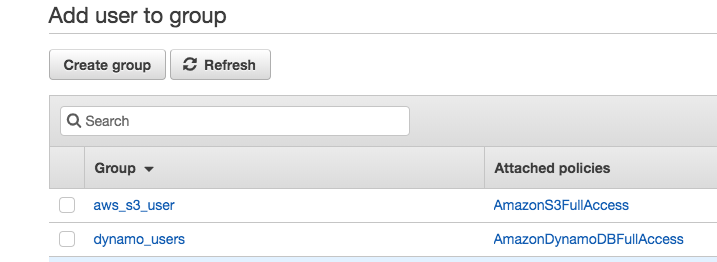
When you add the user to groups, create a new group named KmsKeyTutorialGroup and assign it AdministratorAccess.
Adding policies to a KmsKeyTutorialGroup
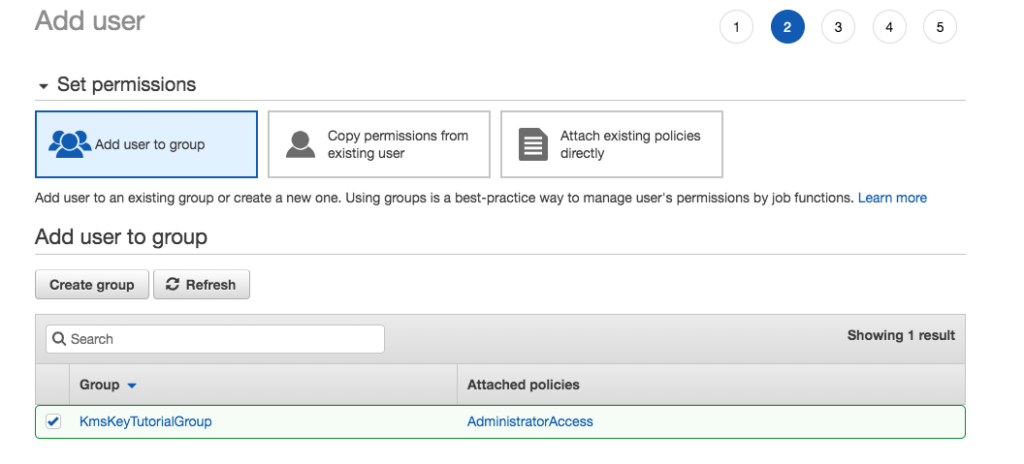
Add KmsKeyManager to KmsKeyTutorialGroup.
Assing KmsKeyManager to KmsKeyTutorialGroup
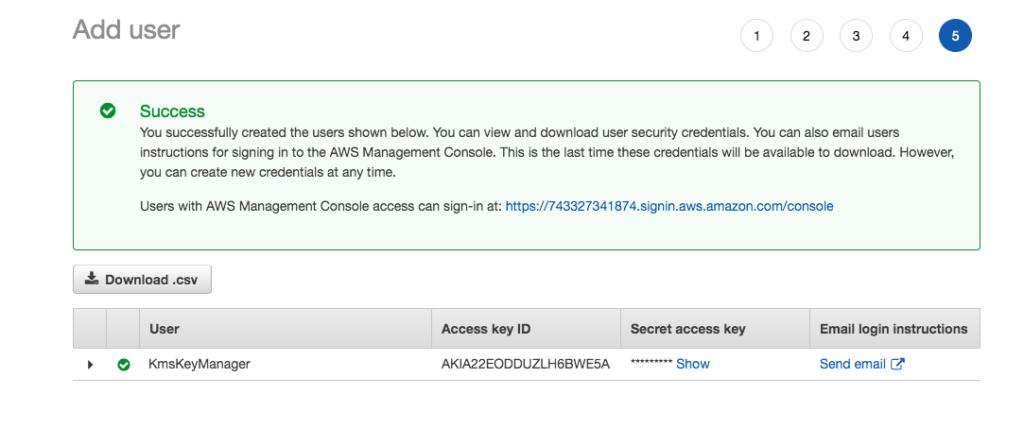
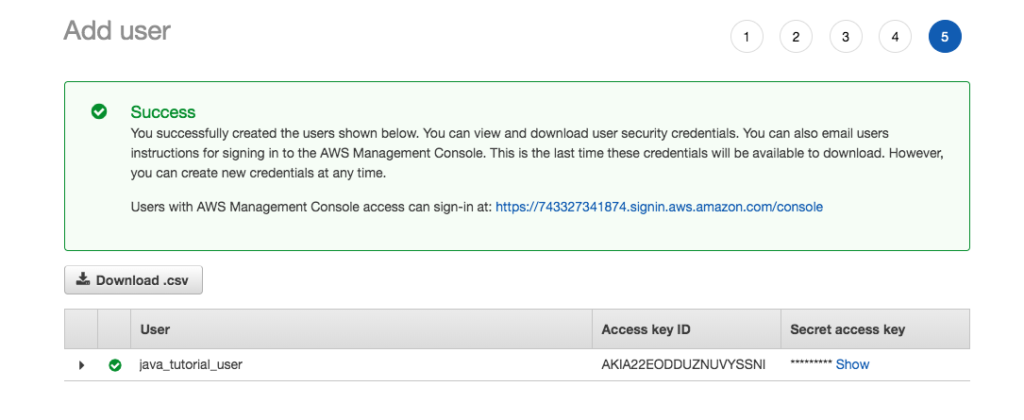
After creating the user you should see a screen similar to the following. Do not forget to download the access keys so you can use them in your Java program.
KmsKeyManager created successfully
Create Encrypt/Decrypt User
Let’s now create the user we use to encrypt/decrypt data in our Java application.
Create a user named KmsTutorialKeyUser and assign programmatic access.
Creating the KmsTutorialKeyUser
Do not assign KmsTutorialKeyUser to any groups.
The Users screen with two newly added users, KmsKeyManager and KMSTutorialKeyUser
Create AWS KMS Key
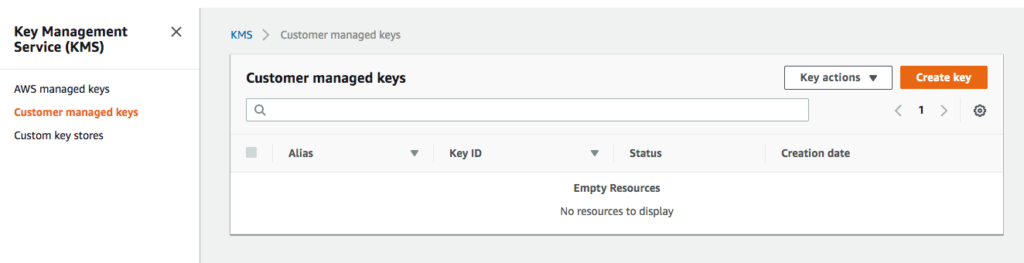
Navigate to IAM and then select Encryption keys to bring you to the Key Management Service (KMS).
Customer managed keys screen with no keys
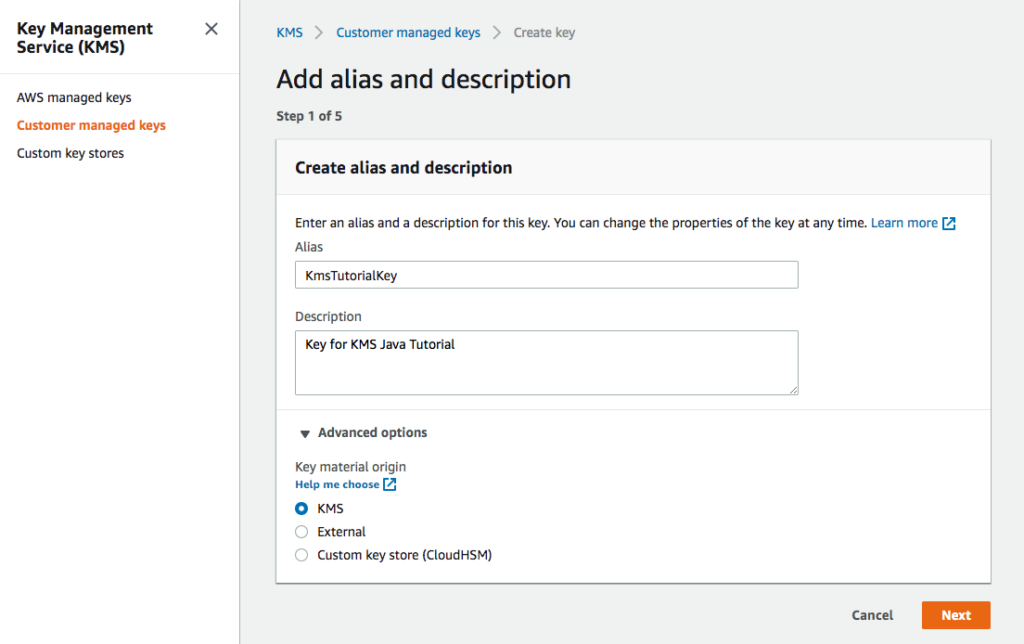
Create a new key with the alias, KmsTutorialKey.
Select KMS as the Key material origin.
Creating the KmsTutorialKey
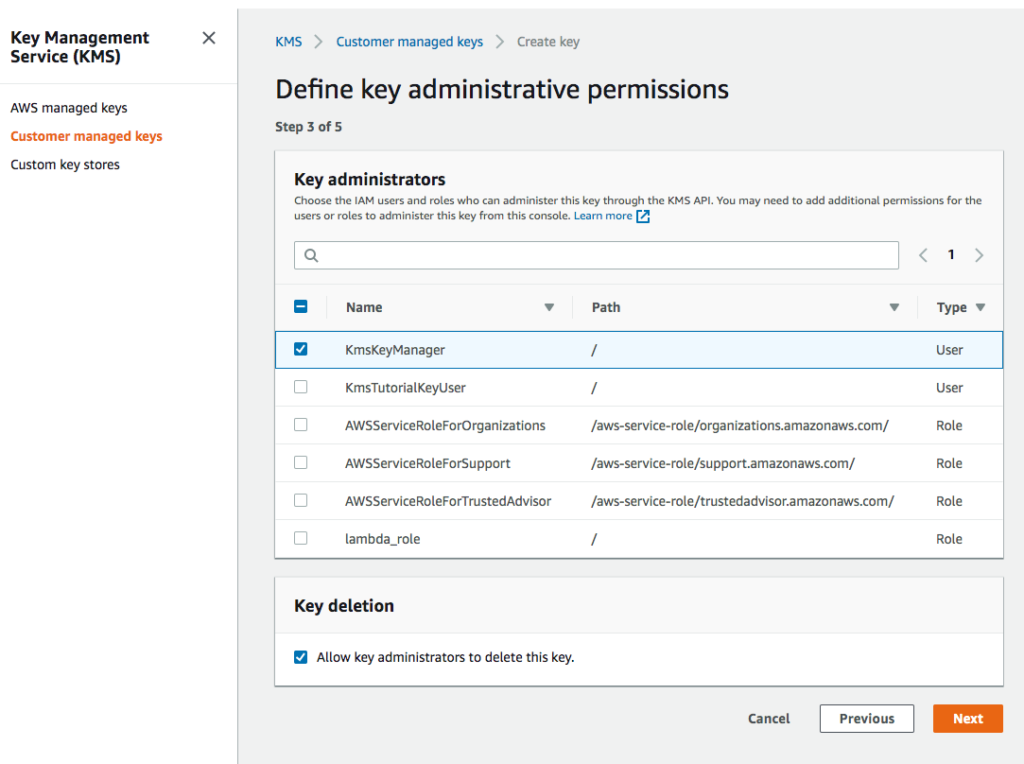
Assign KmsKeyManager as the key administrator.
Key administration permissions assigned to KmsKeyManager
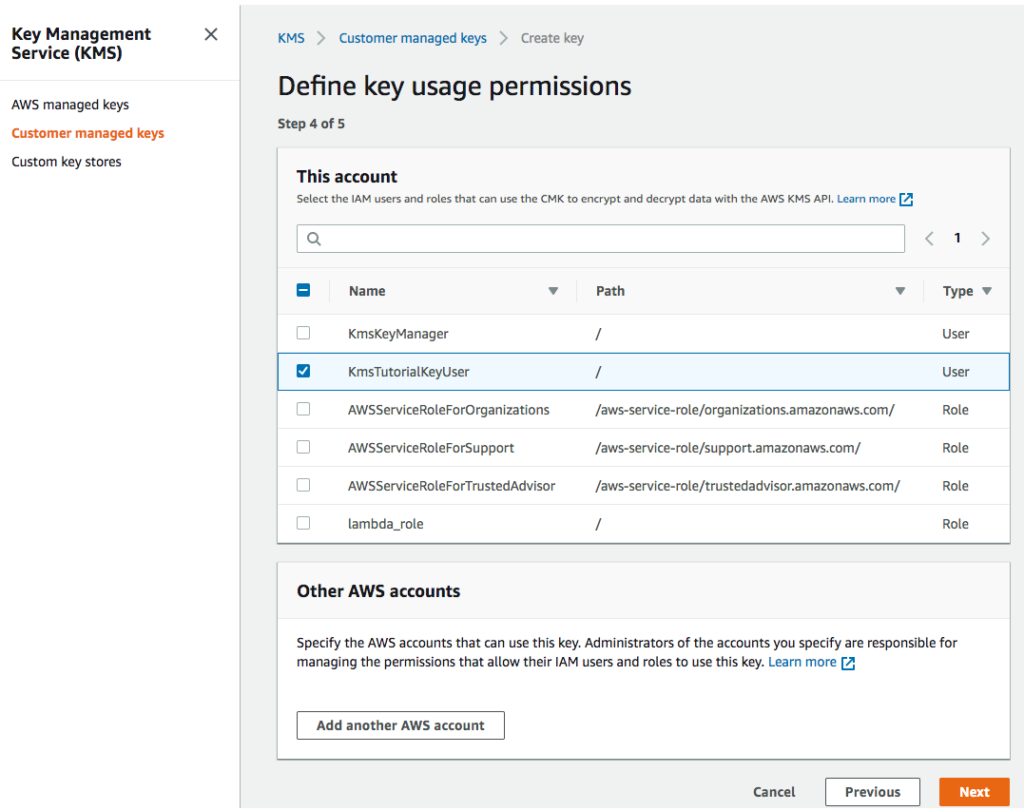
Assign KmsTutorialKeyUser as the key user (can encrypt and decrypt using the key).
Assigning encrypt/decrypt permission to KmsTutorialKeyUser
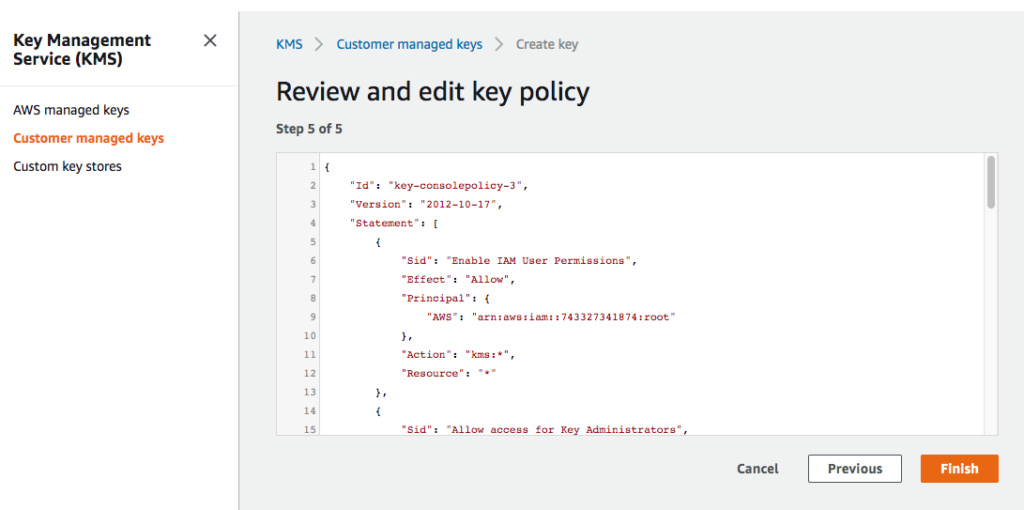
If interested, review the JSON document.
Complete policy document is JSON
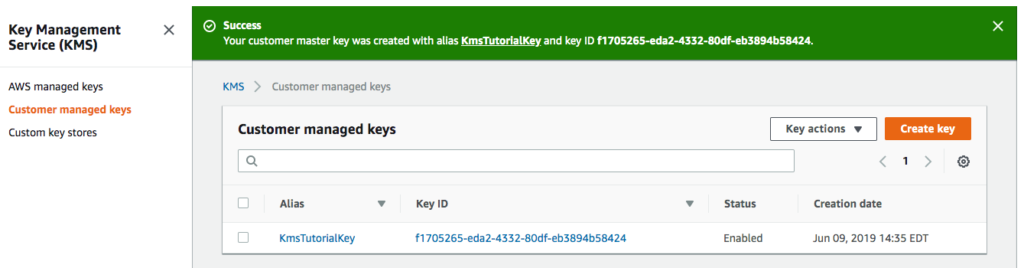
After finishing, you should see a screen similar to the following.
KMS screen with newly created CMK
Java Project
Let’s create the Java project using Maven. Although I use Eclipse, any IDE or the command-line should work. It is assumed you can create a Java project that uses Maven to build. If you need help accomplishing this task, refer to a tutorial online. The following is a good introductory tutorial for Maven and Eclipse.
Note the POM includes the following lines. You might not require these lines; however, the Java 2 SDK uses features that require Java 8 or higher, and I could only get the code to compile including these lines. YMMV.
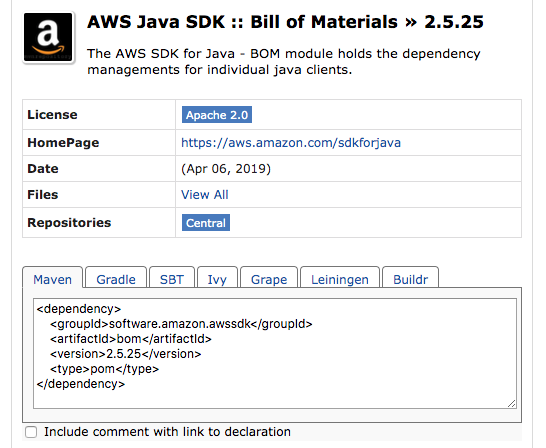
The POM adds the AWS Bill of Materials (BOM) to free us from having to manage the library versions, focusing only on including the correct dependencies rather than their versions. The POM also includes the KMS library and the core libraries required by AWS.
If using Eclipse, add a file named observation.json to the resource folder.
The observation.json file is a simple JSON record.
