Here you use the put_record and the put_record_batch functions to write data to the Kinesis Firehose client using Python. If after completing the previous tutorial you wish to refer to more information on using Python with AWS, refer to the following two information sources.
In the previous tutorial you created an AWS Kinesis Firehose stream for streaming data to an S3 bucket. Moreover, you wrote a Lambda function that transformed temperature data from Celsius or Fahrenheit to Kelvin. You also sent individual records to the stream using the Command Line Interface (CLI) and its firehose put-record function.
In this tutorial you write a simple Kinesis Firehose client using Python to the stream created in the last tutorial (sending data to Kinesis Firehose using Python). Specifically, you use the put-record and put-record-batch functions to send individual records and then batched records respectively.
Creating Sample Data
Navigate to mockaroo.com and create a free account.
Click Schemas to create a new schema.
Name the schema, here I named it SampleTempDataForTutorial.
Creating a schema in Mockaroo
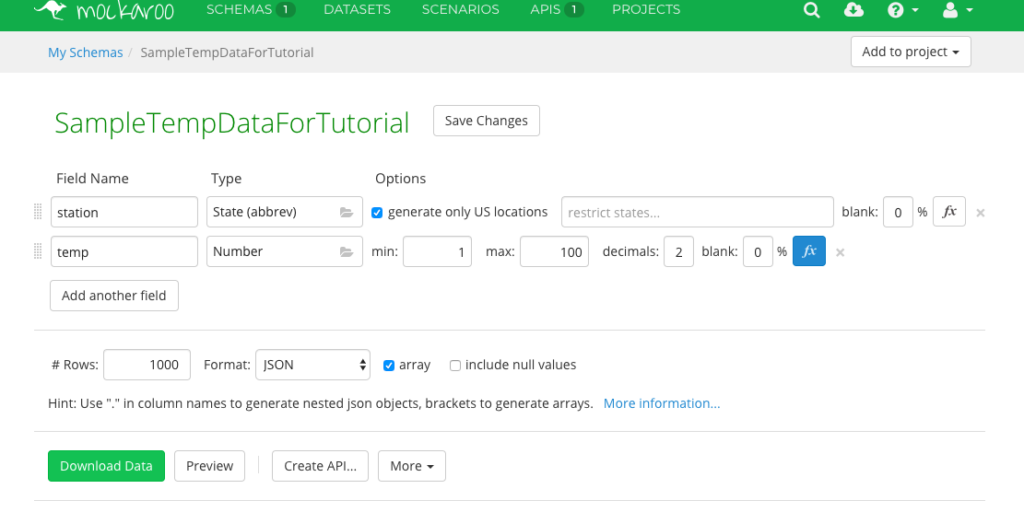
Create a field named station and assign its type as State (abbrev).
Create a field named temp and assign it as Number with a min of one, max of 100, and two decimals.
Creating the SampleTempDataForTutorial data in Mockaroo
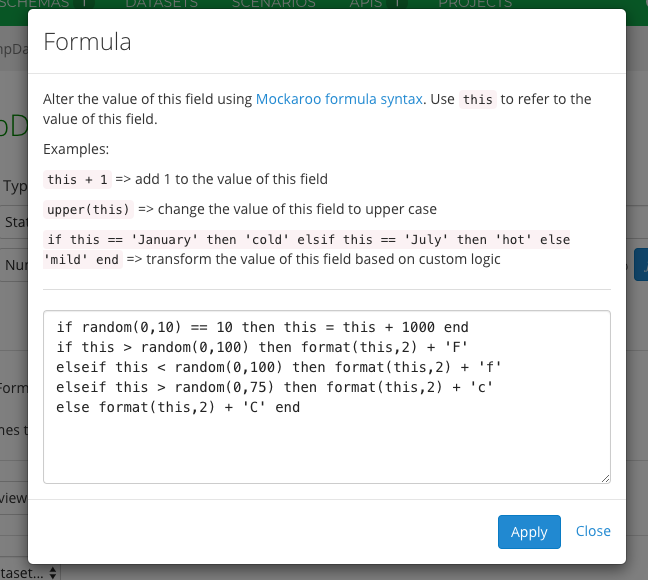
Click the fx button and create the formula as follows.
if random(0,10) == 10 then this = this + 1000 end
if this > random(0,100) then format(this,2) + 'F'
elseif this < random(0,100) then format(this,2) + 'f'
elseif this > random(0,75) then format(this,2) + 'c'
else format(this,2) + 'C' end
The formula randomly generates temperatures and randomly assigns an F, f, C, or c postfix. Note that it also generates some invalid temperatures of over 1000 degrees. You will use this aberrant data in a future tutorial illustrating Kinesis Analytics.
Creating a formula in Mockaroo for a field
Click Apply to return to the main screen.
Enter 1000 for rows, select Json as the format, and check the array checkbox.
You should have a file named SampleTempDataForTutorial.json that contains 1,000 records in Json format. Be certain the data is an array, beginning and ending with square-brackets.
Python Client (PsyCharm)
Here I assume you use PsyCharm, you can use whatever IDE you wish or the Python interactive interpreter if you wish. Let’s first use the put-record command to write records individually to Firehose and then the put-record-batch command to batch the records written to Firehose.
Writing Records Individually (put_record)
Start PsyCharm. I assume you have already installed the AWS Toolkit and configured your credentials. Note, here we are using your default developer credentials.
In production software you should use appropriate roles and and a credentials provider, do not rely upon a built-in AWS account as you do here.
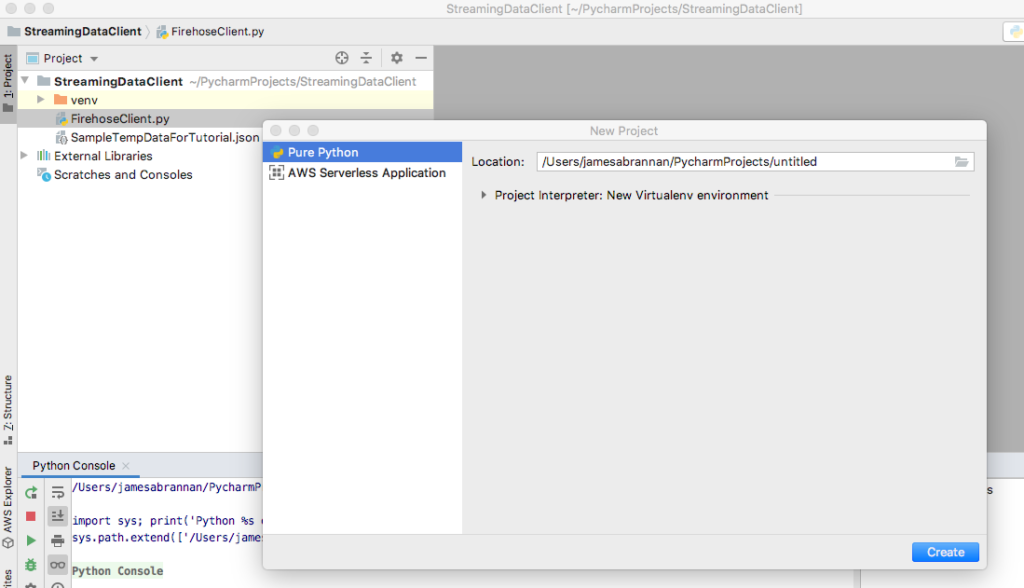
Create a new Pure Python application named StreamingDataClient.