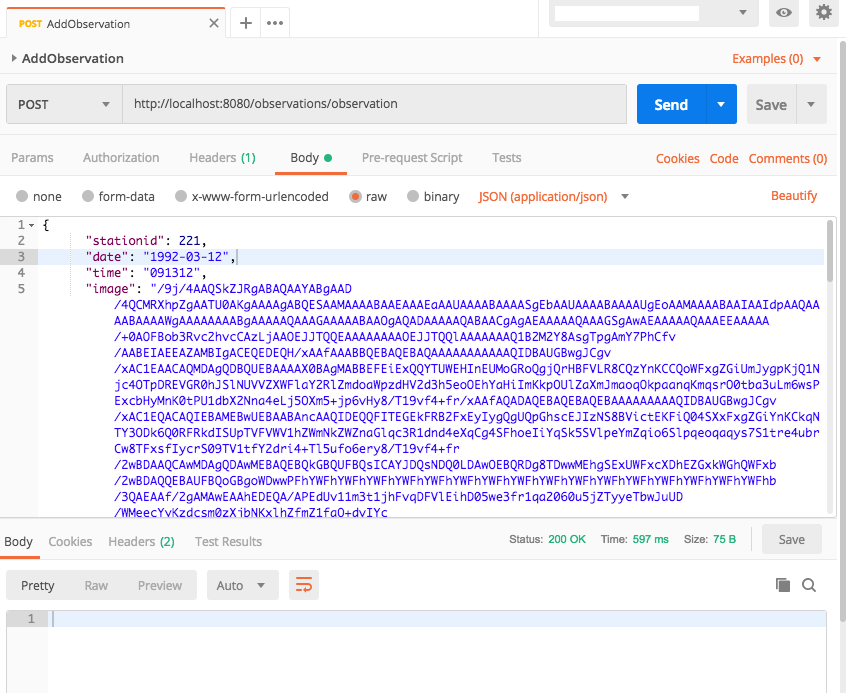
{
"stationid": 221,
"date": "1992-03-12",
"time": "091312",
"message":"This is a secret message. Please encrypt it when storing on disk."
}
AWS KMS Client
The AWS SDK is consistent in how you interact with AWS’s different services. The 2.x API version consistently follows the Fluent Interface/Builder pattern. You can find more information on this pattern if interested by starting with the wikipedia page. A good introductory explanation is found in the following blog post: Another builder pattern for Java. Rather than instantiating new instances of a class, you build the class you a builder. When using the AWS SDK, you create a client with the required credentials using the client’s associated builder. For instance a KmsClient has a KmsClient.Builder that builds it. Different services have different clients. The KMS service uses the KmsClient. Clients work with AWS via requests and is returned responses. The KmsClient class, for example, uses requests to encrypt/decrypt, create keys, and manage keys.
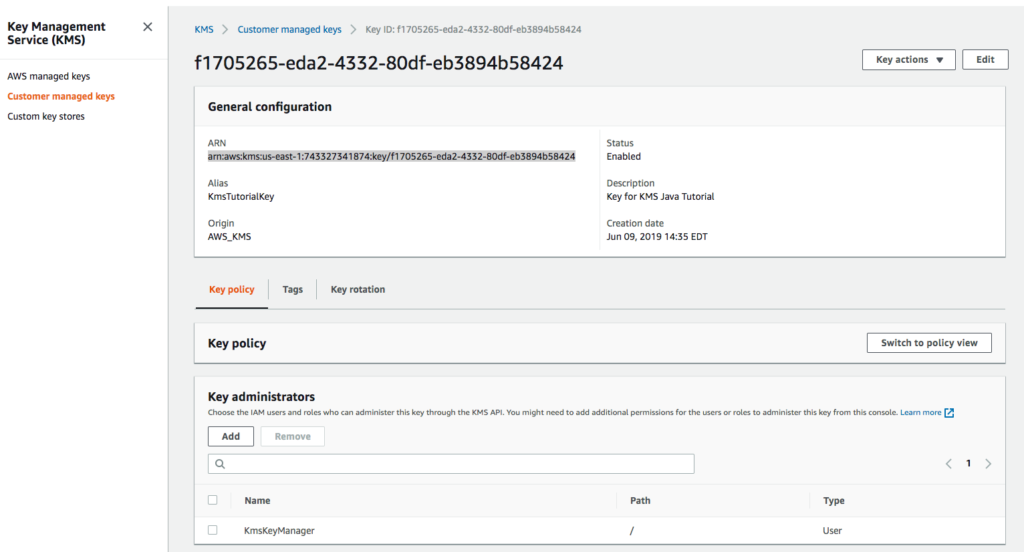
Let’s create the KmsClient. But first we need to return to the AWS Console and copy the CMK key’s Amazon Resource Name (ARN). The ARN is how our application’s client will know where to access the CMK in KMS.
Navigate to the key and copy the key’s ARN.
Copy the CMK ARN in the AWS Console
An ARN identifies any resource on AWS uniquely. The client uses this to access the CMK.
Create a new class in named KMSExample in the com.tutorial.aws.kms package.
Although it is not recommended you hardcode keys in your code, for convenience we create the key and secretKey static variables to held the KmsTutorialKeyUserkey and secretKey.
Create a keyArn static variable and assign it the ARN you copied above from the AWS console.
Create a KmsClient variable and build it in the constructor for KMSExample.
In main, create a KMSExample instance.
package com.tutorial.aws.kms;
import software.amazon.awssdk.auth.credentials.AwsBasicCredentials;
import software.amazon.awssdk.auth.credentials.StaticCredentialsProvider;
import software.amazon.awssdk.regions.Region;
import software.amazon.awssdk.services.kms.KmsClient;
public class KMSExample {
final static String key = "<key_value_here>";
final static String secretKey = "<secret_key_value_here";
final static String keyArn = "<key_arn_here>";
public KmsClient kmsClient;
public KMSExample() {
AwsBasicCredentials awsCreds = AwsBasicCredentials.create(key,
secretKey);
this.kmsClient = KmsClient.builder()
.credentialsProvider(StaticCredentialsProvider.create(awsCreds))
.region(Region.US_EAST_1).build();
}
public static void main(String[] args) {
try {
KMSExample kmsExample = new KMSExample();
}
catch (Exception e) {
e.printStackTrace();
}
}
}
Build the application and run the application, just to ensure everything works.
The KMSExample class uses a KmsClientBuilder to build a KmsClient instance. The KmsClientBuilder uses the region, the credentials, and the key’s ARN to create a KmsClient that can interact with our CMK (KmsTutorialKey).
After becoming familiar with the 2.x API version, translating constructors and methods to the 2.x API’s builder methods becomes intuitive.
Encrypting and Decrypting Using the Customer Key
In the first example we encrypt and decrypt the data directly using the KmsTutorialKey. As discussed earlier, this is not the recommended way to encrypt/decrypt your application’s data. However, we include it here, as a CMK master key can be used directly in your application to encrypt/decrypt data. And, there might be situations where it’s appropriate to use the CMK directly.
Encrypt
Let’s encrypt the data. We do this by building an EncryptRequest using an EncryptRequest.Builder. The builder takes the request, the key’s ARN, and builds the EncryptRequest. We then pass the request to the KmsClient.
Add a method named encrypt to KMSTutorial that takes SdkBytes and returns SdkBytes.
Create an EncryptRequest by specifying the key’s ARN and the string to encrypt.
Have kmsClient encrypt the request and assign the response to an EncryptResponse.
The EncryptRequest returns an EncryptResponse. We use the ciphertextBlob method to extract the encrypted data from the response. Note that this data is Base64 encoded when accessing it through the HTTP API as we do in this tutorial (remember the Java SDK is a wrapper around AWS Rest APIs and Rest is typically – but not always – HTTP/HTTPS).
The SdkBytes class is Amazon’s wrapper around bytes. It can be created from byte arrays, a ByteBuffer, InputStream, or a String. The AWS SDK consistently uses this class rather than the classes the SdkBytes wraps. In the preceding code we used the cipherTextBlob to obtain the encrypted data from the response to our request to encrypt data using the CMK. The cipherTextBlob returns an SdkBytes.
Add a method named writeToFile that takes the SdkBytes to write and the path to the file to write the data to.
public static void writeToFile(SdkBytes bytesToWrite, String path ) throws
IOException {
FileChannel fc;
FileOutputStream outputStream = new FileOutputStream(path);
fc = outputStream.getChannel();
fc.write(bytesToWrite.asByteBuffer());
outputStream.close();
fc.close();
}
The writeToFile method writes the encrypted data to a file using the Java NIO API standard in the JDK. We use the SDKBytesasByteBuffer method to convert the data to a ByteBuffer so that the FileChannel can write the data to a file.
Modify main to open the observation.json file as an InputStream.
Create the input SdkBytes from the InputStream.
Call the encrypt method and assign the returned SdkBytes to a variable.
Save the SdkBytes to a file using the writeToFile method.
A DecryptRequest uses a DecryptRequest.Builder to build itself. The builder takes the encrypted text and sends it to the KmsClient. Note that it does not require passing the key’s ARN to decrypt.
Modify main to decrypt the encrypted file and print the results to the console.
Recall you cannot export CMKs from AWS KMS. You are also limited to encrypting data of 4kb or less. Both these limitations limit what you can encrypt using a CMK. Also note that you must send the data to the AWS KMS to encrypt/decrypt the data. Although convenient, using a CMK as we did in the preceding section is not ideal. Instead we should use the CMK as a master key that generates, encrypts, and decrypts data keys. You then use data keysThe CMK is responsible only for encrypting/decrypting data keys.
Data keys are designed to be used within your external application that resides outside KMS. Data keys can encrypt/decrypt data of any size and are stored in your own application.
Envelope Encryption is how AWS KMS protects the generated data key. The KMS creates a data key, encrypts the data key, and returns the encrypted data key version and the plain-text unencrypted version of the data key. The plain-text version of the key is what your application uses to encrypt and decrypt data. The encrypted version of the key is what your application saves to use later. You should always ensure the plain-text data key is deleted and removed from memory soon after use so your data’s security is not compromised. When your application needs to use the data key again, request that the AWS CMK decrypts the data key and then use that decrypted key locally.
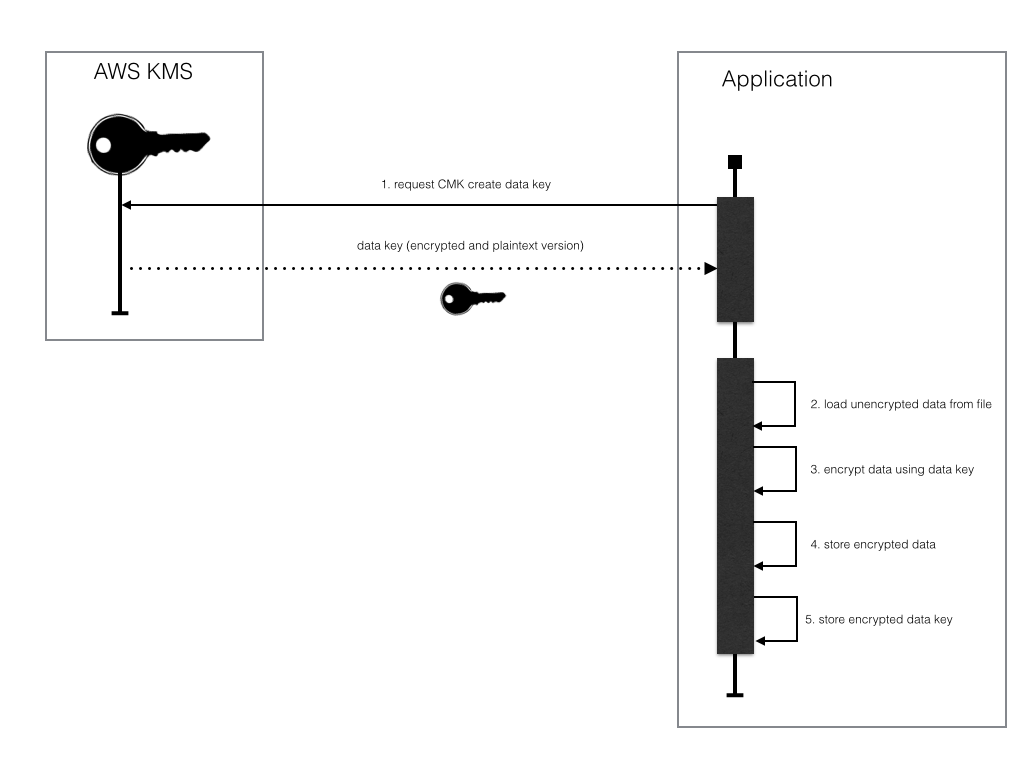
In the example below we use the CMK above to generate a data key and use that data key to encrypt data. The steps to encrypt in this tutorial are as follows.
Request that the CMK in KMS generates a data key.
Load unencrypted data from file.
Use plain-text version of returned data key to encrypt data.
Store encrypted data to a file.
Store encrypted version of key to a file.
Using a data key to encrypt data
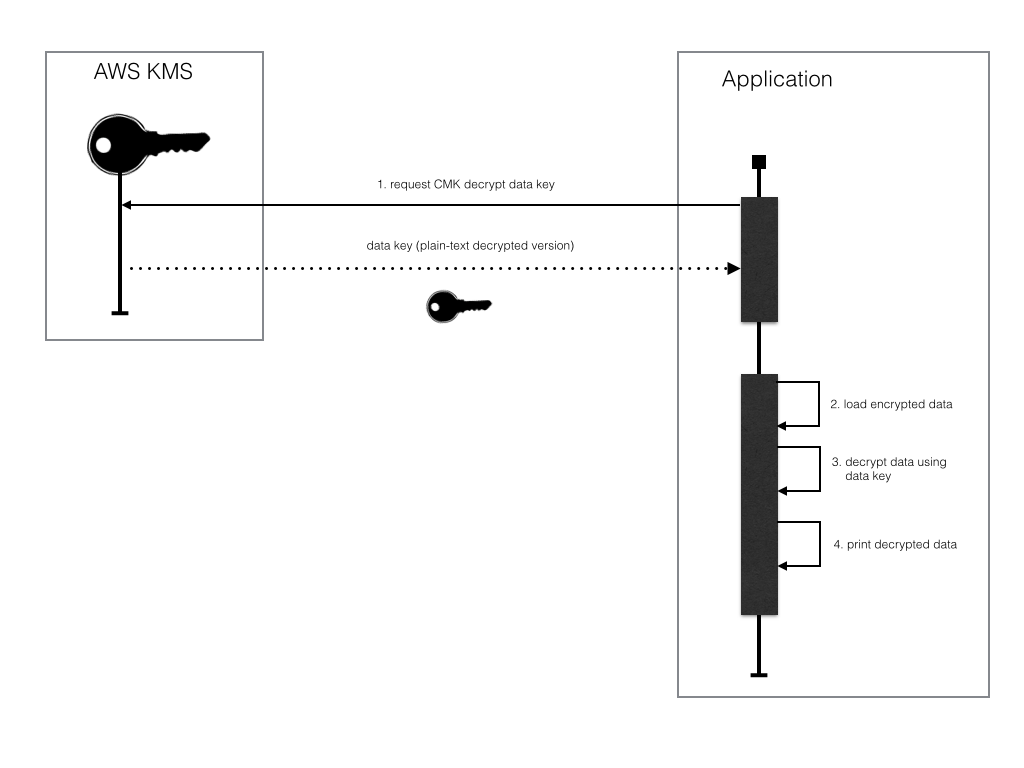
After encrypting the data, we then decrypt the data using the data key. However, before we can decrypt the data using the data key we must first use the CMK to decrypt the data key. The process our application uses is as follows.
Load encrypted data key from file.
Request AWS KMS used to originally encrypt the data key to decrypt the data key.
Load encrypted object from file.
Use decrypted data key to decrypt object.
Print decrypted data to console.
Using a data key to decrypt data
Although we use the KMS to work with the CMK, we must work with the data key locally. We do so using the java crypto package.
Modify KMSExample so that its import list contains the following.
The GenerateDataKeyRequest wraps a request to generate a data key. You create a GenerateDataKeyRequest using a GenerateDataKeyRequest.Builder. The builder uses the CMK’s ARN and data keyspec to build the request. The KmsClient then passes the request to the KMS which uses the specified CMK to generate the data key. The data key is returned in a GenerateDataKeyResponse.
The AES specifies we wish our data key to use the Advanced Encryption Standard. We must use the same keyspec when using our data key that was used to generate the data key.
We take the plain-text (unencrypted) key version from the response and use it to build a SecretKeySpec. We then pass the SecretKeySpec to a Cipher, which encrypts the data using the Java Cryptography Extension framework. You can obtain more information by consulting this resource: Java Cryptography Architecture (JCA) Reference Guide
Modify main to call encryptUsingDataKey.
Remove the code that used the CMK to encrypt and decrypt the data.
kmsExample.encryptUsingDataKey(inputBytes);
The main method should appear as follows after adding the call to encrypt the data using a data key.
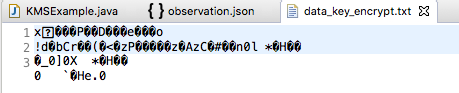
Build and run the program and there should be two files: data_key_encrypt.txt and observation_datakey_encrypt.json, the encrypted data key and the encrypted data respectively.
Encrypted data key stored locally on diskEncrypted data stored locally on disk
Decrypting Using Data Key
Let’s decrypt the encrypted data key and use it to decrypt the encrypted data. We first decrypt the local data key by passing it to KMS which uses the CMK to decrypt the key. We then use the returned decrypted key to decrypt the data locally.
Create a new method named decryptUsingDataKey.
Read the encrypted data key from the file.
Create a new DecryptRequest from the data key.
Decrypt the data key by passing the DecryptRequest to the kmsClient.
Create a SecretKeySpec from the decrypted data key.
Read the encrypted data from a file.
Create a Cipher and use it and the SecretKeySpec to decrypt the data.
Build and run the application. You should see the JSON record printed to the console.
{
"stationid": 221,
"date": "1992-03-12",
"time": "091312",
"message":"This is a secret message. Please encrypt it when storing on disk."
}
Conclusion
Amazon’s KMS is a convenient and powerful service to manage your organization’s keys. It is integrated with most AWS Services. You can also use it directly in your application, as demonstrated in this tutorial. The most common use pattern is to create a CMK which must reside in KMS as your master key. That CMK is then used to create local data keys. The local data keys encrypt/decrypt the data. Only the encrypted version of the data key should ever be persisted locally. Instead, whenever the local data key is needed it is passed to KMS so that the associated CMK can decrypt the data key.
You can also administer KMS using the Java API; however, in this tutorial we restricted ourselves to decrypting and encrypting data.
More Resources
Here are two introductory videos on KMS. Neither are programming specific, but they both provide a greater understanding of KMS.
AWS SQS Message Queues are a way to exchange messages between applications. Senders, send data objects to a queue and receivers, receive objects from a queue. Amazon’s Simple Queue Service (AWS SQS) is a service offered by AWS that offers scalability and reliability by being distributed across Amazon.
A message queue decouples applications. An message producer only knows about the queue and knows nothing about the queue’s consumers. Likewise, a message consumer only knows about the queue and knows nothing about the queue’s other consumers or producers. Moreover, producers and consumers know nothing about timing, and are asynchronous.
For more on queues and message-passing in general, there are many resources online. Here is a good reference from MIT: Reading 22: Queues and Message-Passing.
Use Case
Suspend disbelief, or more accurately, simply build the system regardless of what you think about the soundness behind the business plan. Famous entrepreneur John Bunyan from Washington State has a plan to get rich and famous by finally proving conclusively that Bigfoot – or Sasquatch for the cultured – exists and uses the extensive system of hiking trails to move around.
Against his accountant’s advice, he liquidated half his fortune to install a series of hidden cameras along Washington State’s hiking trails to take photos every fifteen minutes. As he is a busy man, he does not have time to analyze all the photos personally, and so he want’s image analysis software to analyze the images. If the software registers a Sasquatch, he wants the images to personally go to his email account so he can register the image as a Squatch or not.
Now, with if 10,000 cameras take a picture every 15 minutes, that is 600,000 images per hour. Assume each image takes up to five minutes to process. Hopefully you can see, we have a scalability issue.
There are various ways to deal with this scalability issue, but as this is a tutorial on SQS, we use AWS SQS. And, as I am fond of admonishing in all my tutorials, if the “business case” seems suspect, then suspend disbelief and focus on the AWS code.
Design
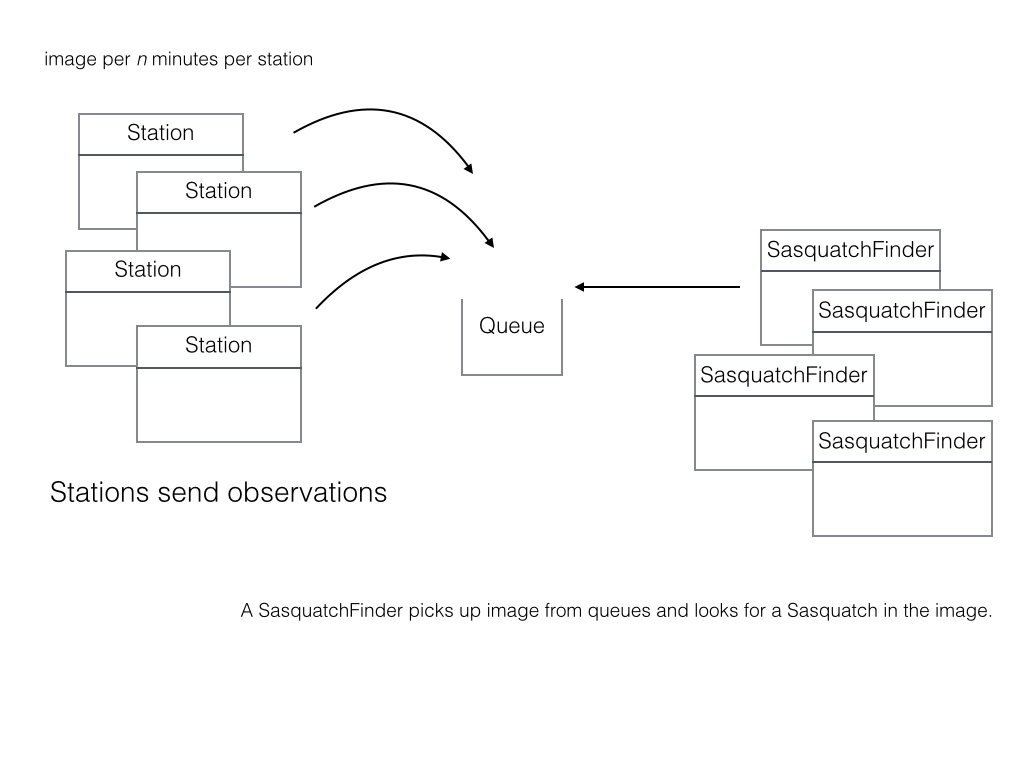
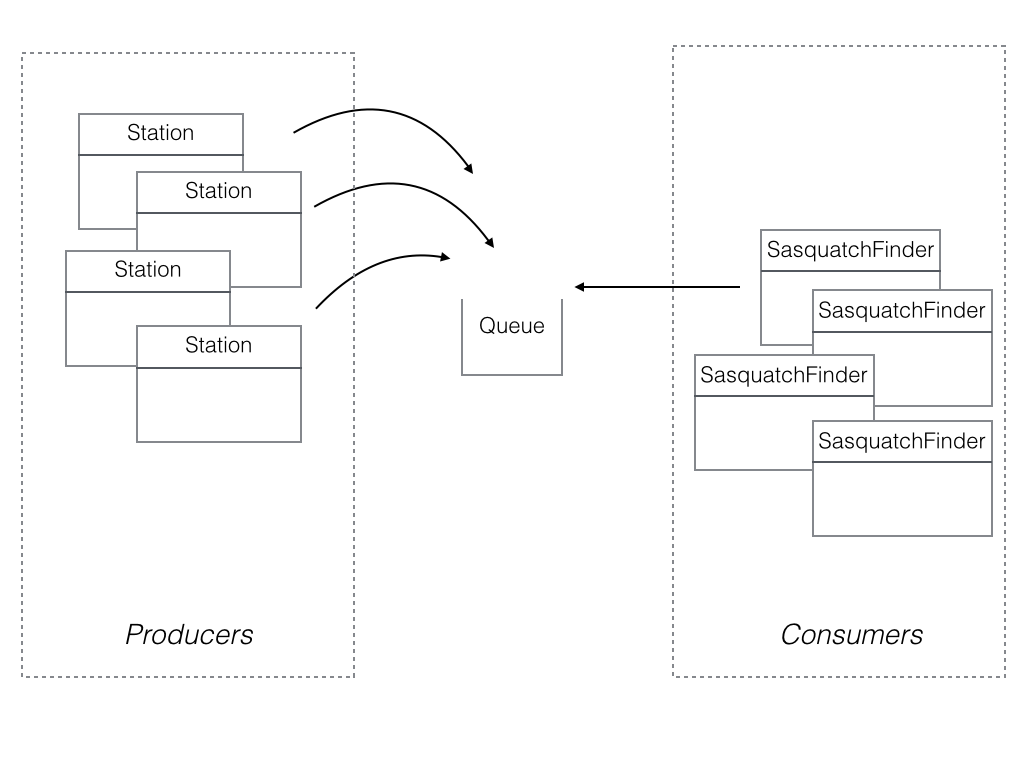
Enough apologizing for the business case, let’s focus on the application’s design. The following diagram illustrates the dilemma.
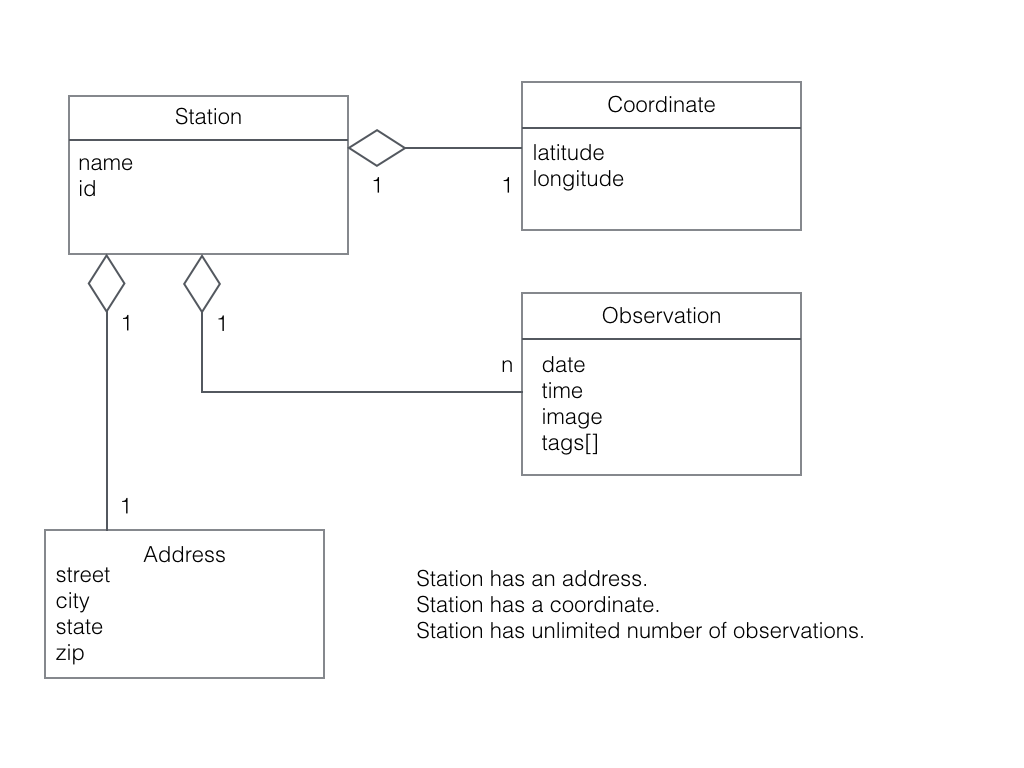
Every n minutes a Station sends an observation to an AWS queue.
There are 1 or more SquatchFinder components who’s job is to pick up an observation from the queue and process the observation.
Station is the producer while SasquatchFinder is the consumer.
Stations send observations to the queue and SasquatchFinders get observations from the queue.Queues implement an asynchronous Producer/Consumer design pattern.
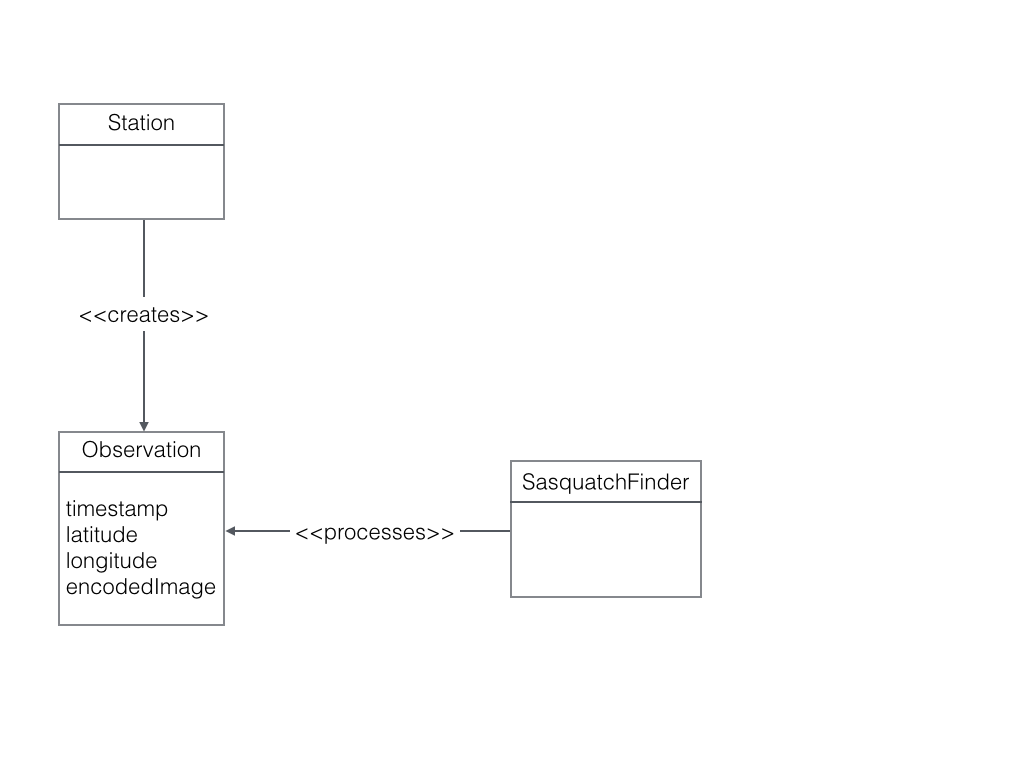
We can formalize our requirements with a simple class diagram. A Station creates an Observation. A SasquatchFinder processes an Observation.
Class diagram illustrating the design.
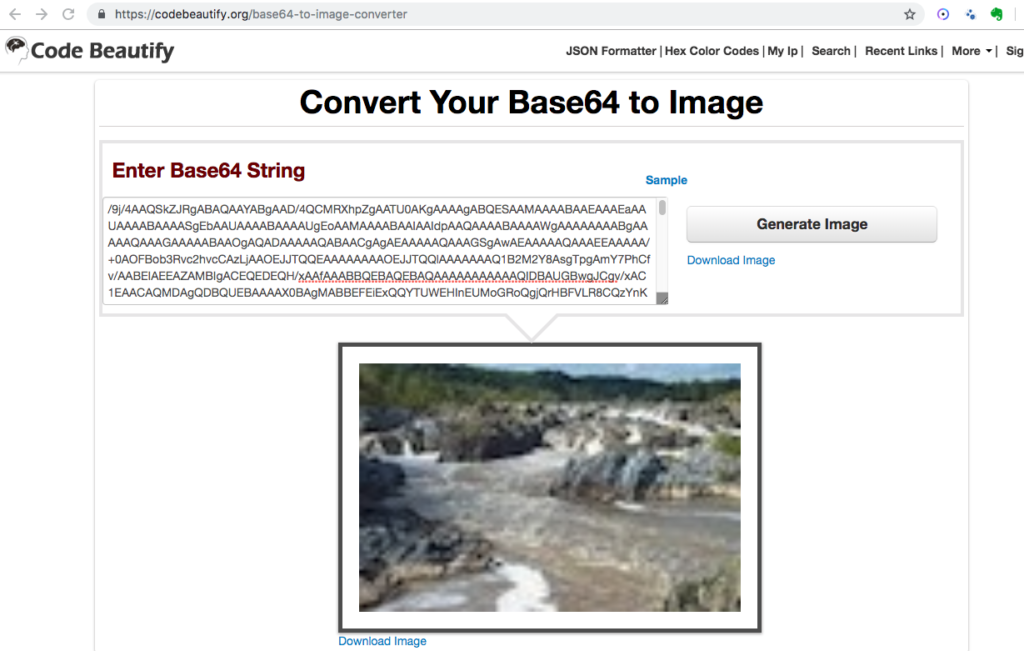
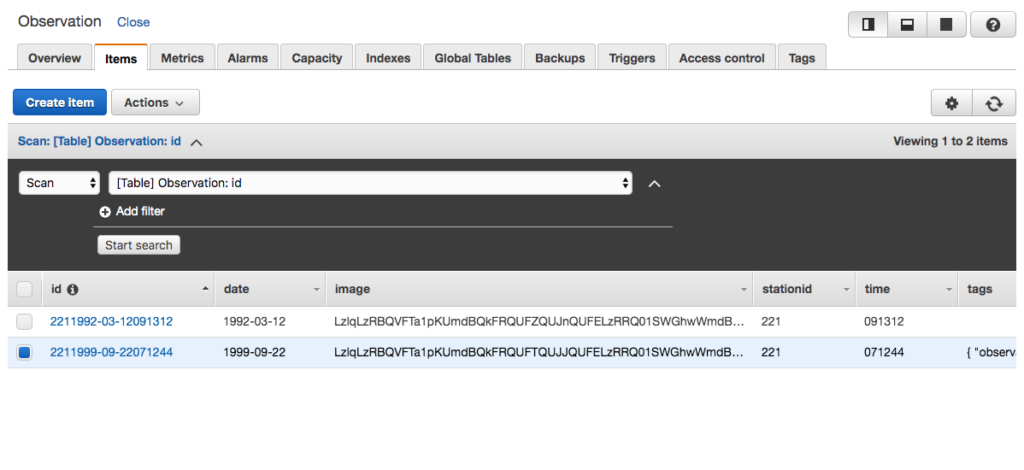
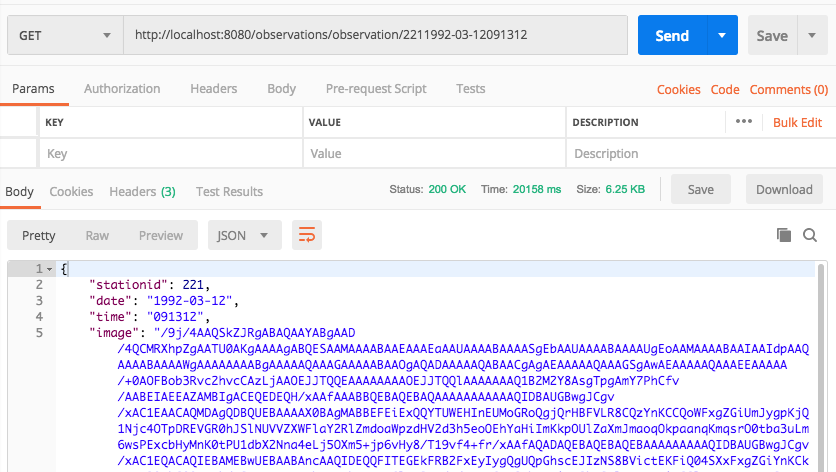
All communication with AWS isfrom external processes is via its REST API. AWS SQS is no different. Moreover, SQS queues only accept textual data. But a common need is for the queue to accept binary data, such as an image. Also, JSON is a textual data transport format.
We can translate the Observation into a JSON document. The image is converted to base64 encoding so it can be represented as text. Note the encodedImage in this tutorial is always truncated with <snip>, as the base64 string is quite long.