Create a new Pure Python project in PsyCharm
Create a new file named FireHoseClient.py and import Boto3 and json.
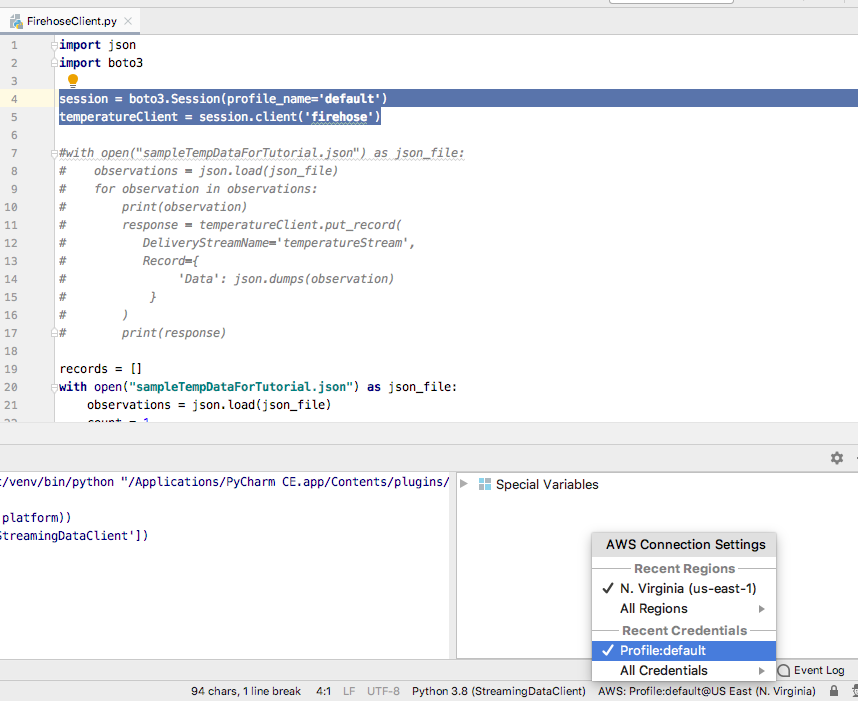
Create a new session using the AWS profile you assigned for development.
Create a new firehose client from the session.
Creating a session using default AWS credentials
Write the following code.
import json
import boto3
session = boto3.Session(profile_name='default')
temperatureClient = session.client('firehose')
with open("sampleTempDataForTutorial.json") as json_file:
observations = json.load(json_file)
for observation in observations:
print(observation)
response = temperatureClient.put_record(
DeliveryStreamName='temperatureStream',
Record={
'Data': json.dumps(observation)
}
)
print(response)
In the preceding code you open the file as a json and load it into the observations variable. You then loop through each observation and send the record to Firehose using the put_record method. Note that you output the record from json when adding the data to the Record.
You should see the records and the response scroll through the Python Console.
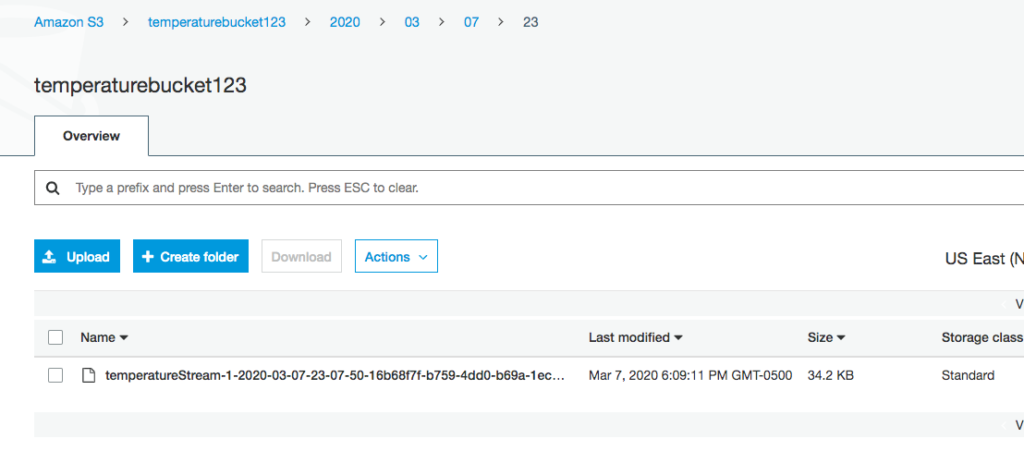
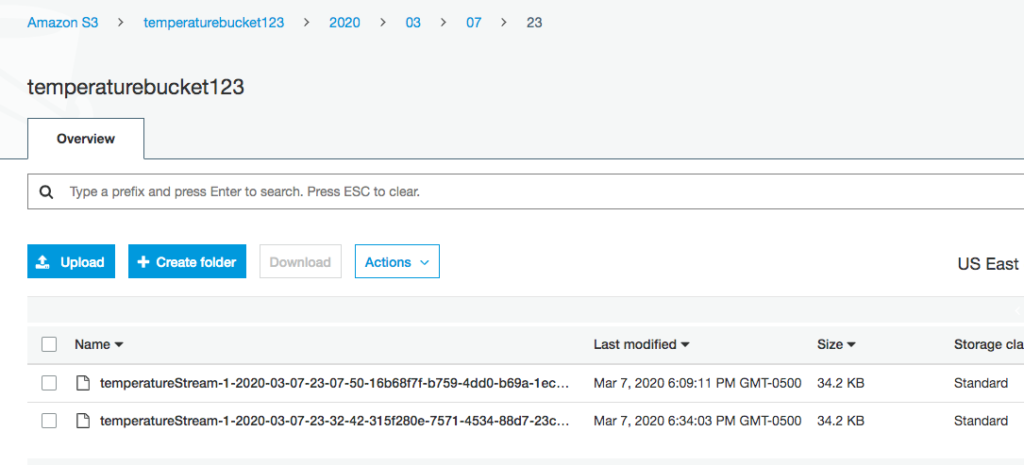
Navigate to the AWS Console and then to the S3 bucket.