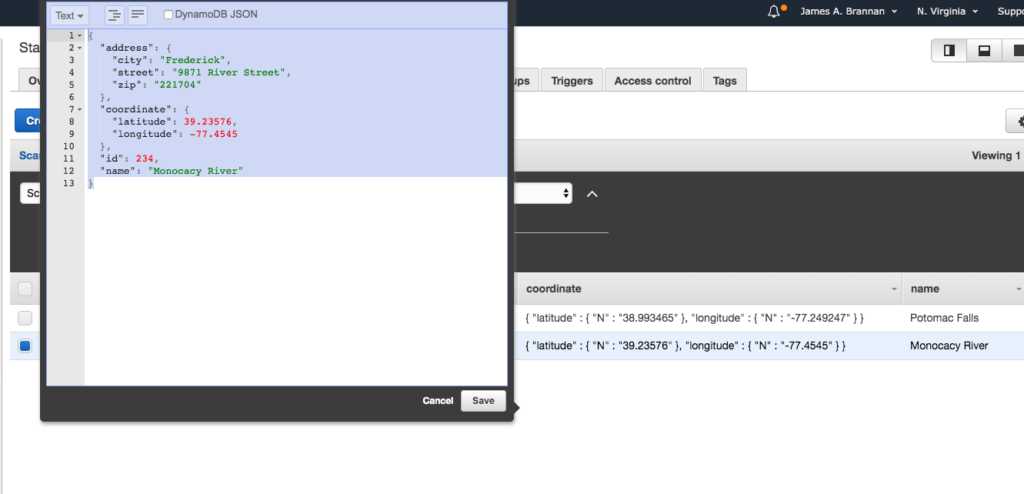
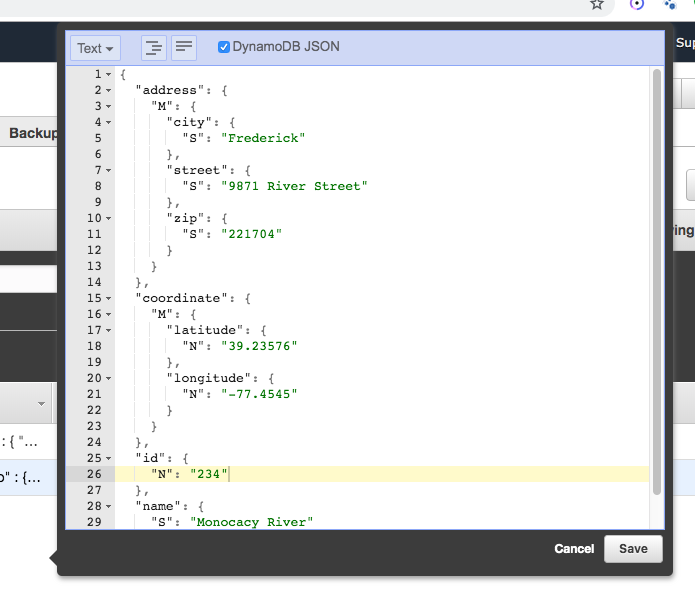
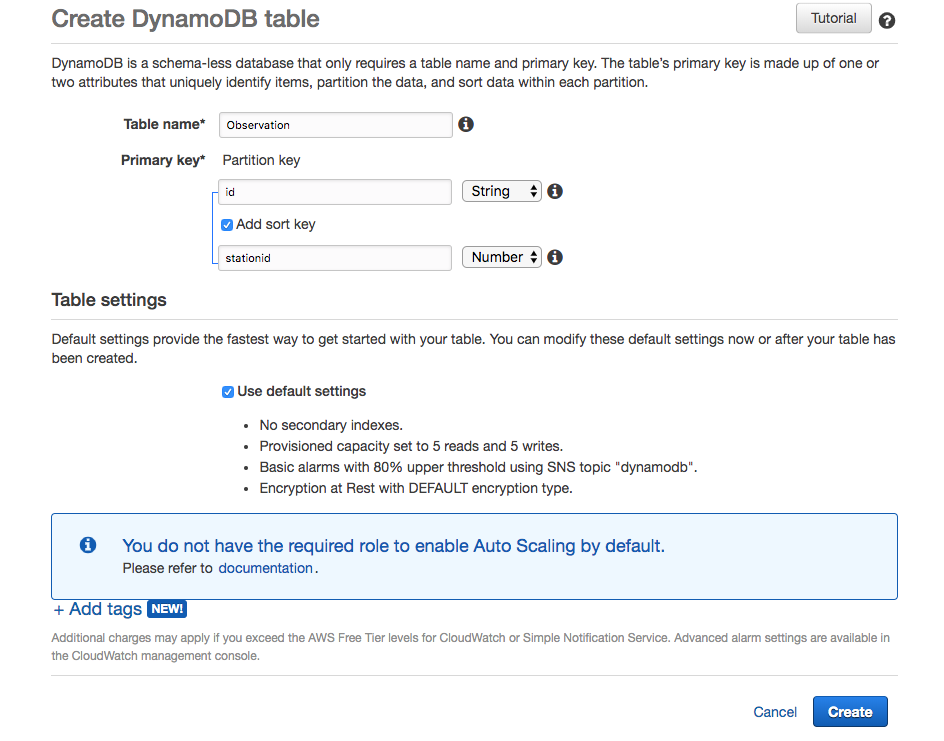
Images are binary. However, all binary can be represented by a String provided it is encoded and decoded correctly. Base64 is an encoding scheme that is converts binary to a string. It’s useful because it allows embedding binary data, such as an image, in a textual file, such as a webpage or JSON document. AWS SQS queues only allow textual data, and so if you wish to store an image on an AWS SQS queue, you must convert it to a string. And the easiest way to accomplish this is by using Base64 format to encode binary data to strings when transporting data and decode strings to binary data when storing the data. For an example of Base64 and DynamoDB, refer to this site’s tutorial: Using the AWS DynamoDB Low-Level Java API – Sprint Boot Rest Application.
Station – Producer
Before coding the application, let’s create a queue. You can create a queue via the Java 2 API SDK; however, here we create the queue manually and then use this queue to send and receive messages.
Create SQSQueue
Navigate to the SQS console and select standard Queue.
Click the Configure Queue button.
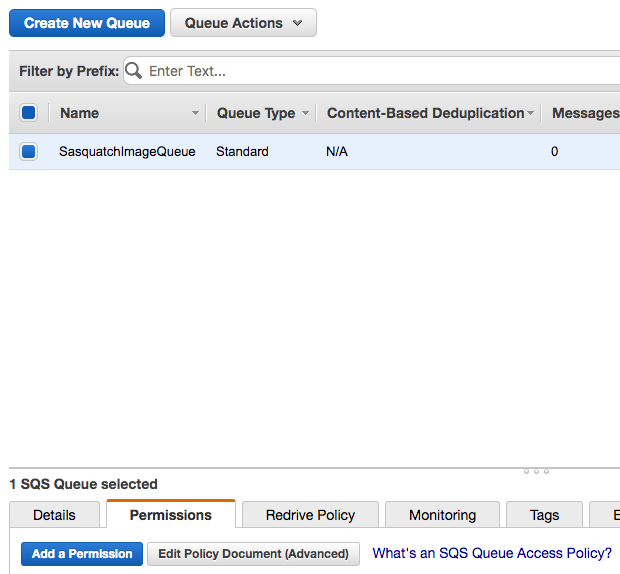
Name the queue SasquatchImageQueue.
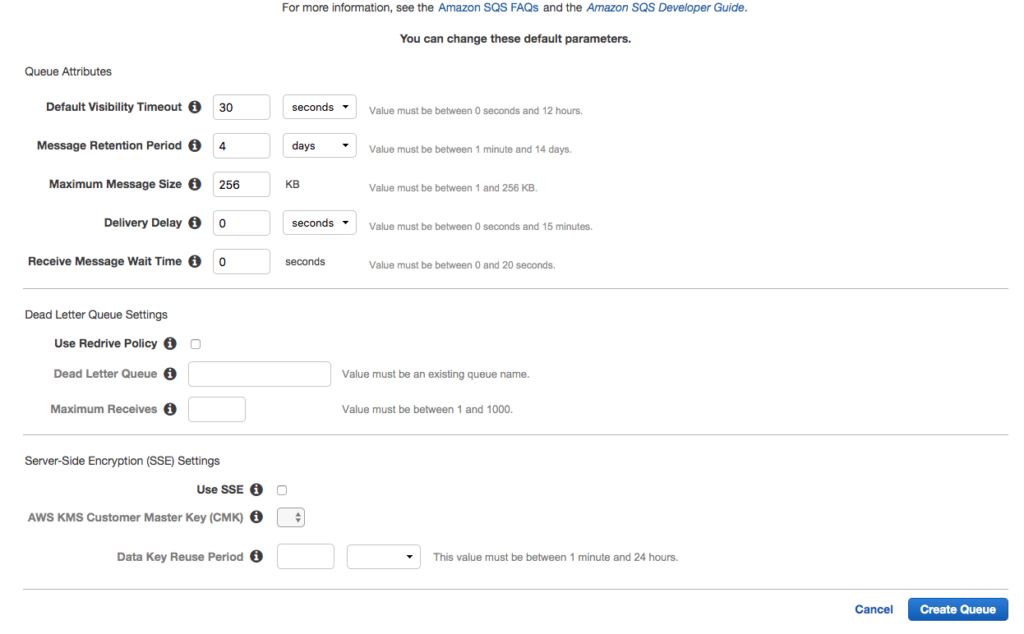
Accept the defaults for the Queue Attributes.
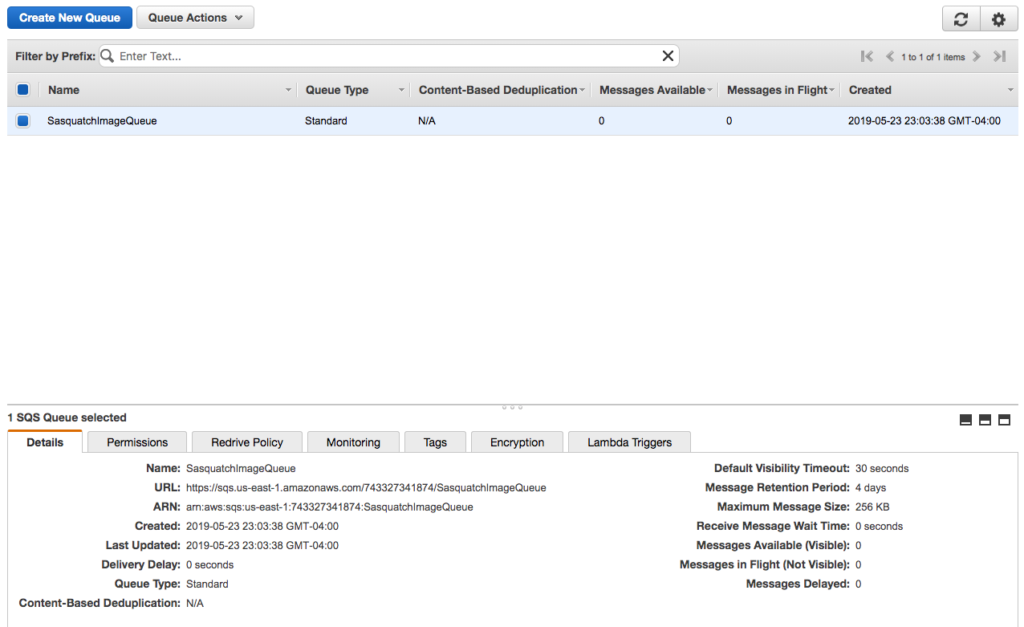
After creating the queue you should see a screen similar to the following.
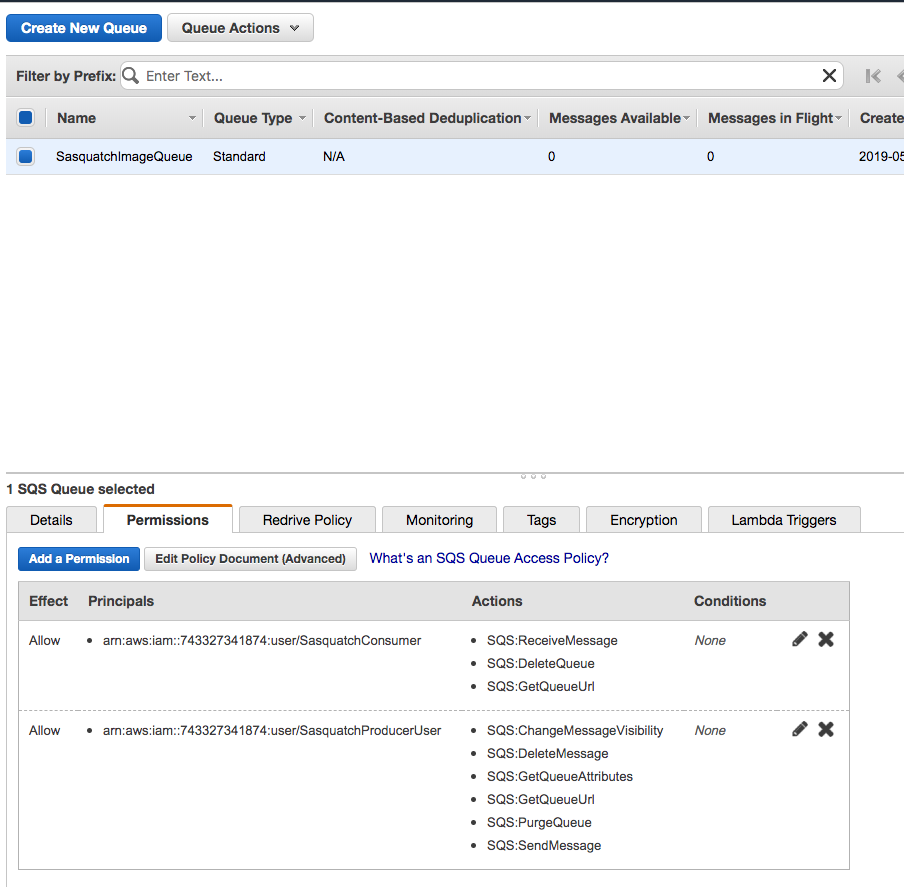
Click on the Permissions tab and notice that we have not created a permission. We return to the Permissions tab after creating the two necessary users.
There are two types of queues offered by AWS SQS, Standard Queues and First In First Out (FIFO) Queues. Standard queues provide what is called best-effort ordering. Although messages are usually delivered in the order they are received, there are no guarantees. Moreover, messages can also be processed more than once. FIFO queues, in contrast, guarantee first in first out delivery and processing only once.
In this tutorial we primarily use standard queues. However, toward the end of this tutorial we illustrate using a FIFO queue.
Create SQSQueue Users
We need to create two users, one to interact with the queue for sending messages and another for receiving messages. If you have created IAM users before, note we do not assign the user to any group or assign any policies. Instead, we allow the queue to determine its permissions. Of course, we assign the user programmatic access and download the credentials file.
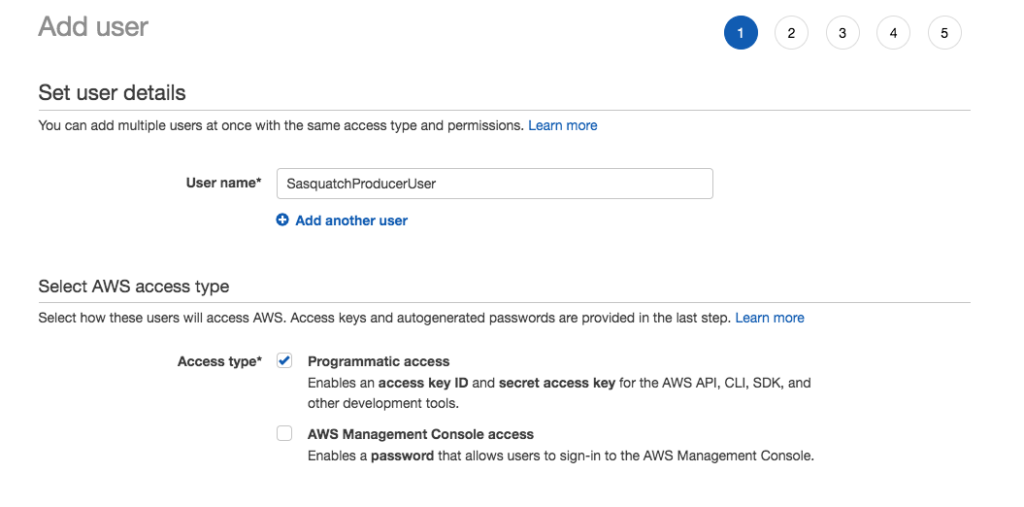
Navigate to the IAM console and create a new user called SasquatchProducerUser that has programmatic access.
Save the user’s credentials locally.
Create a second user called SasquatchConsumerUser that also has programmatic access.
Save the user’s credentials locally.
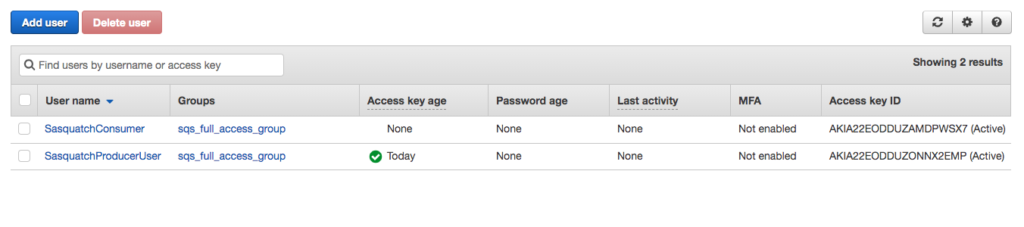
You should have two users created with programmatic access.
Queue Permissions
Initially only a queue’s creator, or owner, can read or write to a queue. The creator must grant permissions. We do this using a queue policy. We write the policy using the ASW SQS Console, although you write it manually if you wished.
Consumer Permissions
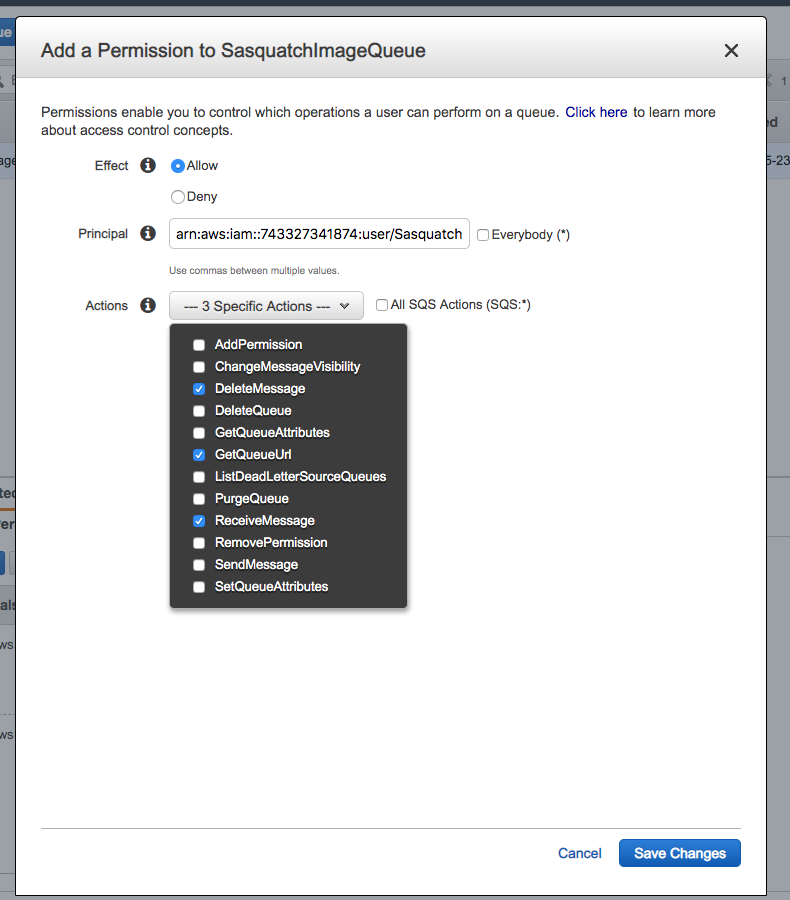
Navigate to the SasquatchConsumerUser summary screen and copy the Amazon Resource Name (ARN).
The ARN should appear similar to the following.
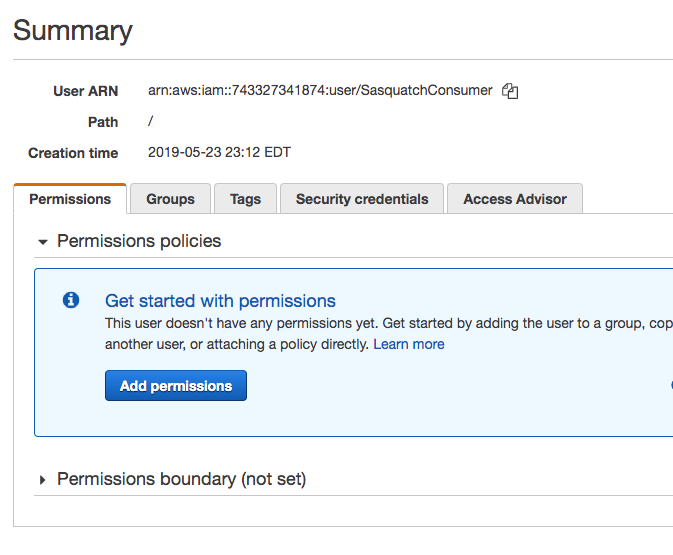
arn:aws:iam::743327341874:user/SasquatchConsumer
The Amazon Resource Number, or ARN, uniquely identifies an Amazon resource, in this case, the SasquatchConsumer user.
Return to the SQS console and select the SasquatchImageQueue and click on the Permissions tab.
Click Add a Permission.
In the resultant popup, paste the ARN in the Principal text box.