Data created in S3
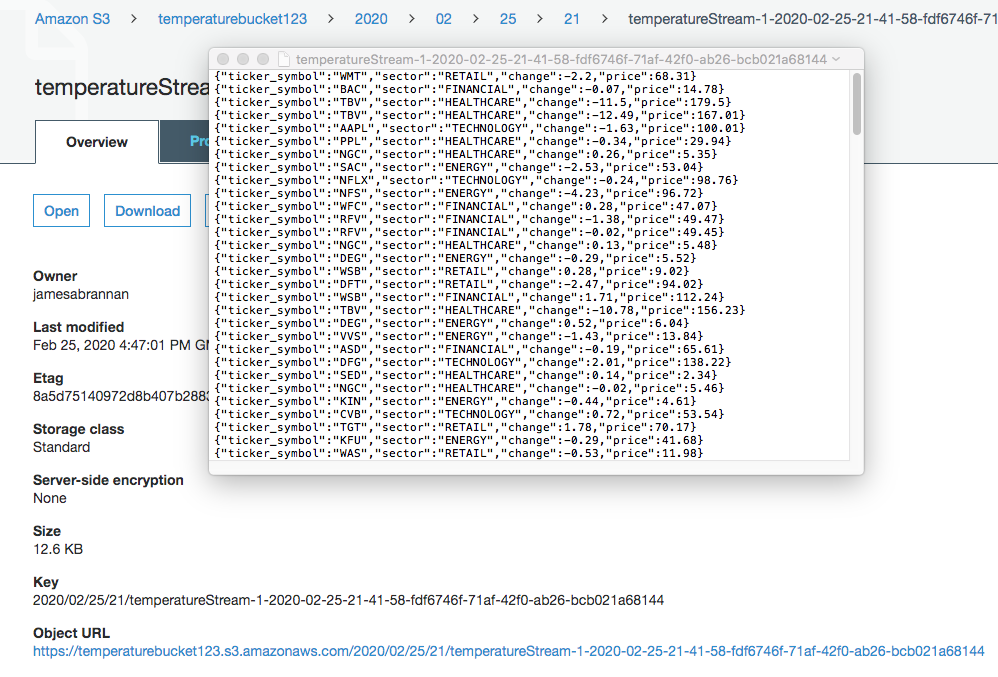
You should see the records written to the bucket.
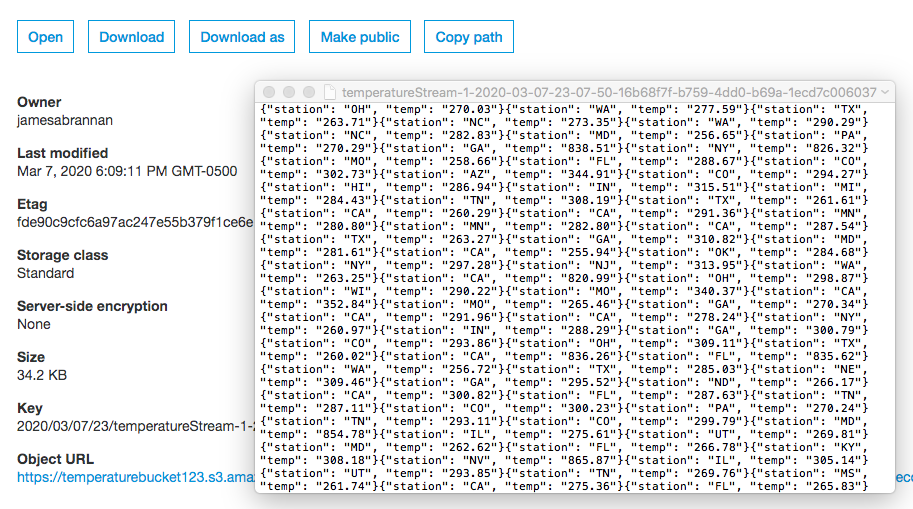
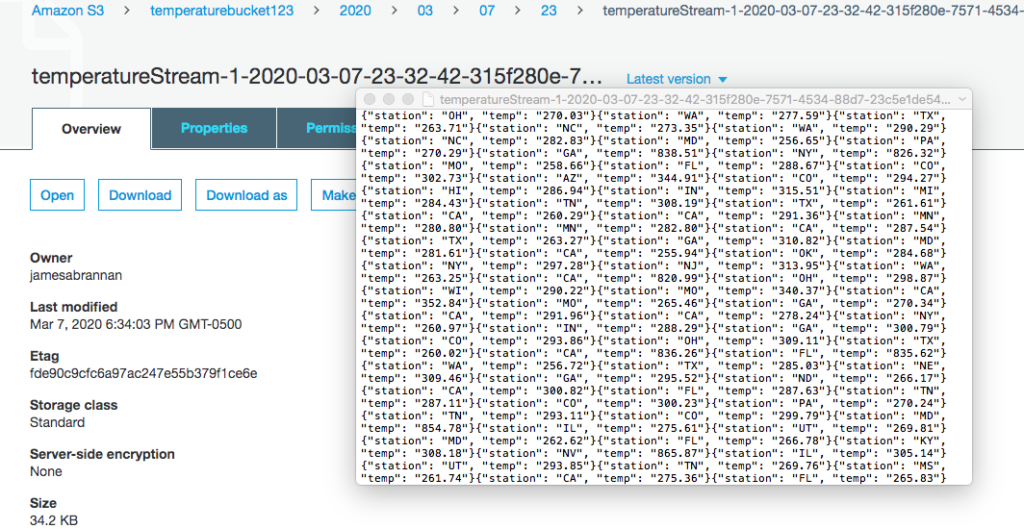
Open the file to ensure the records were transformed to kelvin.
Data converted to kelvin in S3
Batch Writing Records (put_record_batch)
Writing records individually are sufficient if your client generates data in rapid succession. However, you can also batch data to write at once to Firehose using the put-record-batch method.
Replace the code with the following code.
import json
import boto3
session = boto3.Session(profile_name='default')
temperatureClient = session.client('firehose')
records = []
with open("sampleTempDataForTutorial.json") as json_file:
observations = json.load(json_file)
count = 1
for observation in observations:
if count % 500 == 0:
response = temperatureClient.put_record_batch(
DeliveryStreamName='temperatureStream',
Records= records
)
print(response)
print(len(records))
records.clear()
record = {
"Data": json.dumps(observation)
}
records.append(record)
count = count + 1
if len(records) > 0:
print(len(records))
response = temperatureClient.put_record_batch(
DeliveryStreamName='temperatureStream',
Records= records
)
print(response)
In the preceding code you create a list named records. You also define a counter named count and initialize it to one. The code loops through the observations. Each observation is written to a record and the count is incremented. When the count is an increment of 500 the records are then written to Firehose. Note that Firehose allows a maximum batch size of 500 records. After looping through all observations, any remaining records are written to Firehose.
The data is written to Firehose using the put_record_batch method. Instead of writing one record, you write list of records to Firehose.
Before executing the code, add three more records to the Json data file.
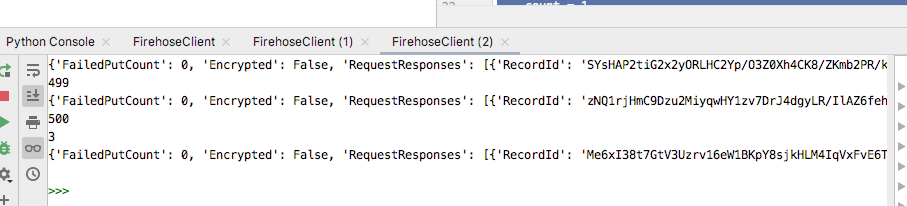
Run the code and you should see output similar to the following in the Python Console.
Python Console output
Navigate to the S3 bucket in the AWS Console and you should see the dataset written to the bucket.
Data written to S3 bucket
Open the records and ensure the data was converted to kelvin.
Data converted to kelvin in S3 bucket
Summary
This tutorial was on sending data to Kinesis Firehose using Python. You wrote a simple python client that wrote records individually to Firehose. You then wrote a simple python client that batched the records and wrote the records as a batch to Firehose. Refer to the Python documentation for more information on both commands. In the next tutorial you will create a Kinesis Analytics Application to perform some analysis to the firehose data stream.
Warning – Kinesis Firehose Stream Lambda function tutorial could incur an excess cost. Unless you plan on performing the other tutorials, delete your AWS resources to avoid incurring a cost.
This tutorial was tested on OS-X and Windows 10.
In this tutorial you create a semi-realistic example of using AWS Kinesis Firehose. You also create a Kinesis Firehose Stream Lambda function using the AWS Toolkit for Pycharm to create a Lambda transformation function that is deployed to AWS CloudFormation using a Serverless Application Model (SAM) template. After that, you then create the Kinesis Firehose stream and attach the lambda function to the stream to transform the data.
Introduction
Amazon Web Services Kinesis Firehose is a service offered by Amazon for streaming large amounts of data in near real-time. Streaming data is continuously generated data that can be originated by many sources and can be sent simultaneously and in small payloads. Logs, Internet of Things (IoT) devices, and stock market data are three obvious data stream examples. Kinesis Streams Firehose manages scaling for you transparently. Firehose allows you to load streaming data into Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, and Splunk. You can also transform the data using a Lambda function. Firehose also allows easy encryption of data and compressing the data so that data is secure and takes less space. For more information, refer to Amazon’s introduction to Kinesis Firehose.
If you prefer watching a video introduction, the following is a good Kinesis Firehose overview.
AWS Introduction to Kinesis Firehose
Other Tutorials
Although this tutorial stands alone, you might wish to view some more straight-forward tutorials on Kinesis Firehose before continuing with this tutorial. Here we add complexity by using Pycharm and an AWS Serverless Application Model (SAM) template to deploy a Lambda function.
The following is a good video demonstration of using Kinesis Firehose by Arpan Solanki. The example project focuses on the out of the box functionality of Kinesis Firehose and will make this tutorial easier to understand.
AWS Kinesis Firehose demo by Arpan Solanki
Tasks Performed Here
In this tutorial you add more complexity to the more straightforward demonstrations on using Kinesis Firehose. Rather than creating the Lambda function while creating the Kinesis Stream, you create a more realistic Lambda function using Pycharm. Moreover, you deploy that function using an AWS Serverless Application Model (SAM) template. We will perform the following tasks in this tutorial.
Create and test a Kinesis Firehose stream.
Create a Lambda function that applies a transformation to the stream data.
Deploy the Lambda function using a Serverless Application Model (SAM) template.
Modify the Kinesis Firehose stream to use the Lambda data transformer.
Test the Kinesis Firehose stream.
Trace and fix an error in the Lambda function.
Redeploy the Lambda function.
Test the Kinesis Firehose stream
Sample Project Architecture
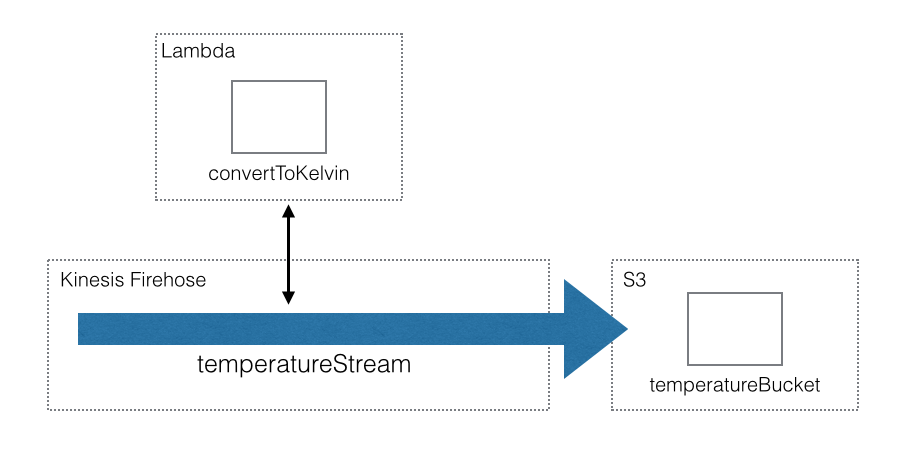
Assume we have many locations that record the ambient temperature. We need to aggregate this data from the many different locations in almost real-time. We decide to use AWS Kinesis Firehose to stream data to an S3 bucket for further back-end processing.
Data is recorded as either fahrenheit or celsius depending upon the location sending the data. But the back-end needs the data standardized as kelvin. To transform data in a Kinesis Firehose stream we use a Lambda transform function. The following illustrates the application’s architecture.
Tutorial application architecture
Prerequisites
This tutorial expects you to have an AWS developer account and knowledge of the AWS console. You should have PyCharm with the AWS Toolkit installed and the AWS CLI also installed.
This tutorial requires a rudimentary knowledge of S3, CloudFormation and SAM templates, Lambda functions, and of course, Python. The following links should help if you are missing prerequisites.
Log in to the AWS Console and select Services and then Kinesis.
Click Get Started if first time visiting Kinesis.
Click Create delivery stream in the Firehose panel.
Create delivery stream option on Amazon Kinesis dashboard (if no defined streams)
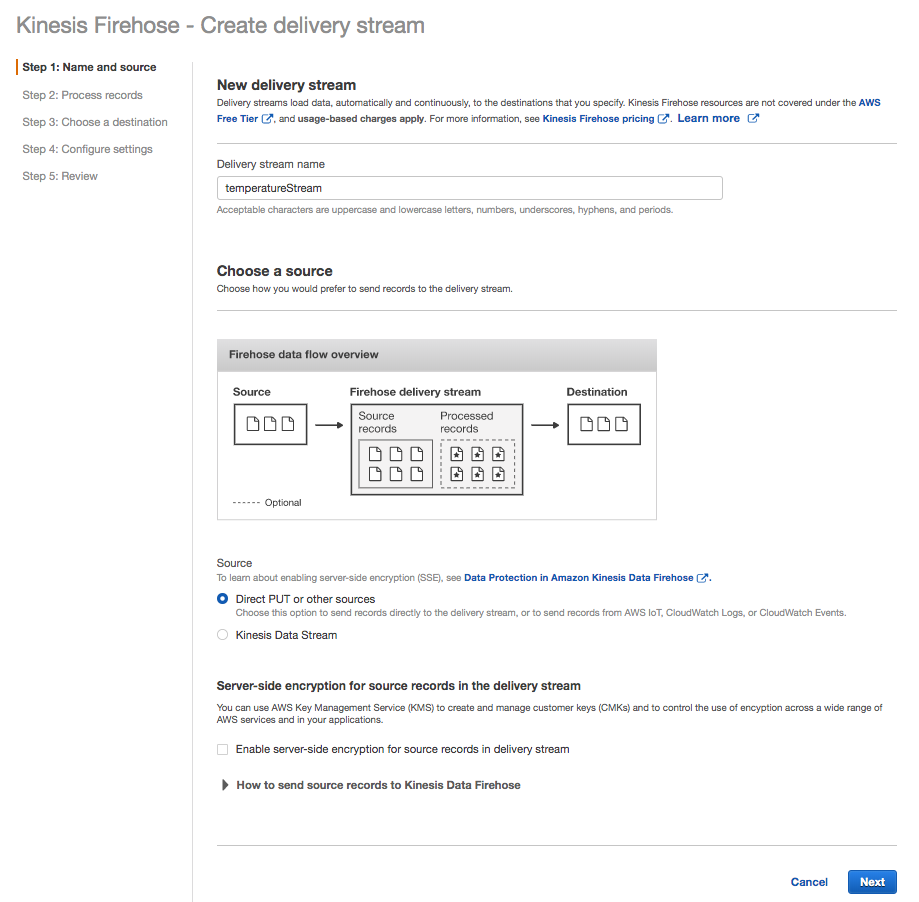
Name the Stream
Name the delivery stream temperatureStream.