Check the DeleteMessage, GetQueueUrl, and ReceiveMessage Actions.
Click Save Changes.
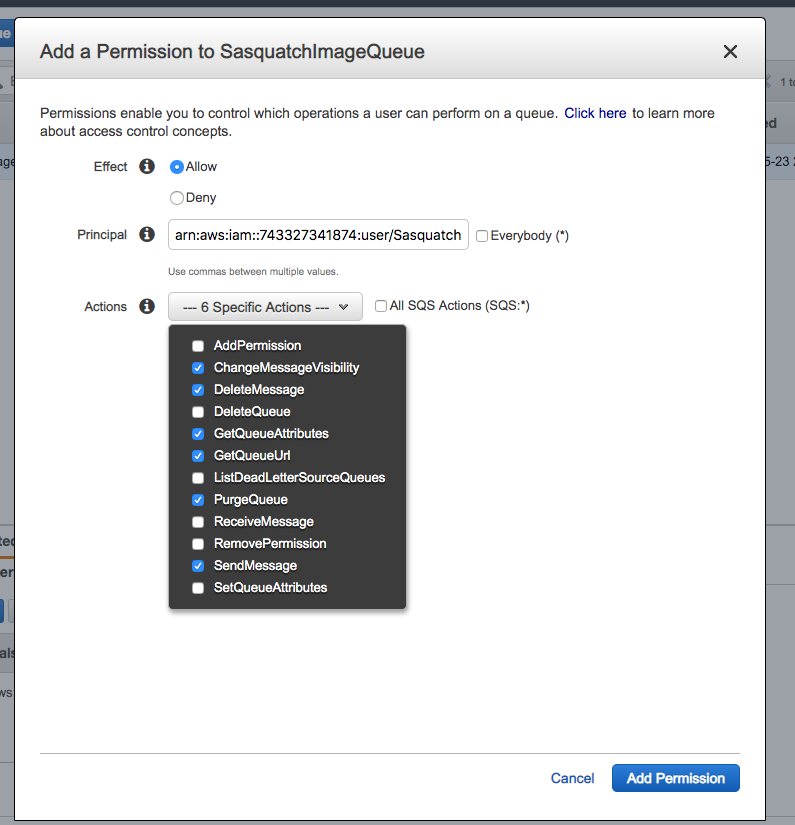
After creating the SasquatchConsumerUser, navigate to the SasquatchProducerUser and copy the ARN for the producer.
Navigate back to the SQS Queue and add this user to the queue as a permission. Allow the ChangeMessageVisibility, DeleteMessage, GetQueueAttributes, GetQueueUrl, PurgeQueue, and SendMessage Actions.
After adding the permissions for both users the queue should appear similar to the following image.
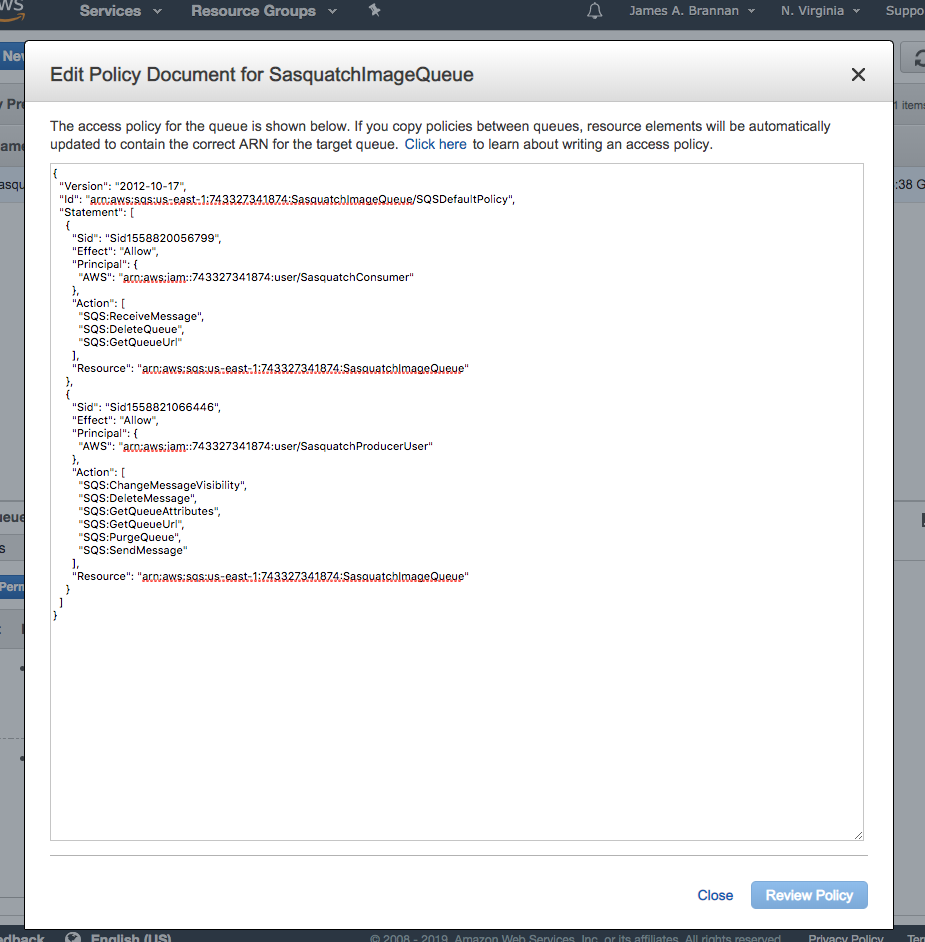
Although we do not discuss Policy documents, the following illustrates that a JSON document underlies the settings we set using the console. It is, however, important you understand policy documents, as they are at the heart of AWS security. For more information on AWS SQS Policies refer to this documentation: Using Identity-Based (IAM) Policies for Amazon SQS.
One thing to note is that here we assigned permissions to the queue using AWS SQS rather than the consumer or producer user we created. We could have just as easily used an IAM Policy, as the documentation in the link in the preceding paragraph discusses.
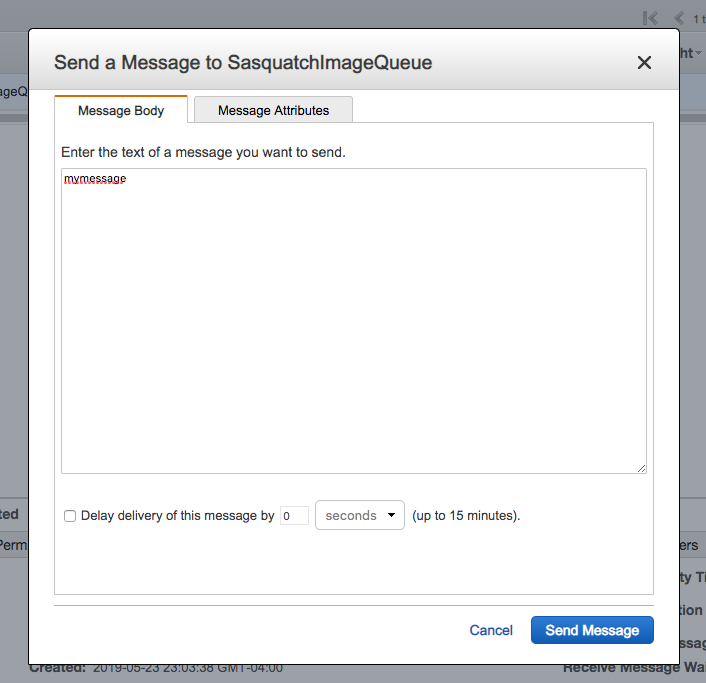
Sending Message Via Console
Although there is probably rarely a business reason, for testing purposes you can manually add a message to a queue. Although we will not use the message, let’s explore sending a message using the AWS SQS Console.
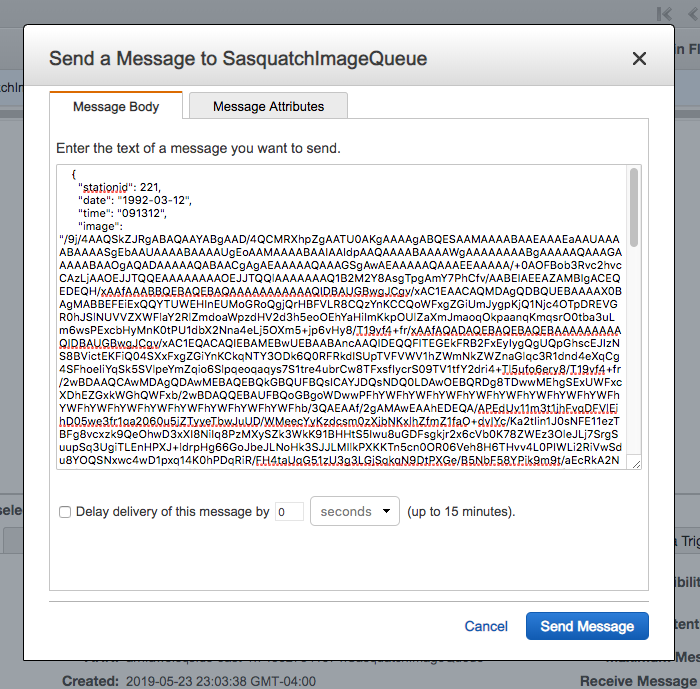
Refer to the observations.json document and copy one of the observations. Of course, in the code listing below the image is truncated.
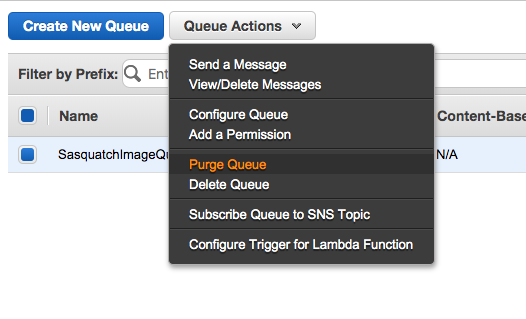
Select the queue and from Queue Actions select Send a Message.
Copy a single message from observations.json and add the entry to the Message Body.
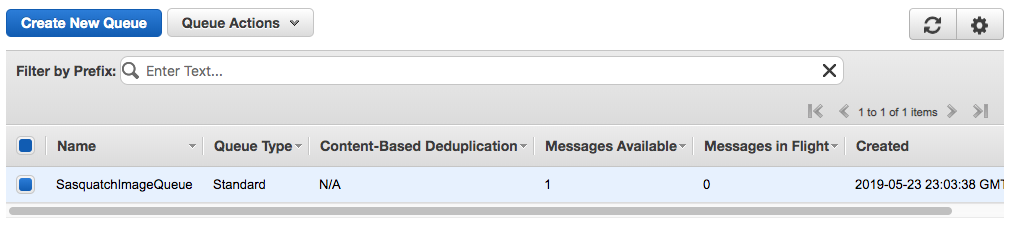
Click Send Message and within a minute the Messages Available column should show one message on the queue.
Purge the queue by selecting Purge Queue from Queue Actions.
Java Project – Producer
As discussed, a producer, well, produces messages. If we fully implemented the design above we would have many Stations and many . However, to keep the tutorial simple we limit ourselves to one Station in one project.
Project Setup
Although I developed the tutorial using Eclipse, you can use your own IDE or even the command-line. However, you really should use Maven or Gradle. Here we use Maven. It is assumed you are familiar with using Maven to build Java projects.
In the POM we use the AWS BOM so we can avoid specifying AWS library versions. We add dependencies for the required AWS libraries. We also specify that maven is to build an executable jar with the required dependencies packaged in the jar.
If we do not specify Java 1.8 or higher, the compilation will fail, as the AWS builders are static interface methods that do not work with older Java versions. Although on your machine, the code might compile, you could have issues if you have multiple Java SDKs on your computer. By explicitly setting the version, source, and target we avoid any potential issues with compilation.
Station
Let’s create a simple executable Java class named Station. This will simulate a bona-fide message producer.
First create an com.aws.tutorial.sqs.main package.
Create a class named Station with a main method in the created package.
Have the main method printout a message that the class executed.
package com.aws.tutorial.sqs.main;
public class Station {
public static void main(String[] args) {
System.out.println("Station running....");
}
}
Executable Jar
Compile and package the project. If running from the command-line you would type the following.
$ mvn clean compile package
After building, execute the program from the command-line. The printout should appear.
$ java -jar SQSTutorialProducer-0.0.1-SNAPSHOT.jar
Station running....
Now that we have created the consumer’s basic structure, we can modify it to send an SQS message.
Sending A Message
In this example we send a message to the queue using the SDK. The data payload is a string of JSON data. You use hardcoded data to send to the queue. Obviously in a real-world application the data would come from a different source. To simulate sending messages from a bona-fide producer, a delay is introduced between sending each message.
Before modifying the program, create a new class named TestData in the com.aws.tutorial.sqs.main package.
Copy three observations from the observations.json file.
Or, if you do not wish escaping the strings yourself, use the TestData.java from this tutorial’s Git project. Note: if you use Eclipse, it will escape the strings for you when you paste the string immediately after the opening quotation. The image’s base64 code is shortened so they can be easily displayed.
Compile and run the application and you should see the following output.
Station running....
sent message: b861220e-a37a-424d-880c-5dd67a052967
sent message: 5185e68b-a16f-4300-8ee5-7ef5cca0eb53
sent message: 161f7444-ae7b-4890-b022-0447933054c3
Navigate to the queue in the AWS Console and you should see three messages in the Messages Available column.
The consumer has only one SqsClient instance that is initialized in the Station constructor and closed in a method annotated with the @PreDestroy annotation. This annotation is used to mark a method that should be called when a class is about to be destroyed for garbage collection.
Credentials
The client requires credentials to operate. This is the user account that the application uses to authenticate itself to the AWS SDK. Here we hardcode the credentials for simplicity. For more information on AWS Java 2 SDK and credentials, refer to SDK Documentation.
SqsClient
The SqsClient is an interface that extends SdkClient, and is the client for accessing AWS SQS service. You use the SqsClientBuilder to build the client. You build the client by passing the credentials and the region.
All requests to SQS must go through the client. Different types of requests are named accordingly. For instance requesting to send a message requires a SendMessageRequest, requesting to delete a message requires a DeleteMessageRequest. If you have worked with the other services offered by the Java 2 SDK such as DynamoDb or S3, then this pattern should be familiar.
SendMessageRequest
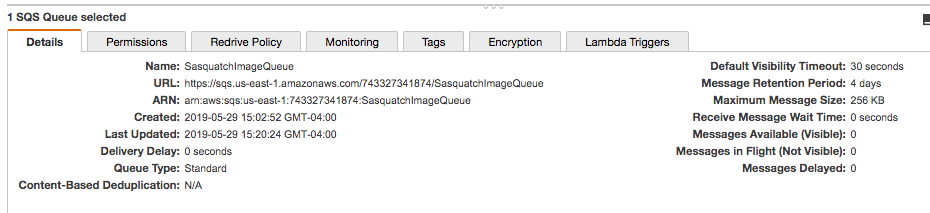
The SendMessageRequest wraps requests to send messages to the client. You build the request using a SendMessageRequestBuilder. Above we are setting the queue’s URL, the message’s body, and how long to delay before sending the message. We obtained the queue’s URL from the AWS SDK Console.
The URL is in the Details tab of the queue in the AWS Console.
SendMessageResponse
The client sends the request and receives a response. The SendMessageResponse wraps the response. The method then returns the messageId and main prints the value to the console.
Now that we have created three messages and sent them to SQS, we can write a consumer to consume the messages. Now let’s create a Java project named SQSTutorialConsumer.
Java Project – Consumer
Consumers, well, consume messages. Let’s create a consumer for the messages on the queue. As with the producer, we greatly simplify the consumer by creating an executable class that runs from the command-line.
Project Setup
Let’s create a Java Maven project for the Consumer.
POM
Create a Java project named SQSTutorialConsumer as a Maven project.
Navigate to the queue in the AWS Console and you should see no messages, as they were deleted after processing.
In this simple consumer we first create a client for interacting with the queue. We then obtain a single message from the queue. The program pauses to simulate processing. It then deletes the message from the queue by using the receiptHandle.
Because the program loops, it processes all three messages place on the queue when we created the consumer.
ReceiveMessageRequest
The ReceiveMessageRequest wraps the request to receive a message from an SQS queue. We use a builder to create the request. Then we specify the queue URL and the maximum number of messages to fetch. Finally, we specified a single message; however, you can specify multiple messages if desired.
After processing the message you should delete it from the queue. We do this by obtaining the receiptHandle of the received message which is then used to delete the message.
The program processes all messages on the queue. This is a simple consumer, but you could have multiple consumers consuming messages from the same queue.
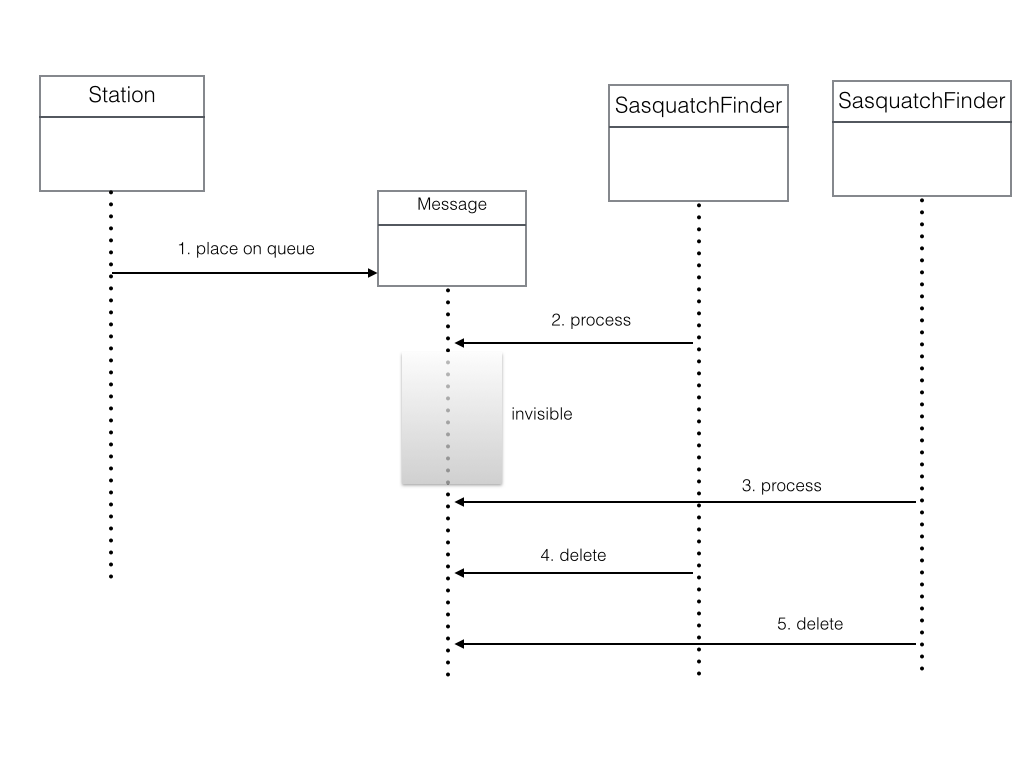
Message Visibility
A message might be processed twice when using a standard queue. A message, when picked up by a consumer for processing becomes invisible for a configurable time. When we created the queue we accepted the visibility timeout of 30 seconds. However, if processing takes longer than the visibility timeout, the message can be processed by another consumer. The following diagram illustrates.