Accept the default values for the remaining settings.
Click Next.
Create delivery stream – first step
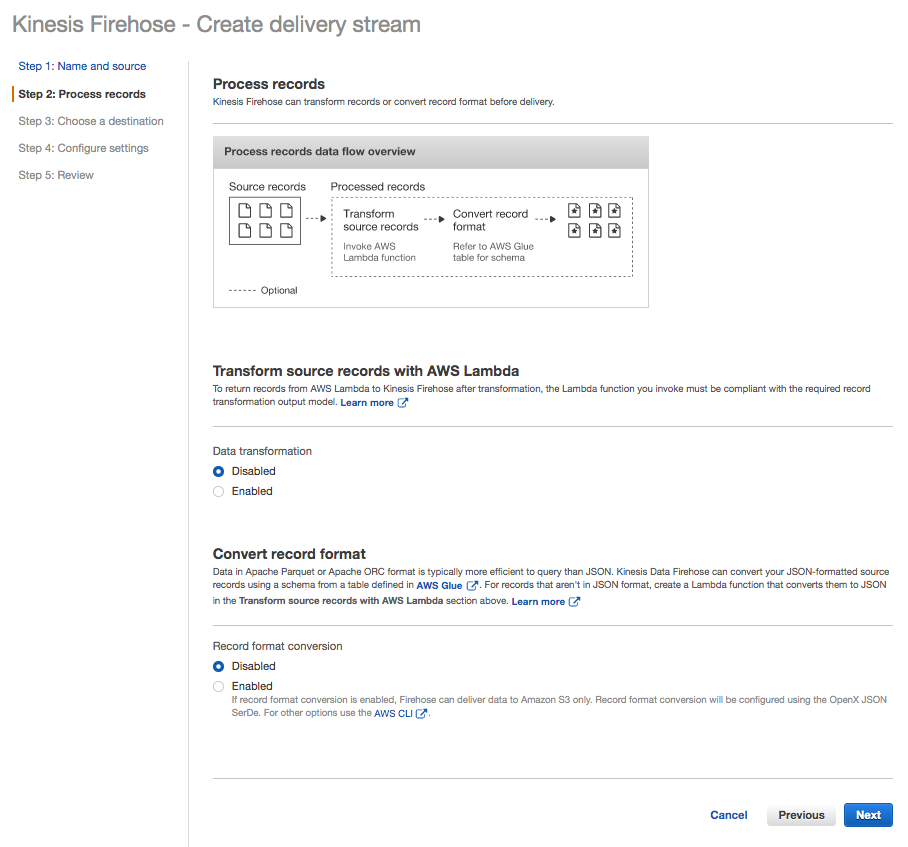
A data producer is any application that sends data records to Kinesis Firehose. By selecting Direct PUT or other sources you are allowing producers to write records directly to the stream.
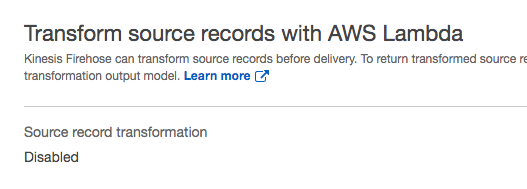
Accept the default setting of Disabled for Transform source records with AWS Lambda and Convert record format.
Click Next.
Create delivery stream – second step
The Transform source records with AWS Lambda allows you to define a Lambda function. Later in this tutorial you will change this setting and define a Lambda function. For now, leave it disabled.
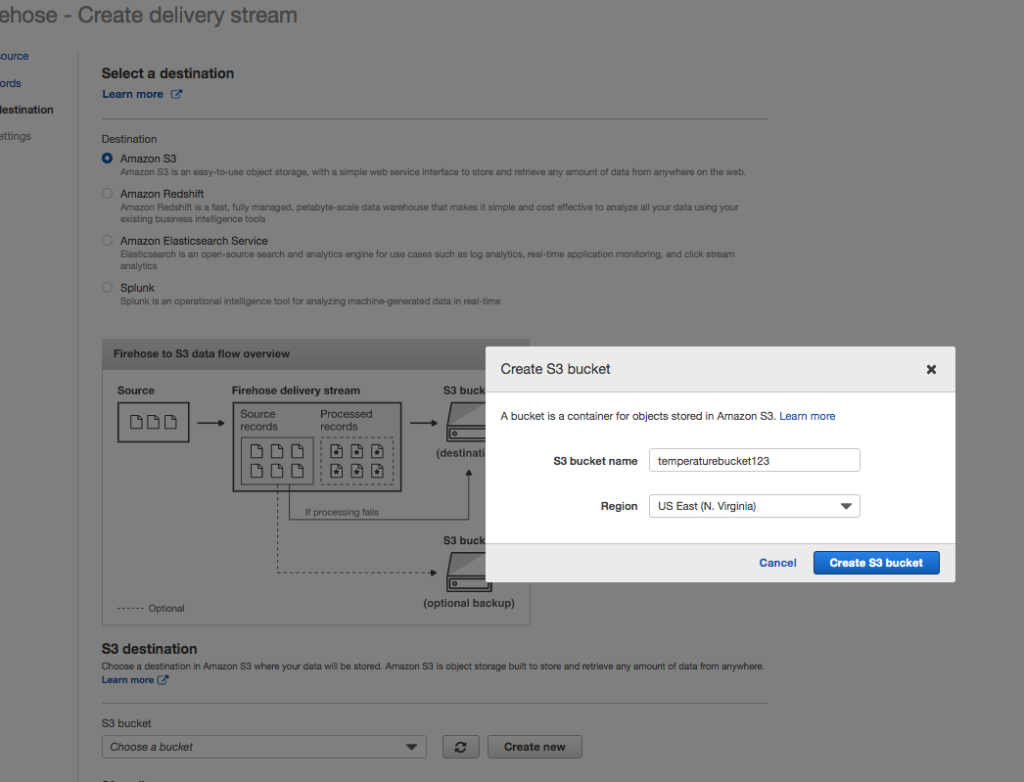
Configure S3 Bucket
Select Amazon S3 as the Destination.
Under the S3 destination, click Create new.
Name the S3 bucket with a reasonable name (remember all names must be globally unique in S3). Here I use the name temperaturebucket123 as the bucket name and select the appropriate Region.
Create S3 bucket for stream
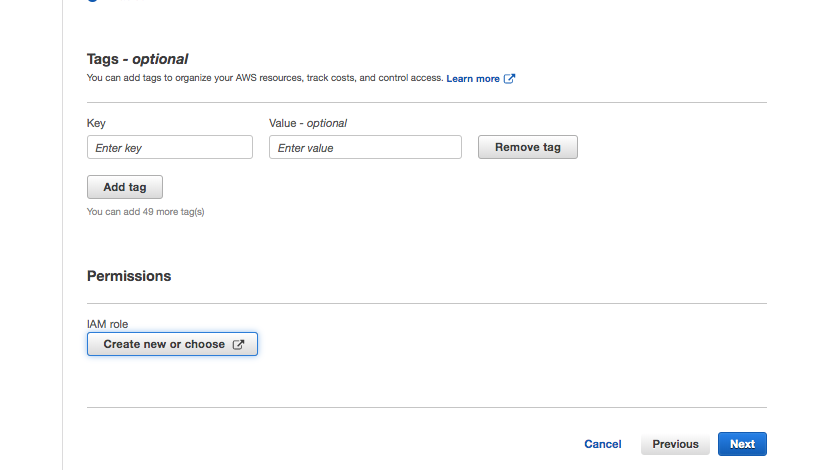
Configure Permissions
Click Next.