There is a following wrinkle. What happens when the message is deleted from the queue a second time?
Open the SQS Console and send a single message to the queue.
Modify SasquatchFinder to sleep for 40 seconds between each message.
After building the application, open two command-line windows and execute the program in the two different windows at the same time.
One running instance gets the message from the queue. The message’s visibility timeout set at 30 seconds begins. The instance sleeps for 40 seconds to simulate processing.
Meanwhile, the instance that first picked up the message finishes processing and deletes the message. In reality, it attempts to delete the message. But, as the other process already requested the message and a new receipt handle was issued, the message is not truly deleted.
$ java -jar SQSTutorialConsumer-0.0.1-SNAPSHOT.jar 2
SasquatchFinder 2 running....
mymessage
sleeping for 40 seconds...
Deleted message AQEB3/lhW8cY2cTsl2gd/GOsyPrt1J/SQn+ZR06ngf24aL5C8SqfUSPZfAl4uc2IwuZuLhZ/5BXYLWVU7AvmgSf0kb4zm0owKh01EXC4pGhvtNSsioLnk3nd4KiS5YEUO/EssCnRM1we7rXw0eLyd2LehOpPOZ49893lIJ6opy1vamQxxk6C+7iGcWbY0dMNTvrZqVaZw2JW/eZV5wI99rdUwRP16+RFj7XWsxEI5KJcExgnWY3jDRQv1mXqe5ZgWI9M7mqPH/rrx8afBdV2P53B7OK0uRm3vUGMzmW/xUgbsxsy5UB0+DZGLaccUAbegtC74LQ6BLZs64VlFxc8jAC2sp2gheLAZ849j4JkMrA8nWf+P+xKCjqdALeGrN754DcxnvhZv79R6sOGcp2lBtTOsA== by SasquatchFinder 2
As the message is still being processed by the second instance, the first does not see the message. The second instance then deletes the message.
$ java -jar SQSTutorialConsumer-0.0.1-SNAPSHOT.jar 1
SasquatchFinder 1 running....
mymessage
sleeping for 40 seconds...
Deleted message AQEBgZK7kq12asCcVVNbFQNlQmmgYTXXO8OzgoJzHpAnqdsBtMnaBxSBvjjgyVqO3nqYwuhFoxPWgXhUoUcgDzejHHSG6dM/VNG1Wdv3Q93THsJPj6BSQSH/sLjX7qvdFYT20Es0jdhN4dQTNMPyaA3sA7a2x025cUYLsegKfMlWVfCDThABbn+0evwgkn3hmzwLBvAWZEGIp0mooZvYf6WiLcblbqCnx+Gh5j5/XvmIpWuT9ux3DQSTYH+f+XdfUxclXP6exwAYyyFm7xHJnlF9LXcRcKmv2QitpQjgjK3yQBLrogU6dPf8Zp34K8iwMr1TBXEi5mZnfPSA7Cl3a4N2c+MxB+OupGIGGY6uoy2gFLSiaaunsij/weB0FFaYaE/MFhMsXdMMhNho2o/lrq6SOA== by SasquatchFinder 1
Notice that both messages have a different receiptHandle. The queue has an internal mechanism to avoid errors when a message is processed and subsequently deleted twice. However, it does not prevent processing a message multiple times. If we manipulated the processing time and/or the visibility timeout, we could have the message processed even more times.
To actually delete the underlying message, the most recent receipt handle must be provided. So in our example above, the first attempt to delete the message came after the second receipt handle was returned and so the message was not deleted. But the second attempt to delete the message was the most recent receipt handle and so the message was deleted. To delete a message you must pass the most recently issued receipt handle.
You should design your system to not be dependent upon the number of times a message is processed. Your system should be idempotent. If you need strict processing of once and only once, then use a FIFO queue.
Message Attributes & Dead Letter Queue
Let’s explore two topics important when working with AWS SQS queues: message attributes and dead letter queues. A message can have associated metadata. However, to receive messages with associated metadata the ReceiveMessageRequest must be explicitly instructed to fetch the associated metadata in addition to the message itself. A message might not be successfully processed. Rather than leaving the message on the queue to fail indefinitely, a dead letter queue can be configured to send message that fail a configurable number of times.
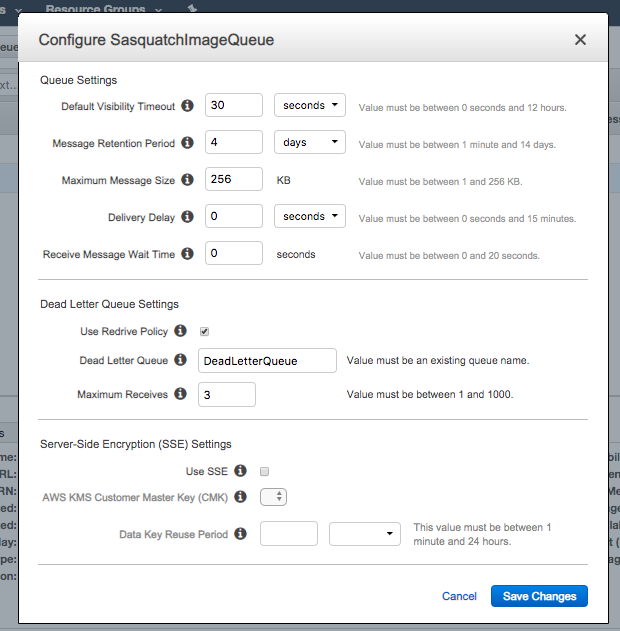
DeadLetter Queue
Create a new standard queue named DeadLetterQueue.
SelectSasquatchImageQueue and from the Queue Actions dropdown select Configure Queue.
Modify SasquatchImageQueue to use DeadLetterQueue for its Dead Letter Queue.
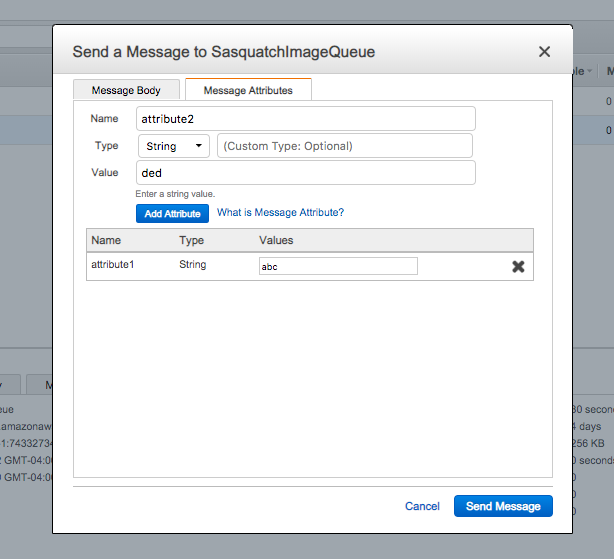
Message Attributes
Select SasquatchImageQueue and send a new message.
When creating the message, add two message attributes.
Open the SQSTutorialConsumer project and modify the processMessage method in SasquatchFinder. Note that you comment the call to delete the message.
Compile and run the application. The message should process three times.
SasquatchFinder 1 running....
abc
e6ede972-9a6d-4c86-8c00-b16fe18977ff
attribute1:abc
attribute2:ded
sleeping for 10 seconds...
abc
e6ede972-9a6d-4c86-8c00-b16fe18977ff
attribute1:abc
attribute2:ded
sleeping for 10 seconds...
abc
e6ede972-9a6d-4c86-8c00-b16fe18977ff
attribute1:abc
attribute2:ded
sleeping for 10 seconds...
Return to the AWS Console and you should see that the message is placed on DeadLetterQueue.
To receive message attributes we were required to build the ReceiveMessageRequest with the explicit instruction to receive the message attributes by specifying messageAttributeNames. That method can take one or more attribute names, or a * to signify all attributes.
The message was sent to DeadLetterQueue, the queue configured as the SasquatchImageQueue dead letter queue.
The ReceiveMessageRequest can receive more than one message at a time if more are available on a queue. Above we set the maximum number of messages as one. Let’s explore what happens we change the setting to more messages.
Modify the SasquatchFinder class by creating a new method called deleteMessages.
Have the method iterate over all received messages.
After compiling, navigate to the AWS SQS Console and add five messages to the queue, with the message body of a1, a2, a3, a4, and a5 respectively.
Run the application and you should see output similar to the following.
SasquatchFinder 1 running....
a4
98a42736-e4b5-4dfd-9428-3e32d2ea145d
sleeping for 10 seconds...
Deleted message AQEBqmAqpGs85ERM2Y8EnD4zjBPO1KxomlhJgQCPQ+JO3gjYhRcZbflS1gKJT1kas0JId7bX4X+OmFWQfC8r+gZGr02jwBcKlhvSUIv0tx13Q88EPpzMJDNbB9w9oKbgR+hc8c0nZQPPjJ2uHu7KeQfTmIdK/dt49cs/GHFRZeq3pIUWN2jJO8h0UdlpLeFKbB96WjPvakAnXDFd46meejQvBod0x18L1Y1dBt6cZc5+9AbB6eb4bJjV5dKvyDCtIUP2XFZ8iwtZF1lxntzqXxdMGYCjzaQ/oqQ5EmVJ/pFMTgWlUTks+qVFMu7a/sOCfQm7bFwE3AofXQROAK3B0crssZTbzoqQ9oJv+nj0kn596gidN+gygrISvF9vESIG1M5Ll+Lk2ADWQeO+2UA/AJax3A== by SasquatchFinder 1
a1
a5
c167bb7a-f356-4d5b-aa0f-ea90075cef50
f0d79263-05da-485e-bf6a-fa6b3f9fe92a
sleeping for 10 seconds...
Deleted message AQEBGwtlQPM080KnHDAOWUsZKUQ4PWfLP2g/AFn0sr9ERDOJFssjl7rNXl3mL6ryqoH9EgiPEGyGXwPm6n/FSsfbPA9OSMJYLq0Fho9qtpkcoI0mmAqRPQ/7h0J++zAmmf3bflcD9BqJS+hz4a/Di8Eo6GB0oWJUFZEFYcKWnIUGMNgnQfY3xs1DF9UuNZdsu7h3KN9hGGy3vSTuLvJJox7DDHSgY+QU3nisT5dTSfltKc9vJMQq2mPxB/f2EUmgwKQ82f10A6lPlSjVuiyNtGkKVau3BorKINz3dtG+xAHd5wWfALFExyip7zFZl6wVsnzfKox9QBaxRSrukIfx3+w5rIilq1QujPpNqLKItlxOvaXvDvxi/8lWv31S5UNlY7ooEOYSIkh1wnNwXKY7ZP4aQQ== by SasquatchFinder 1
Deleted message AQEBLIUJqmODdigrnQ88hzta9Zr+PaQnctLqmYrQT0iU5ZxvaLPy0PGNTe7eKwLHbBvc+WdDbLXK951WaPYWoY9dbMJZMyRNnjEj3doGoUkmBOm0LzTs1xDkV+QPb3fGH3s+mxh2TFhX3KFOwXrvf4uqkpx9mHdGioMWa86NSsCUUEQ3vXGUXprSdGsSqXUsoAug7v6wBU3QIPzeQm8pRLmjbZPdx+ndeV80FwnFkxDfNx/mtpAibum4ON4CxDUB66jLC7nVRe0XxXBllM2G/brS7jseqbz+Q61qbFjLNWKo96kTBIrYDjvZEmcSQdp37cYMf4rO/vsr+/XCNUtbtcD8h9Xk8Fc+atcIsuQSlrLbYMplVgN3EwogYlXJsB9GSOlVQVpO+gwOLBXonXJ6i3EAbQ== by SasquatchFinder 1
a2
a5
e65fbcc2-2c4a-42f6-8b61-ca97dad4826e
b2bc665c-4c1c-42c7-b3d2-c1d5bf048ee9
sleeping for 10 seconds...
Deleted message AQEB2FZyDGQEOUgLxR9wIxAiJbk++Ktec9RLon3nAZr7bPeQu2QJ8iVxRMNg92ZgvoPY5qsBndcRGEQjI5zKHQ/r62tg4+LMWwFLSDBhDF3d55w6OosgLf+K7AIBICGAeTJanTkhCzQlWYM+HCDFEve+NhPsr5+/zabaeZrkKwSBh8E2jTCmr29LmNR6ld9Bz0NSboj5gi+Gxa3dTu+xPGMLMjANVQ1Qa1BhoYEI0QP8kl9gL8aBpLhkeW1eWXgRaRtRcTAVpjxF73ZlUEFVNyYeE/Mwz9ZT2lWRftj6dv5p2PUG5Z6VtbbBw/9AXQElJUTgfHKGd4iGEjo4A3l6ff6g/NVJzm/LkGq6909txbTIk8PSp5istS4bM318W6VG2ten9jYSU7+pj8H809AHoW3VEw== by SasquatchFinder 1
Deleted message AQEBMdzd33/uz7jNQMnBJu1ne7GRh9g2xHx6X0cPWLsU0emEN0G5SGbr3nF/9QklDrrW42BX1HW6IDWxvhlI4/bOByZobYOfjmv5Cr8rDEJYnNKWxqxBZeQqjArKTy90WeEs0puUw4l6PouEZOv35daHO0h01A8Dpk/oMlVBi/OZFCIM4fetG2tUxwa7eU15WiEF4mklZqqJx2bVTbdiZqwhOucgqXlyXK3IJ5FtBFd6ACtEyX1tQmIBn6njmk/CBuX0v5+LzaxlntHy9Q+FpjuPLEyyE5wGqIk9B8Kcqv469pnaE3UJJaCK7DxgG70rF/7M1kYzaDRbRBYJB9jS3W9b8qZpj1JU4JM4euH9xBP4j59MvdwgIs4lSPvO1F3NtdCuNeOOMF15/n1WvU2U31jSeg== by SasquatchFinder 1
As the example illustrates, you can specify the maximum number of messages to process, but not the number of messages. This should seem reasonable, as the consumer does not know how many messages are in the queue before processing. As an aside, note that the messages were not processed in the same order they were received in the listing above.
First In First Out (FIFO) Queue
Let’s modify the project to use a FIFO queue and rerun the two consumer instances simultaneously. Note that neither the consumer nor the producer know they queue’s type. They only know it’s url.
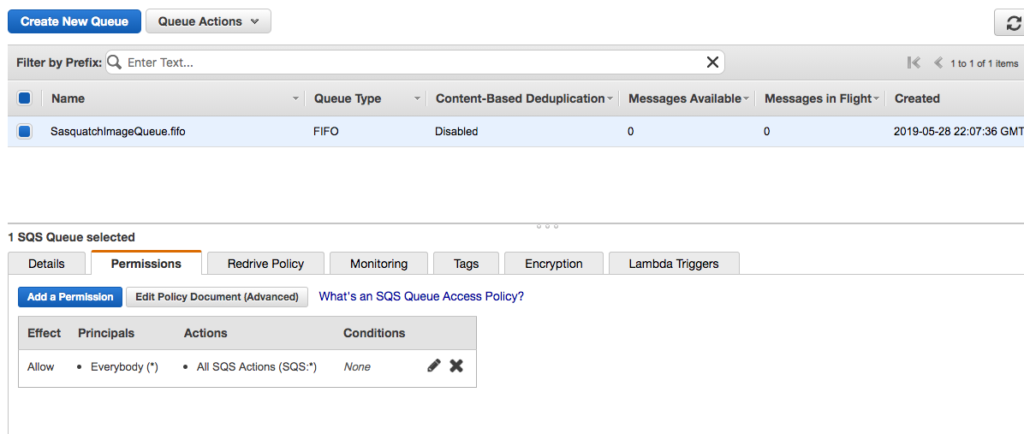
Create a new queue named SasquatchImageQueue.fifo of type FIFO Queue.
Click Quick-Create Queue.
Create a new permission, but let’s be lazy and check the Everybody checkbox and the All SQS Actions checkbox. You would obviously not do this in production.
Modify both the consumer and producer to use this queue’s URL.
Compile and run the application. Note you get an SqsException.
SasquatchFinder 2 running....
messageMine
sleeping for 40 seconds...
software.amazon.awssdk.services.sqs.model.SqsException: Value AQEBBJL+BlwyhRLnQGxaIKDkkrEv1sU6VnHzYM51Q0UFdx2lDyWvKoI/JYcs7MktVJ1Nmyr1mCVX/cpcqS9dMqq7Ual92VLEXDS9hEYM/qg1vdEGHB60OktMzpidyWBenQQyybzXofO+pAdKOYpC/wiEw8GBPsmFDCHpVn1hxHeLSNJyw10SwNv3DTXQXk4Pe+v3yGf23bf8sDk7Rx7ApqWYi8n8z9uijZAQBdwuFpUrZslivMWCzid6AFOXI/k83+/tKnSMyT0/Mx0rng0v1k4WliSgv5YJo5HyEZTt+cOBwfA= for parameter ReceiptHandle is invalid. Reason: The receipt handle has expired. (Service: Sqs, Status Code: 400, Request ID: 845b9538-4104-5428-aa2f-c05092244385)
at software.amazon.awssdk.core.internal.http.pipeline.stages.HandleResponseStage.handl <snip> at com.aws.tutorial.sqs.main.SasquatchFinder.main(SasquatchFinder.java:58)
SasquatchFinder 2 stopped.
Attempting to delete messages fail when executed after the visibility timeout window if using FIFO queues.
Conclusions
In this tutorial we created an Amazon SQS Queue. After creating the queue, we created a message producer and a message consumer using the AWS Java 2 SDK. We then explored several topics such as message attributes, dead-letter queues, and message visibility. We also created a FIFO queue.
Amazon’s SQS Queue is a easy to use queue that takes the infrastructure management hassle away from the organization. In this tutorial we only examined SQS basics. For more information, refer to both the Java 2 SDK Developer’s Guide and the SQS Developer’s Guide. Remember, the API from version 1 to 2 changed, so when in doubt, assume you need a builder for an object and that you must configure the object when building it. However, the API is consistent and once you start working with the API translating 1.1. code to 2 is intuitive.
In this tutorial we use the Amazon Web Services Java 2 Application Programming Interface (API) to create a Rest application using Spring Boot that reads and writes to a DynamoDB database. This tutorial assumes AWS familiarity, Java programming experience, and Spring Boot experience. However, even without this experience, this tutorial should still prove useful, as it provides considerable supplementary resources for you to review. If you want to learn the AWS DynamoDB Java API then this tutorial is for you.
Here we create a simple database consisting of “observation stations” and “observations” gathered via a camera. Whatever…suspend disbelief and just go with it. Now, suppose, the stations require a means of uploading observations to an associated DynamoDB table. We decide upon a Rest API for stations to upload data. We implement this API using a Spring Boot Rest application. Again, if this all sounds suspect, suspend disbelief and focus on the AWS code and not the application design.
In this tutorial we,
create two database tables using the DynamoDB console,
create a couple items using the console,
create an IAM programatic user,
create a Spring Boot application that provides Rest endpoints so a client application can,
write an observation,
read an observation,
update an observation,
delete an observation,
batch write multiple observations,
conditionally query for a station’s observations,
and conditionally update observations,
and test the Rest endpoints using Postman.
This tutorial’s purpose is to explore the DynamoDB, not introduce Spring Boot, Rest, or JSON and assumes basic knowledge of all three. However, if new to any of these topics, links are provided to learn them before continuing.
NoSQL Databases
DynamoDB is a key-value and document NoSQL database. If unfamiliar with NoSQL Document databases, you should familiarize yourself before continuing. The following is an introductory video introducing NoSQL Databases.
The following are two good written introductory articles covering NoSQL and DynamoDB.
Note that Amazon also offers DocumentDB, which we could use as an alternative to DynamoDB. However, DocumentDB will be covered in a different tutorial.
A DynamoDB database can be described as the following. Tables consist of items. An item has one or more attributes. In a table you define the partition key and optionally define a sort key. The partition key is a key-value pair that not only uniquely identifies an item, it determines how the item is distributed on a computer’s storage. A sort key not only logically sorts items, it stores the items accordingly. Obviously, there is more to NoSQL physical storage and how it achieves its scalability, but that is beyond this tutorial’s scope.
Amazon Web Services & DynamoDB
Amazon DynamoDB is a NoSQL key-value and document database offered as a cloud service. It is fully managed and allows users to avoid the administrative tasks associated with hosting an enterprise database. As with almost all Amazon’s offerings, it is accessible via a Rest API.
Amazon offers software development kits (SDKs) to simplify working with the Rest API. The languages offered are Java, C++, C#, Ruby, Python, JavaScript, NodeJs, PHP, Objective-C, and Go. In this article we use the Java API. There are currently two versions of the API, in this tutorial we use the Java 2 SDK.
The Java 2 AWS SDK is a rewrite of the Java 1.1 AWS SDK and changes from a more traditional programming paradigm of instantiating objects using constructors and then setting properties using setters to a fluent interface/builder programming style.
Fluent Interface
The fluent interface is a term created by Martin Fowler and Eric Evans. It refers to an programming style where the public methods (the API) can be chained together to perform a task. It is used by the AWS Java SDK 2.0 when using builders. The builder tasks perform tasks but then return an instance of the builder. This allows chaining methods together. For more information on the fluid interface and builders, refer to this blog post: Another builder pattern for Java.
DynamoDB Low-Level API
As with all AWS APIs, DynamoDB is exposed via Rest endpoints. The AWS SDKs provide an abstraction layer freeing you from calling Rest directly. Above that layer, the Java SDK provides a class named DynamoDBMapper that allows working with DynamoDB similarly to the Java Persistence Framework (JPA). Although useful, using the lower-level API is not that difficult. Moreover, there are many situations where you would not wish to create a dependency in your object model that relies on DynamoDB.
For example, suppose we implemented a system that stored widgets in DynamoDB. If using the DynamoDBMapper, the Widget model class would be dependent upon DynamoDB via annotations mapping the class to the Widgets table.
Alternatively, if we do not wish to use the DynamoDBMapper we can implement something similar to the following diagram. It is a typical DAO pattern, where the only direct dependency upon the AWS SDK is the WidgetDaoImpl class. For more information on the DAO design pattern, refer to the following introductory article: DAO Design Pattern.
In this tutorial on the AWS DynamoDB Java APl, we use the SDKs direct calls to the underlying DynamoDB Rest endpoints. As an aside, note that we do not use the DAO design pattern, instead putting the data access logic directly in the controller class for brevity. We do, however, use the Spring MVC design pattern using Rest.
Imagine we have stations responsible for taking photo observations. A station has a coordinate, address, and a name. A station has one Coordinate. A station has one address. A station can have unlimited observations.
Although this tutorial does not discuss NoSQL database design, from the diagram below it seems reasonable we need two tables, Station and Observation. Moreover, as the Observation table is very write intensive – stations will be sending observations to the application on a continuous basis – it makes sense to not include observations as a collection within a Station instance but keep it as a separate table. Remember, these are JSON documents, not relational tables. It is unreasonable to design Observations as a list of items within a Station and would lead to an excessively large and unwieldy database.
If there were enough Stations, for even more efficiency we might create a separate table for each station’s observations. This would allow greater throughput for both writing and reading observations. But, in this tutorial we simply define a stationid to identify an observation’s station and will create an index on this value.
DynamoDB Console
The AWS Management Console provides an easy web-based way of working with Amazon’s cloud services. Although not covered in this tutorial, for those new to AWS, here is a short video by Amazon explaining the Management Console. Note that AWS also offers a command-line interface and Application Programming Interfaces (APIs) for accessing its cloud services.
AWS Essentials: How to Navigate the AWS Console by LinuxAcademy.
Before beginning the programming portion of this tutorial we must create the DynamoDB database.
Create Station Table
After entering the AWS Management Console, navigate to the DynamoDB console.
Click the Create table button.
Provide Station as the table’s name and id as the table’s primary key.
Creating Station Items
Remember, DynamoDB is schema-less. We create an item but do not define a table’s schema. Instead, we create a couple items with the desired structure.
Click the Items tab and click the Create Item button.
Create an id and name attribute, assigning id as a Number datatype and name as a String. Assign the values 221 and “Potomac Falls” respectively.
Create an attribute named address and assign it the Map datatype.
Add a city, street, and zip attribute as String datatypes to the address map. In the example below, I assigned Potomac, 230 Falls Street, and 22333 as the attribute values.
Create coordinate as a Map and assign it a latitude and longitude attribute as Number datatypes. I assigned the values 38.993465 and -77.249247 as the latitude and longitude values.
Repeat for one more station.
We created two items in the Station table. Here are the two items as JSON.
You can view the JSON after creating an item by selecting the item and then selecting the text view in the popup.
Note that the preceding JSON document is generic JSON. The actual JSON, as stored by DynamoDB (including datatypes), is as follows. Where the M, S, N, SS, etc. represent the element datatypes.
For example, in the following JSON document an observation’s address and coordinate are both Map datatypes, the city, street, zip are String datatypes, and the latitude and longitude are Number datatypes.
You can toggle between JSON and DynamoDB JSON in the popup window, as the following illustrates (note the DynamoDB JSON checkbox).
Create Observation Table
After creating the Station table we need to create the Observation table.
Create a new table named Observation.
Assign it a partition key of id and a sort key of stationid.
Composite Key (Partition Key & Sort Key)
The partition key is a table’s primary key and consists of a single attribute. DynamoDB uses this key to create a hash that determines the item’s storage. When used alone, the partition key uniquely identifies an item, as no two items can have the same partition key. However, when also defining a sort key, one or more items can have the same partition key, provided the partition key combined with the sort key is unique. Think of it as a compound key.
The Sort key helps DynamoDB more effectively store items, as it groups items with the same sort key together (hence the name sort key, as it sorts the items using this key).
An observation should have an id that identifies it and observations should be sorted by station, so we defined a stationid as the table’s sort key.
Create Sample Observations
As with the Station table, create some Observation items rather than define a schema.
Find three images, of small size, to use for this project. If you wish, use the three sample images from this tutorial’s Git project.
Or, if you wish, simply use the JSON sampleData.json file provided in this tutorial’s Git project.
The following is a JSON list of four observations. The image base64 string is truncated so it can be easily displayed here. You can obtain the original file, named observations.json, from this tutorial’s Git project.
Images are binary. However, all binary can be represented by a String provided it is encoded and decoded correctly. Base64 is an encoding scheme that is converts binary to a string. It’s useful because it allows embedding binary data, such as an image, in a textual file, such as a webpage or JSON document. DynamoDB uses Base64 format to encode binary data to strings when transporting data and decode strings to binary data when storing the data. Therefore, the image sent to the Rest endpoints we create should be base64 encoded.
Create IAM Application User
Before beginning the Spring Boot application, we need a user with programatic access to the AWS DynamoDB API. If you are unfamiliar with IAM, the following introductory video should prove helpful. Otherwise, let’s create a user.
Navigate to the IAM Console and click Add user.
Create a new user named DynamoDBUser.
Assign DynamoDBUser with Programmatic access.
Create a new group named dynamo_users with AmazonDynamoDBFullAccess.
Assign DynamoDBUser to the dynamo_users group.
If you created the user correctly, you should see the following Summary screen.
Save the credentials file, credentials.csv, to your local hard-drive.
Spring Boot Application
Now that we have created the two needed tables and created a user we can begin the sample application. We create a Rest API for stations to save, retrieve, update, and delete observations. Not much explanation is devoted to Spring Boot, so if you have never created a Spring Boot Rest application you might consider completing a tutorial or two on Spring Boot and Rest. The following are links to two tutorials; however, there are many more on the web.
In the POM we define the AWS Bill of Materials (BOM) and the required AWS libraries. Note that when using a BOM it is unnecessary to specify the library versions, as the BOM manages versions. We also define the Spring Boot libraries required.
Create an application.properties file in the resources folder. Open credentials.csv and add the credentials to the file with the following property names.
NOTE: THIS USER WAS DELETED BEFORE PUBLISHING THIS TUTORIAL.
Create a new class named SiteMonitorApplication in the com.tutorial.aws.dynamodb.application package.
Annotate the class with @SpringBootApplication annotation.
Create the main method and have it launch the Spring Boot application.
package com.tutorial.aws.dynamodb.application;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.ComponentScan;
@SpringBootApplication
@ComponentScan({ "com.tutorial.aws.dynamodb" })
public class SiteMonitorApplication {
public static void main(String[] args) {
SpringApplication.run(SiteMonitorApplication.class, args);
}
}
Create Observation Data Object
Create a class named Observation in the com.tutorial.aws.dynamodb.model package.
Create variables with the same names and types as in the JSON data created above.
package com.tutorial.aws.dynamodb.model;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import java.util.List;
public class Observation {
private long stationid;
private String date;
private String time;
private String image;
private List<String> tags;
public long getStationid() {
return stationid;
}
public void setStationid(long stationid) {
this.stationid = stationid;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
public String getImage() {
return image;
}
public void setImage(String image) {
this.image = image;
}
public void setTags(List<String> tags) {
this.tags = tags;
}
public List<String> getTags() {
return this.tags;
}
@Override
public String toString() {
try {
ObjectMapper mapper = new ObjectMapper();
return mapper.writeValueAsString(this);
} catch (JsonProcessingException e) {
e.printStackTrace();
return null;
}
}
}
The Observation object’s attributes are the same as in the JSON Observation document. Notice in the toString method we used an ObjectMapper from the Jackson library. We did not include this library in our POM, as the spring-boot-starter-web library includes this library.
The ObjectMapper maps JSON to Objects and Objects to JSON. It is how Spring Rest accomplishes this task. In the toString method we are telling the ObjectMapper instance to write the Observation object as a JSON string. For more on the ObjectMapper, here is a tutorial that explains the class in more depth: Jackson ObjectMapper.
Create Rest Controller
The Rest Controller provides the external API visible to Stations to send data to our application. Through the API, client applications will transmit data to the DynamoDB database. Different stations can develop its own client application in any language that supports Rest. The only requirement is that the station’s data follows the expected JSON format.
Note: we are violating the MVC Design pattern by putting data access directly in the Controller. Suspend disbelieve and ignore this anti-pattern.
Let’s create a Rest Controller to define our application’s API.
Create a class named ObservationApiController in the com.tutorial.aws.dynamodb.api package and annotate it with the @RestController annotation.
Assign it a top-level path of /observations.
Create a Rest endpoint for uploading a new Observation. Assign it the /observation mapping and name the method createObservation.
Have the method take an Observation as the request’s body.
Have the method print the uploaded Observation to the command-line.
package com.tutorial.aws.dynamodb.api;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.tutorial.aws.dynamodb.model.Observation;
@RestController
@RequestMapping(value = "/observations")
public class ObservationApiController {
@PostMapping("/observation")
public void createObservation(@RequestBody Observation
observation) {
System.out.println(observation.toString());
}
}
Compile the application using Maven and start the application.
After the application starts, we can test using Postman.
Test using Postman
Postman is a useful tool for testing JSON endpoints. If you have never used Postman, you might consider completing a couple tutorials first.
Create a new request named AddObservation that exercises the Rest endpoint.
http://localhost:8080/observations/observation
Place one of the observations from the previously created JSON document in the request’s Body. Assign the type as JSON (application/json).
JSON Request in Postman for saving Observation.
Click Send to send the request to the Spring Rest endpoint. If everything is correct, you should see the Observation as JSON printed to the command-line.
Copy the image base64 string and navigate to the CodeBeautify website’s Convert Your Base64 to Image webpage. Paste the string in the provided textarea and click Generate Image. If the base64 string was sent correctly, you should see the same image you sent to the Rest endpoint.
Create DynamoDB Client
Now that we have the basic Spring Boot application in place, we can start building the actual API to DynamoDB. But before working with DynamoDB, we need to create a DynamoDBClient instance.
Create a class named ObservationService in the com.tutorial.aws.dynamodb.service package.
Add the spring @Service annotation so spring sees this class as a controller.
Add the key and secretKey parameters and use the @Value annotation to indicate they are parameters from the application’s application.properties file (Spring Framework documentation).
Create a @PostConstruct and @PreDestroy methods (or implement a Spring InitializingBean).
Create a member variable entitled dynamoDbClient of type DynamoDbClient.
Instantiate and load the credentials for dynamoDbClient in the initialize method.
Close the dynamoDbClient in the preDestroy method.
The DynamoDBClient provides access to the DynamoDB API. All interaction with DynamoDB is done through this class. It has methods for for reading, writing, updating, and other interactions with DynamoDB tables and Items. For more information, refer to the API documentation.
Write Observation
Let’s first write an Observation to DynamoDB. Alternatively, you could say we PUT an item to DynamoB, as we are making an HTTP Put request to DynamoDB. We do this using the DynamoDBClient putItem method combined with a PutItemRequest.
Modify Service Class
Create a method named writeObservation that takes an Observation as a parameter.
Create a HashMap that uses String as the key and AttributeValue as the value.
Put each of the Observation variables into the HashMap, being sure the keys are correctly named. The keys should have exactly the same name as the JSON.
When creating the AttributeValueBuilder for each variable, ensure the correct datatype method is used.
Build a new PutItemRequest and then have dynamoDbClient call its putItem method to write the observation to the Observation DynamoDB table.
There are four different AttributeValue classes in the DynamoDB Java API. Here we use the one in the software.amazon.awssdk.services.dynamodb.model package (api documentation). Remember, tables store items. An item is comprised of one or more attributes. An AttributeValue holds the value for an attribute. AttributeValue has a builder (api documentation) used to build an AttributeValue instance. An attribute value can be a string, number, binary data, list, or collection. You use the appropriate method corresponding to the datatype to set the AttributeValue object’s value. For instance, for a String use s(String value), binary use b(SdkBytes b), and for a collection of strings use ss(Collection ss). For a complete list, refer to the API documentation.
AttributeValue instances are placed in a Map, where the key is the attribute’s name in the database table. The Observation’s attributes are mapped using the appropriate builder methods.
The tags are an optional list of strings, so we wrap it in a conditional and use,
if (observation.getTags() != null) {
observationMap.put("tags", AttributeValue.builder()
.ss(observation.getTags()).build());
}
PutItemRequest
The PutItemRequest wraps the JSON request sent to the DynamoDBClientputItem method. A PutItemRequestBuilder builds a PutItemRequest. Above, we first added the table name, followed by the item to put. The item is a key-value map of the observation’s attributes. After building the PutItemRequest instance, the DynamoDBClient instance uses the request to write the observation to the DynamoDBObservation table.
The GetItemRequest wraps a JSON Get request to DynamoDB. To fetch a particular Observation we must provide the id to the Get request. The key is a Map of AttributeValue items. In this case we added only one attribute, the id.
So far we have added and fetched an Observation to DynamoDB. Now let’s delete an Observation.
Modify Service Class
Add a deleteObservation method that takes an observation’s id as a parameter.
Create a HashMap to hold the attributes.
Build a new DeleteItemRequest and use the HashMap as the key.
Use the dynamoDbClient to delete the observation.
public void deleteObservation(String observationId) {
HashMap<String,AttributeValue> key = new HashMap<>();
key.put("id", AttributeValue.builder().s(observationId).build());
DeleteItemRequest deleteRequest = DeleteItemRequest.builder()
.key(key).tableName("Observation").build();
this.dynamoDbClient.deleteItem(deleteRequest);
}
DeleteItemRequest
The DeleteItemRequest wraps a JSON Delete HTTP request. As with all requests, we use a builder. The builder uses the table and the key to delete the Observation.
Create Rest Endpoint
Create a new Rest endpoint to delete observations.
Have the observation’s id passed to the endpoint as a path variable only add /delete after the variable.
Call the ObservationServicedeleteObservation method.
@DeleteMapping("/observation/{observationid}/delete")
public void deleteObservation(@PathVariable("observationid") String
observationId) {
this.observationService.deleteObservation(observationId);
}
Test with Postman
Create a new Request using Postman.
Assign it DELETE from the dropdown to indicate it is an Http Delete request.
Click Send and the record should be deleted. Navigate to the Items in the AWS Console to ensure the Observation was deleted.
Update Observation
An Observation can have one or more tags. This is something that seems likely to be added at a later date and/or modified. Let’s create an endpoint that allows adding/modifying an observation’s tags.
Update Service Class
Create a method named updateObservationTags that takes a list of tags and an observation id as parameters.
Create a HashMap to hold AttributeValue objects.
Use the AttributeBuilderValue builder to add the tags to the HashMap with :tagval as the key.
Create a second HashMap to hold the observation’s id.
Build an UpdateItemRequest that uses an update expression.
The DynamoDBClient instance uses the UpdateItemRequest to build the request to update the item. As with fetching and deleting, it needs a key to properly select the correct item. But it also needs the values to update. You provide an update expression and then provide the attributes. Note that the key for the attribute, :tagval, matches the expression. The request then uses the key and the update expression to update the item.
Add Rest Endpoint
Add an endpoint that takes the observation id as a path variable and a JSON array of tags as the request body.
Call the ObservationServiceupdateObservationTags method.
The DynamoDbClientbatchWriteItem method takes a BatchWriteItemRequest as a parameter. The BatchWriteItem can write or delete up to 25 items at once and is limited to 16 MB of data. Note that it still makes as many calls as you have items; however, it makes these calls in parallel.
You create a List to hold the WriteRequest for each Observation. Each Observation is written to a Map as key-value pairs. The map is added to a WriteRequest, which is then added to the list until all observations are prepared as WriteRequest instances.
Each list of WriteRequest instances is added to another map. The table name is the key and the list is the values. In this way a single batch write could write to multiple tables. After creating the map of the lists of WriteRequest instances, the whole thing is used to create a BatchWriteItemRequest which is used by the DynamoDbClientbatchWriteItem method.
Click Send then navigate to the AWS Console Observation table’s items and the observations should be added.
Conditionally Fetch Observations
A common requirement is to fetch records based upon certain criteria. For example, suppose we wish to fetch all observations belonging to a particular station. When using DynamoDB any variable used for a query must be indexed. So before creating a query, we first create an index on the Observation table’s stationid variable.
Create Index
Navigate to the Observation table in the AWS Console.
Click Create Index.
Select stationid as the index’s partition key and be certain to define it as a Number.
Click Create Index to create the index.
Secondary Indexes
Secondary Indexes allow retrieving data from a table using an attribute other than the primary key. You retrieve data from the index rather than the table. For more on DynamoDB secondary indexes, refer to the following article by LinuxAcademy: A Quick Guide to DynamoDB Secondary Indexes.