Accept the defaults and scroll to the Permissions section.
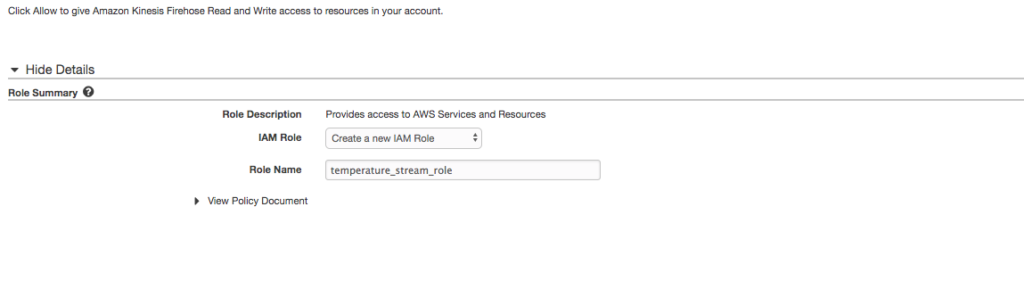
Click Create new or choose to associate an IAM role to the stream.
Create new or choose IAM role for stream
Create a role named temperature_stream_role (we return to this role in a moment) by accepting the defaults.
Click Allow.
Click Next after returned to the stream creation.
Create Role
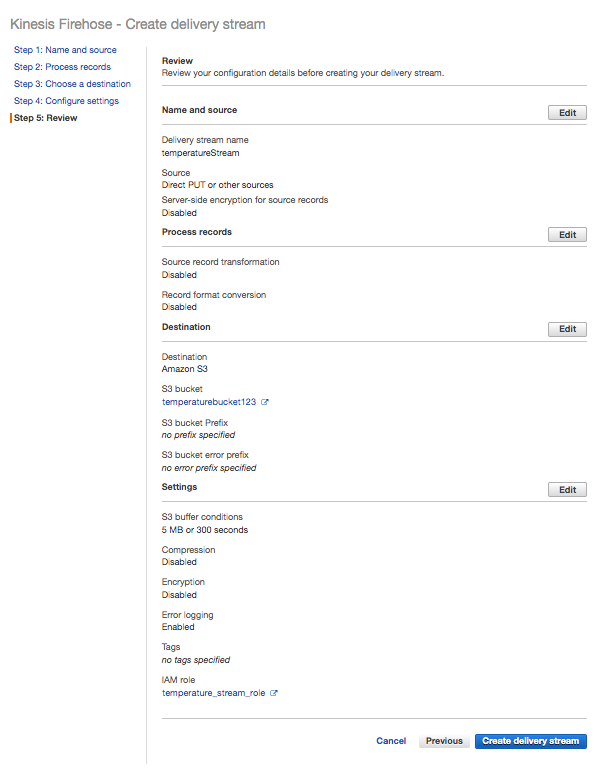
Review the delivery stream and click Create delivery stream to create the stream.
Select newly created role by clicking temperature_stream_role
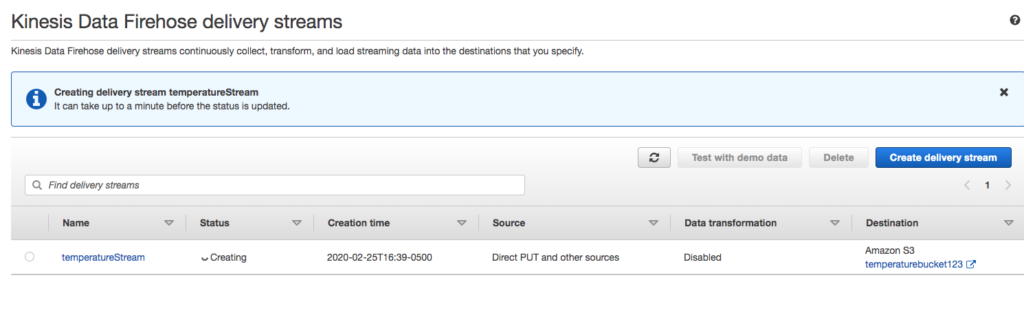
You should be taken to the list of streams and the Status of temperatureStream should be …Creating.
Delivery stream console after created.
After the stream’s status is Active, click on temperatureStream to be taken to the stream’s configuration page.
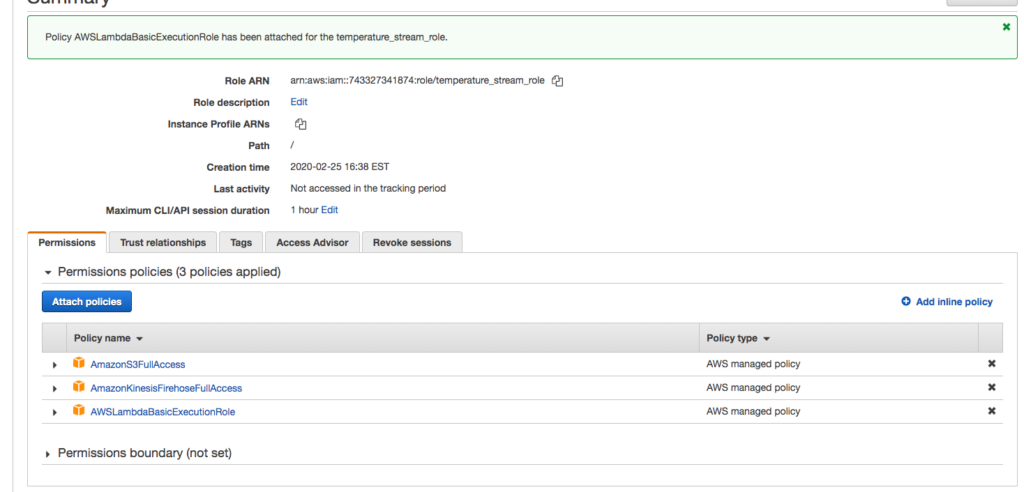
Click on the IAM role to return to the role settings in IAM.
Now, we are being very lazy…you would not do this in production, but delete the attached policy and attach the AWSLambdaFullAccess, AmazonS3FullAccess, and AmazonKinesisFirehoseFullAccess roles.
Here we are granting the role too much access. In reality, you should grant the minimal access needed in a production setting.
For simplicity (not for production use), delete policy and add the following three policies to role
Test Stream
For a simple stream such as what you just developed AWS provides an easy means of testing your data. Let’s test your data before continuing development.
If not on the stream configuration screen, select the stream on the Kinesis dashboard to navigate to the stream’s configuration screen.
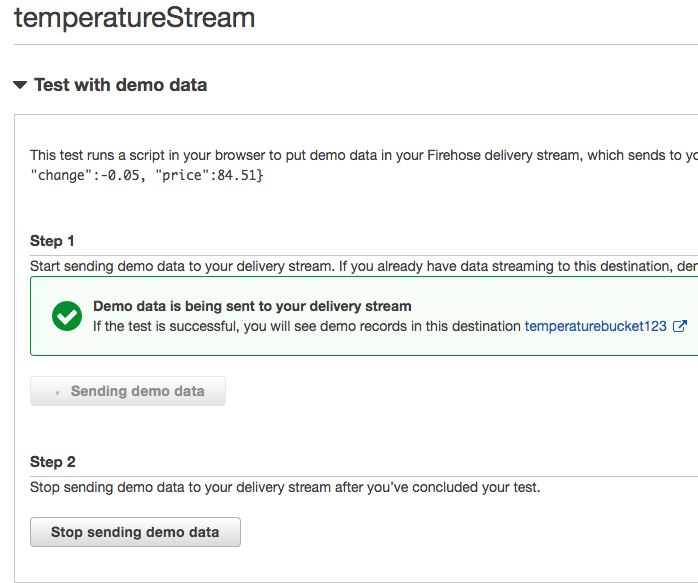
Expand the Test with demo data section.
Click the Start sending demo data button.
Wait about a minute and click the Stop sending demo data button.
Test data option on stream summary on AWS console
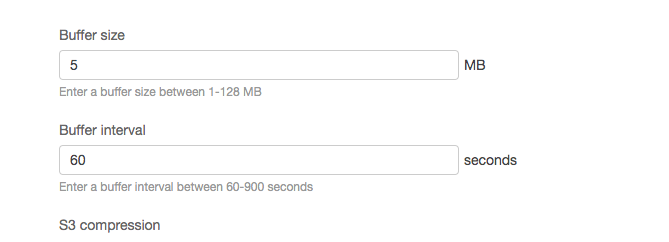
From the Amazon S3 destination section click on the bucket name to navigate to the S3 bucket. Be certain to wait five minutes to give the data time to stream to the S3 bucket.
If you tire of waiting five minutes, return to the stream’s configuration and change the buffer time to a smaller interval than 300 seconds.
The Buffer interval allows configuring the time frame for buffering data.S3 bucket link on stream summary on AWS console
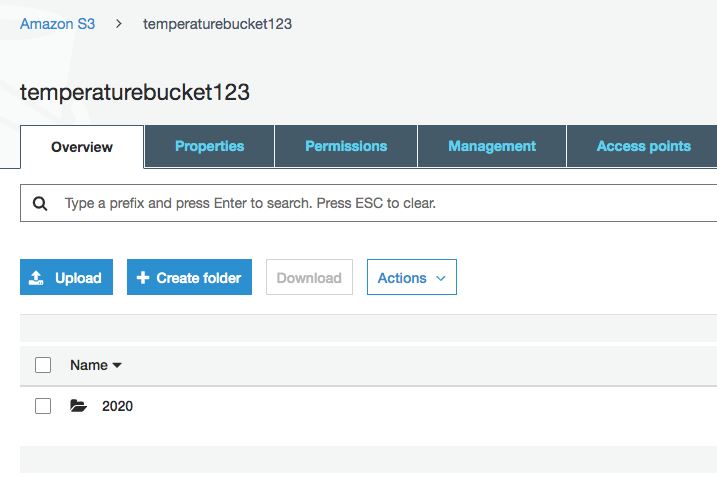
Click on the sub-folders until taken to the data file. If you do not see the top level folder, then wait five minutes and refresh the page. Remember, the data is buffered.
S3 Bucket top level folder after test data written
Open the file and you should see the test records written to the file.
Test data written to S3 bucket by Kinesis Firehose
Navigate to the top level folder and delete the test data. Be certain you delete the top level folder and not the bucket itself.
Delete test data by deleting top level folder
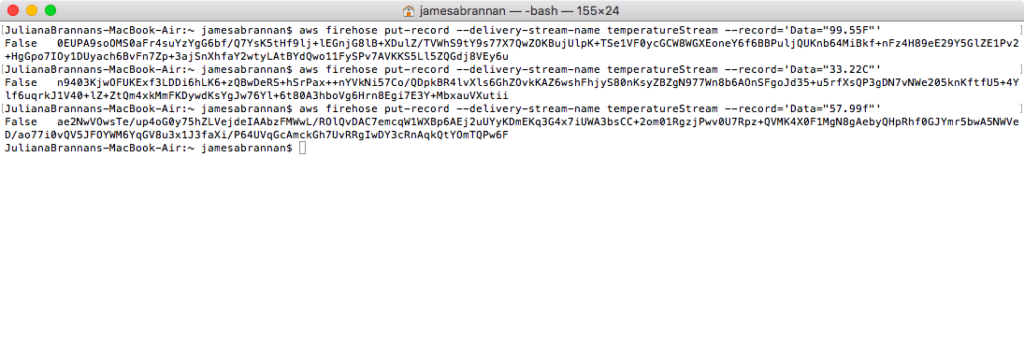
Open a command-line terminal on your computer and enter the following aws firehose put-record commands.
These commands worked with cli 1.18.11 on OS-X and they worked in Git-Bash on Windows 10. If you can get these working in Windows 10 command-line, please post in comments, as I wasted hours trying to send using cmd.
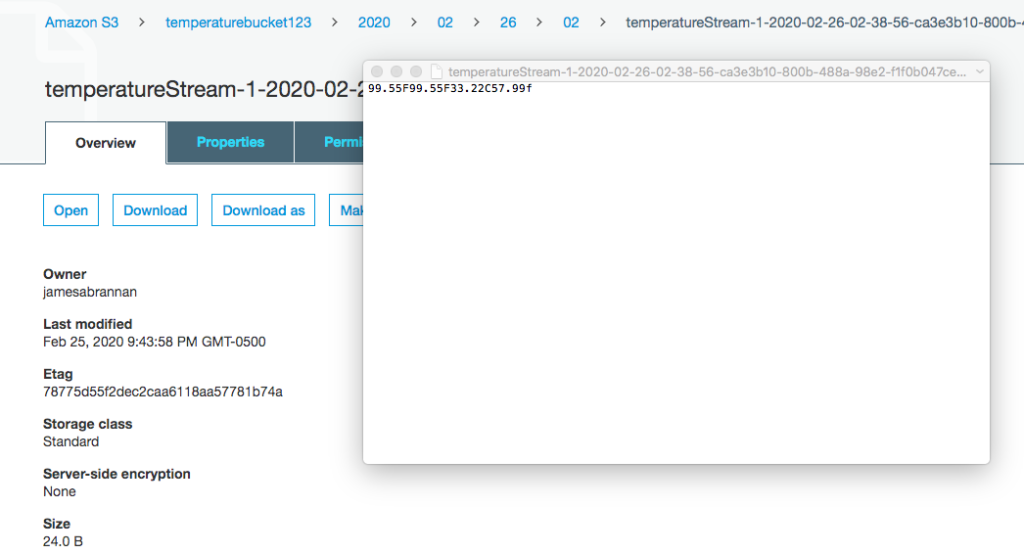
Return to the AWS Console and navigate to the S3 bucket and note the data was written to the bucket. Remember to allow the records time to process by waiting five minutes.
Rather than sending a simple string, modify the commands to send Json. Note that you escape the double-quotes.
See warning above regarding instability of cli accepted input.