We then added the Condition to a map and specified stationid as the key and condition as the value. We then built the QueryRequest using its associated builder.
There are several topics not explored in this tutorial. First, you can scan a database table. When you scan the table you return all the items in the table. Second, this tutorial did not discuss conditionally updating or deleting items. However, the principles are the same as conditionally querying a table for items. Also, it is helpful to explore the command-line examples for working with DynamoDB, as they help understand the SDK. Finally, we did not cover the Java 1.1 AWS SDK.
From Java 1.1 AWS SDK to Java 2 AWS SDK
There are many more examples and tutorial on the Web using the Java 1.1 API rather than the Java 2 API. However, the primary difference between the two versions is the builder pattern. Many, if not most, of the Java 1.1 tutorials remain useful. The pattern is the same:
create a request type
setup the request with the desired parameters,
pass the request to the DynamoDB client,
obtain the result.
In the Java 1.1 SDK you perform these steps using constructors and setters and getters. In the Java 2 SDK you use builders. Practically all classes in the Java 2 AWS SDK use builders. Use this as a starting point if you have a particularly good tutorial using the Java 1.1. SDK. Although not foolproof, doing this has helped me translate many Java 1.1. examples to Java 2 SDK.
This tutorial, although it uses the Java 1 AWS API, is a very good introduction covering the same topics in this tutorial. Just remember, think builder, although the techniques in the API are the same, the Java 2 version of the API uses builders extensively.
Conclusion
In this tutorial we explored the lower-level API of the Java 2 SDK by using the AWS DynamoDB Java API. We wrote an item, updated an item, deleted an item, and batch uploaded items. We also explored conditionally querying items.
As with all of the SDK, it is based upon builders, requests, and the client. You build a request to pass to the DynamoDBClient which in turn returns a response. You do not create a new instance of a request and set properties via setters, but rather, you use a builder to build a request.
DynamoDB is a non-relational database and so you cannot just write a conditional query on any field. You can only use fields that are indexed in a query. This seems logical if you consider that DynamoDB is designed for massive amounts of data that is relatively unstructured.
In this tutorial you use the AWS S3 Java API in a Spring Boot application. Amazon’s S3 is an object storage service that offers a low-cost storage solution in the AWS cloud. It provides unlimited storage for organizations regardless of an organization’s size. It should not be confused with a fully-featured database, as it only offers storage for objects identified by a key. The structure of S3 consists of buckets and objects. An account can have up to 100 buckets and a bucket can have an unlimited number of objects. Objects are identified by a key. Both the bucket name and object keys must be globally unique. If working with S3 is unfamiliar, refer to the Getting Started with Amazon Simple Storage Service guide before attempting to work with the AWS S3 Java API in this tutorial.
In this tutorial we explore creating, reading, updating, listing, and deleting objects and buckets stored in S3 storage using the AWS S3 Java API SDK 2.0 to access Amazon’s Simple Storage Service (S3).
First we perform the following tasks with objects:
write an object to a bucket,
update an object in a bucket,
read an object in a bucket,
list objects in a bucket,
and delete an object in a bucket.
After working with objects, we then use the Java SDK to work with buckets, and perform the following tasks:
create a bucket,
list buckets,
and delete a bucket.
This tutorial uses the AWS SDK for Java 2.0. The SDK changed considerably since 1.X and the code here will not work with older versions of the API. In particular, this tutorial uses the 2.5.25 version of the API.
Do not let using Spring Boot deter you from this tutorial. Even if you have no interest in Spring or Spring Boot, this tutorial remains useful. Simply ignore the Spring part of the tutorial and focus on the AWS S3 code. The AWS code is valid regardless of the type of Java program written and the Spring Boot code is minimal and should not be problematic.
And finally, you might question why this tutorial creates a Rest API as Amazon also exposes S3 functionality as a REST API, which we will explore in a later tutorial. Suspend disbelief and ignore that we are wrapping a Rest API in another Rest API. Here the focus is programmatically accessing the API using the Java SDK. The tutorial should prove useful even if you are a Java developer with no interest in Spring Boot.
The AWS Java 2.0 API Developers Guide is available here.
Prerequisites
Before attempting this tutorial on the AWS S3 Java API you should have a basic knowledge of the Amazon AWS S3 service. You need an AWS developer account. You can create a free account on Amazon here. For more information on creating an AWS account refer to Amazon’s website.
The Spring Boot version used in this tutorial is 2.0.5 while the AWS Java SDK version is 2.5.25. In this tutorial we use Eclipse and Maven, so you should have a rudimentary knowledge of using Maven with Eclipse. And we use Postman to make rest calls. But, provided you know how to build using Maven and know Rest fundamentals, you should be okay using your own toolset.
You must have an AWS development account.
Creating A Bucket – Console
Amazon continually improves the AWS console. For convenience, we create a user and bucket here; however, you should consult the AWS documentation if the console appears different than the images and steps presented. These images and steps are valid as of April 2019. For more information on creating a bucket and creating a user, refer to Amazon’s documentation.
Let’s create a bucket to use in this tutorial.
Log into your account and go to the S3 Console and create a new bucket.
Name the bucket javas3tutorial* and assign it to your region. Here, as I am located in Frederick Maryland, I assigned it to the US East region (N. Virginia).
Accept the default values on the next two screens and click Create bucket to create the bucket.
Note that in this tutorial I direct you to create buckets and objects of certain names. In actuality, create your own names. Bucket names must be globally unique, A name such as mybucket was used long ago.
Bucket names must be globally unique across all of S3.Click Create bucket to start creating a bucket.Assign bucket name and region.
Accept the defaults and click Next.Accept the defaults and click Next button.
Click Create bucket if options are correct.
After creating the bucket you should see the bucket listed in your console. Now we must create a user to programmatically access S3 using the Java SDK.
The bucket appears in your S3 buckets screen.
Creating an S3 User – Console
As with creating a bucket, the instructions here are not intended as comprehensive. More detailed instructions are provided on the AWS website. To access S3 from the Java API we must create a user with programmatic access to the S3 Service. That user is then used by our program as the principal performing AWS tasks.
Navigate to the Identity and Access Management (IAM) panel.
Click on Users and create a new user.
Provide the user with Programmatic access.
Creating a user with programmatic access.
After creating the user, create a group.
Create a group by clicking Create group.
Assign the AmazonS3FullAccess policy to the group.
Assigning AmazonS3FullAccess to a user.
Navigate past create tags, accepting the default of no tags.
Accept default and do not assign tags.
Review the user’s details and click Create user to create the user.
Review user settings and click Create user.
On the success screen note the Download .csv button. You must download the file and store in a safe place, otherwise you will be required to create new credentials for the user.
After creating user, click Download .csv to save the public and private keys.
The content of the credentials.csv will appear something like the following. Keep this file guarded, as it contains the user’s secret key and provides full programatic access to your S3 account.
Note: I deleted this user and group prior to publishing this tutorial.
User name,Password,Access key ID,Secret access key,Console login link
java_tutorial_user,,XXXXXXXXXXX,oaUl6jJ3QTdoQ8ikRHVa23wNvEYQh5n0T5lfz1uw,https://xxxxxxxx.signin.aws.amazon.com/console
After creating the bucket and the user, we can now write our Java application.
Java Application – Spring Boot
We use Spring boot to demonstrate using the AWS Java SDK. If you are unfamiliar with Spring Boot, refer to this tutorial to get started with Spring Boot and Rest.
Project Setup
We setup the project as a Maven project in Eclipse.
Maven Pom
Add the Spring Boot dependencies to the pom file.
Add the AWS Maven Bill of Materials (BOM) to the pom file.
A BOM is a POM that manages the project dependencies. Using a BOM frees developers from worrying that a library’s dependencies are the correct version. You place a BOM dependency in a dependencyManagement, then when you define your project’s dependencies that are also in the BOM, you omit the version tag, as the BOM manages the version.
To better understand a BOM, navigate to the BOM and review its contents.
Click on the latest version (2.5.25 as of the tutorial).
The AWSSDK BOM.
Click on the View All link.
Summary of the AWS Java SDK Bill of Materials 2.25.
Click the link to the pom and the BOM appears. This is useful, as it lists the AWS modules.
The listing of BOM files. Click on the pom to view the xml pom definition.Snippet of the AWS SDK BOM contents.
Add the auth, aws–core, and s3artifacts to the pom. Note that we do not require specifying the version, as the BOM handles selecting the correct version for us.
After creating the POM you might want to try building the project to ensure the POM is correct and you setup the project correctly. After that, we need to add the AWS user credentials to your project.
AWS Credentials
When your application communicates with AWS, it must authenticate itself by sending a user’s credentials. The credentials consists of the access key and secret access key you saved when creating the user. There are several ways you might provide these credentials to the SDK, for example, you can put the credentials file in a users home directory, as follows, and they will be automatically detected and used by your application.
~/.aws/credentials
C:\Users\<username>\.aws\credentials
For more information on the alternative ways of setting an application’s user credentials, refer to the Developer’s Guide. But here we are going to manually load the credentials from the Spring boot application.properties file
If you did not start with a bare-bones Spring Boot project, create a new folder named resources and create an application.properties file in this folder.
Refer to the credential file you saved and create the following two properties and assign the relevant values. Of course, replace the values with the values you downloaded when creating a programatic user.
Add the two properties to the application.properties file.
Add a small binary file to the resources folder. For example, here we use sample.png, a small image file.
Spring Boot Application
Now that we have the project structure, we can create the Spring Application to demonstrate working with the AWS S3 Java API.
Create the com.tutorial.spring.application, com.tutorial.spring.controller, com.tutorial.spring.data, and the com.tutorial.spring.service packages.
Create a new Spring application class named SimpleAwsClient in the application package.
package com.tutorial.aws.spring.application;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.ComponentScan;
@SpringBootApplication
@ComponentScan({ "com.tutorial.aws.spring" })
public class SimpleAwsClient {
public static void main(String[] args) {
SpringApplication.run(SimpleAwsClient.class, args);
}
}
Data Object (POJO)
Create a simple data object named DataObject in the data package.
Add the variablename and create the getter and setter for this property.
package com.tutorial.aws.spring.data;
public class DataObject {
String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
Ensure the program compiles.
We now have the project’s structure and can work with S3 using the SDK.
Writing Objects to S3
We implement the example application as a Spring Boot Rest application. The standard architecture of this application consists of a Controller, a Service, and a data access layer. In this tutorial there is no need for a data access layer, and so the application consists of a controller and service. Begin by creating a Service class that interacts with the AWS SDK.
Service
Create a new class named SimpleAwsS3Service and annotate it with the @Service annotation.
Create the key and secretKey properties and populate them from the application.properties file.
Add an S3Client as a private variable.
Create a method named initialize and annotate it with the @PostContstruct annotation.
Create a method named uploadFile that takes a DataObject and writes the file to S3.
There are many concepts in the preceding code. Let’s examine each in turn.
Builder Pattern and Fluent Interface
The fluent interface is a term created by Martin Fowler and Eric Evans. It refers to a programming style where the public methods (the API) can be chained together to perform a task. It is used by the AWS S3 Java API 2.x when using builders. The builder tasks perform tasks but then return an instance of the builder. This allows chaining methods together. For more information on the fluid interface and builders, refer to this blog post: Another builder pattern for Java.
AwsBasicCredentials
The AwsBasicCredentials class implements the AwsCredentials Interface and takes a key and secret key. These credentials are then used by an S3Client to securely authenticate to AWS.
In a production application, you should use Amazon’s Security Token Service to get temporary credentials to access AWS services. Refer to the AWS documentation: Getting Temporary Credentials with AWS STS.
S3Client
The S3Client class is a client for accessing AWS. As with most the API, it uses a builder to construct itself. The builder uses the credentials and region to create the S3Client. The S3Client is then used for all communication between a client application and AWS.
PutObjectRequestR
The PutObjectRequest is for uploading objects to S3. You create and configure the class using its associated builder, PutObjectRequest.Builder interface. We provide the bucket name, the object name, and although not required, we pass an access control list specifying the public has read access of the resource.
The ObjectCannedACL provides, well, a pre-canned access control list. Valid values are:
AUTHENTICATED_READ, AWS_EXEC_READ, BUCKET_OWNER_FULL_CONTROL, BUCKET_OWNER_READ, PRIVATE, PUBLIC_READ, PUBLIC_READ_WRITE, and UNKNOWN_TO_SDK_VERSION.
The S3Client then uses the PutObjectRequest to upload the object to S3.
Running The Program
Compile, and run the Spring Application.
Send the request using Postman or curl and note the error response. S3 denied access.
Uploading the object fails with an Access Denied error.
The failure is because of the ACL we attempted to set. We wished to grant public read access. But, when creating the bucket, we failed to allow for this. We need to return to the bucket configuration and explicitly allow public access.
By default public access is denied.
Object Visibility
Sign into the AWS Console and navigate to the bucket. Note that neither the bucket nor the objects are public.
Click on the bucket and the following popup should appear.
Click on the Permissions link.
Un-check the two checkboxes under the Manage public access… heading. By unchecking them we are allowing new ACLs and uploading public objects.
A new popup appears just to be sure that we wish to do this. What this is telling you, of course, is this is generally not a good idea unless you truly wish making the objects in a bucket public.
Type confirm and click the Confirm button.
Return to Postman and try again. Postman should receive a 200 Success HTTP Code.
Refresh the bucket screen in AWS and the file should appear.
Click on the file and in the resulting popup, click on the object’s URL and the object should load in a browser. If not, copy and paste the url into a browser.
Downloading Objects On S3
Downloading an object involves creating a GetObjectRequest and then passing it to an S3Client to obtain the object. Here we download it directly to a file, although note you can work with the object as it is downloading.
Service
Implement the downloadFile method as follows in the SimpleAwsService class.
Create a GetObjectRequest, get the classpath to the resources folder, and then use s3Client to download sample.png and save it as test.png.
The builder uses the bucket name and the object key to build a GetObjectRequest. We then use the S3Client to get the object, downloading it directly to the file path passed.
Rest Controller
Implement the fetchobject endpoint in the SimpleAwsController class.
@GetMapping("/fetchobject/{filename}")
public void fetchObject(@PathVariable String filename) throws Exception {
DataObject dataObject = new DataObject();
dataObject.setName(filename);
this.simpleAwsS3Service.downloadFile(dataObject);
}
Running the Program
Create a request in Postman (or curl) and fetch the file.
Navigate to the resources folder in the project target folder and you should see the downloaded file.
Listing Objects On S3
The steps to list files in a bucket should prove familiar by now: use a builder to build a request object, which is passed to the S3Client which uses the request to interact with AWS. However, here we work with the response as well.
Add Files
Navigate to the bucket on the AWS console.
Upload a few files to the bucket.
Service
Modify SimpleAwsService to implement a method named listObjects that returns a list of strings.
Create a ListObjectsRequest and have the s3Client use the request to fetch the objects.
We first use a builder to create a ListObjectsRequest. The S3Client then requests the list of objects in the bucket and returns a ListObjectResponse. We then iterate through each object in the response and put the key in an ArrayList.
Rest Controller
Modify SimpleAwsController to implement the listObjects method.
@GetMapping("/listobjects")
public List<String> listObjects() throws Exception {
return this.simpleAwsS3Service.listObjects();
}
Running the Program
Create a new request in Postman and list the objects in the bucket.
Modifying Objects
Technically speaking, you cannot modify an object in an S3 bucket. You can replace the object with a new object, and that is what we do here.
Replace the file used in your project with a different file. For instance, I changed sample.png with a different png file. Now sample.png in the project differs from the sample.png file in the AWS bucket.
Rest Controller
Modify the SimpleAwsController class so that the uploadObject method calls the uploadFile method in the SimpleAwsService class.
Modify the SimpleAwsController to implement the deleteObject method.
@DeleteMapping("/deleteobject")
public void deleteObject(@RequestBody DataObject dataObject) {
this.simpleAwsS3Service.deleteFile(dataObject);
}
Running The Application
Compile the program and create a DELETE request in Postman and delete the object.
Navigate to the bucket on the AWS Console and the object should no longer exist.
Buckets
By this point, if you worked through the tutorial, you should be able to guess the workflow and relevant classes needed for creating, listing, and deleting buckets. The CreateBucketRequest, ListBucketRequest, and DeleteBucketRequest are the relevant request classes and each request has a corresponding builder to build the request. The S3Client then uses the request to perform the desired action. Let’s examine each in turn.
Creating Buckets
Creating a bucket consists of creating a CreateBucketRequest using a builder. Because bucket names must be globally unique, we append the current milliseconds to the bucket name to ensure it is unique.
Service
Create a method named addBucket to the AwsSimpleService class.
Create a createBucket method in AwsSimpleRestController with a /addbucket mapping.
@PostMapping("/addbucket")
public DataObject createBucket(@RequestBody DataObject dataObject) {
return this.simpleAwsS3Service.addBucket(dataObject);
}
Listing Buckets
Listing buckets follows the same pattern as listing objects. Build a ListBucketsRequest, pass that to the S3Client, and then get the bucket names by iterating over the ListBucketsResponse.
Service
Create a new method called listBuckets that returns a list of strings to SimpleAwsService.
The listBucketsResponse contains a List of Bucket objects. A Bucket has a name method that returns the bucket’s name.
Rest Controller
Add a /listbuckets endpoint to SimpleAwsController.
@GetMapping("/listbuckets")
public List<String> listBuckets() {
return this.simpleAwsS3Service.listBuckets();
}
Deleting Buckets
Before you can delete a bucket you must delete it’s contents. Here we assume non-versioned resources. Now, you might be tempted to try the following, but consider the scalability.
for each item in bucket delete.
This is fine for a few objects in a sample project like in this tutorial, but it will quickly prove untenable, as the program will block as it makes the http connection to the S3 storage, deletes the object, and returns success. It could quickly go from minutes, to hours, to years, to decades, depending upon the number of objects stored. Remember, each call is making an HTTP request to an AWS server over the Internet.
Of course, Amazon thought of this, and provides a means of deleting multiple objects at once. The following code will not win any elegance awards for its iteration style, but it demonstrates a scalable way to delete buckets containing many objects.
Service
Add a method called deleteBucket that takes a bucket’s name as a String.
Get the keys of the objects in the bucket and iterate over the keys.
With each iteration, build an ObjectIdentifier and add it to an array of identifiers.
Every thousand keys, delete the objects from the bucket.
After iterating over all the keys, delete any remaining objects.
Add a deletebucket endpoint to the SimpleAwsController.
@DeleteMapping("/deletebucket")
public void deleteBucket(@RequestBody DataObject dataObject) {
this.simpleAwsS3Service.deleteBucket(dataObject.getName());
}
Conclusions
In this tutorial on the AWS S3 Java API we worked with objects and buckets in S3. We created an object, listed objects, downloaded an object, and deleted an object. We also created a bucket, listed buckets, and deleted a bucket. Although we used Spring Boot to implement the sample application, the ASW Java code remains relevant for other Java application types.
We did not upload an object using multiple parts. For a good example on accomplishing this task, refer to the SDK Developer Guide’s sample S3 code. Also, we assumed no versioning to keep the tutorial simple. If you must support versioning then consult the documentation.
The AWS S3 Java API wraps Amazon’s S3 Rest API with convenience classes. Here you used those classes to work with objects and buckets. In a future tutorial we will work with the Rest API directly.