Return to the AWS Console and you should see a file in the S3 bucket with data formatted as follows. Do not forget to give the record time to stream before checking the S3 bucket.
In the sample architecture note that the you need to convert the temperature data to kelvin. To accomplish this transformation you create a Lambda transform function for the Kinesis Firehose stream.
Lambda Function
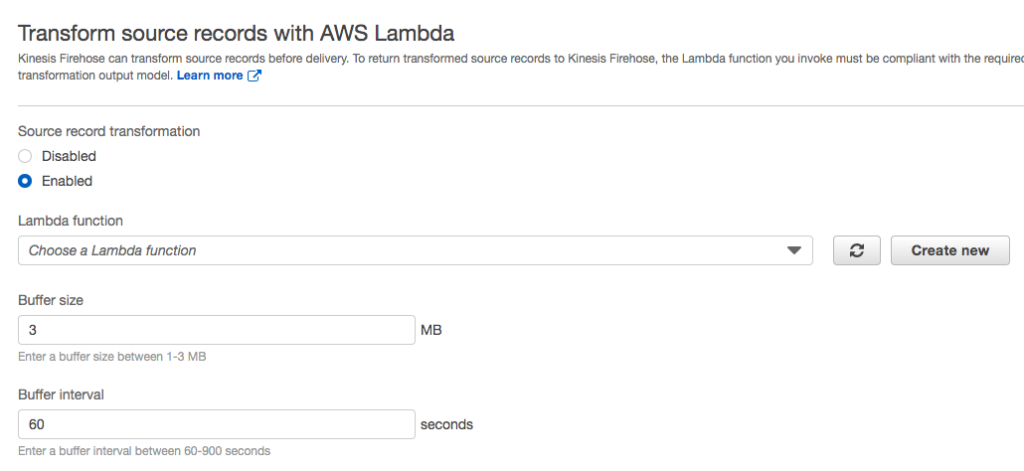
Recall when creating the stream you were provided the option of transforming the data.
Transform source records option
Although you left this feature disabled, the requirements dictate that you need to modify temperature readings from fahrenheit or celsius to kelvin. Kinesis firehose provides an easy way to transform data using a Lambda function. If you referred to any of the linked tutorials above then you know that you can create and edit the Lambda function directly in the AWS console.
Here you develop the Lambda function in a local development environment, debug the function, and then deploy the function to AWS. Here you develop a Python Lambda function locally and deploy it to AWS using a CloudFormation SAM template.
PyCharm
Hopefully you have installed PyCharm and the AWS Toolkit. If not, do so now. Refer to the prerequisites above for information on installing both.
Start PyCharm.
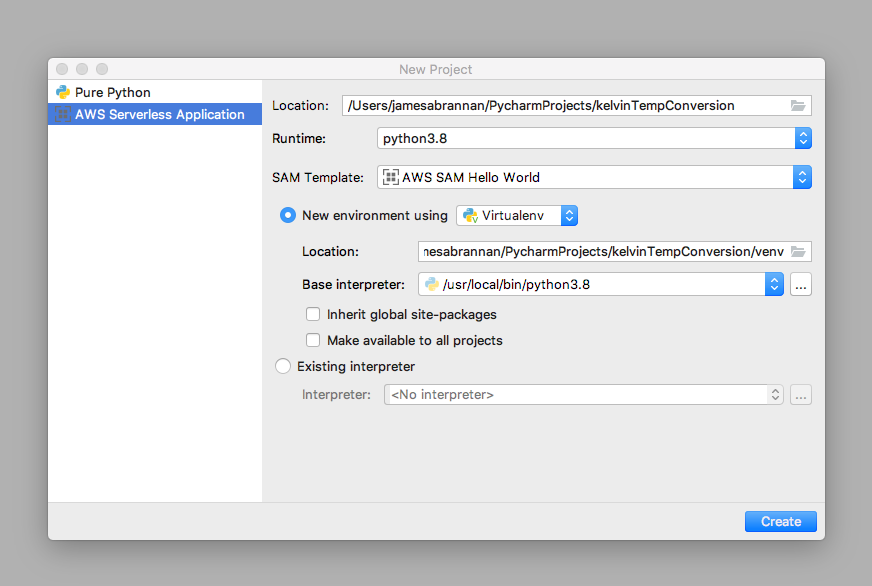
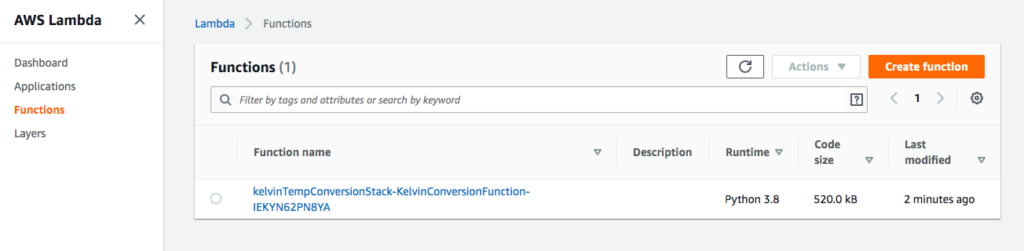
Create a new AWS Serverless Application named kelvinTempConversion.
Creating a new AWS SAM Project
Click No if the following Create Project popup appears.
Select No to this dialog to create a project with new resources
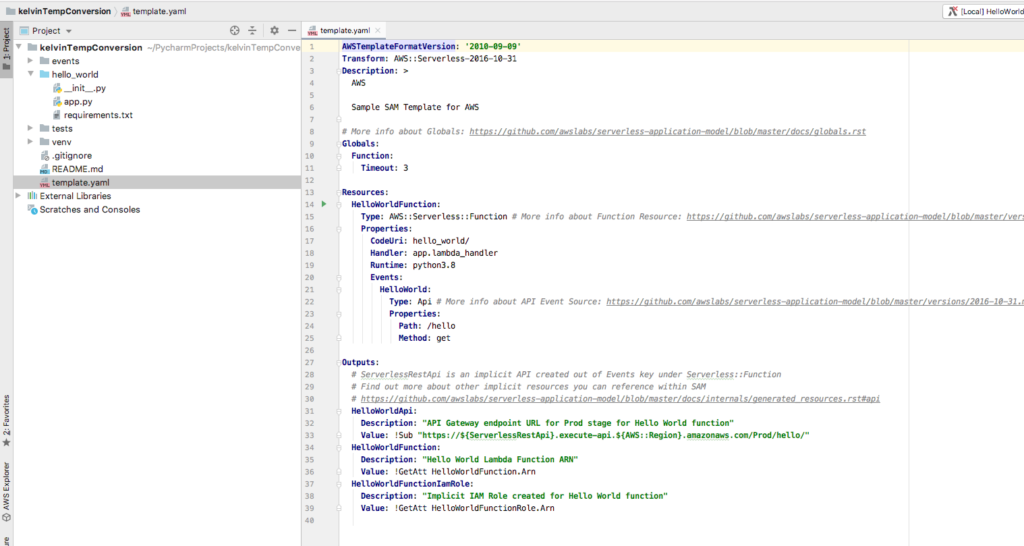
Open the template.yaml folder and notice the generated SAM template.
Modify the timeout from 3 to 60 seconds (Kinesis Firehose requires a 60 second timeout).
SAM template generated by PyCharm
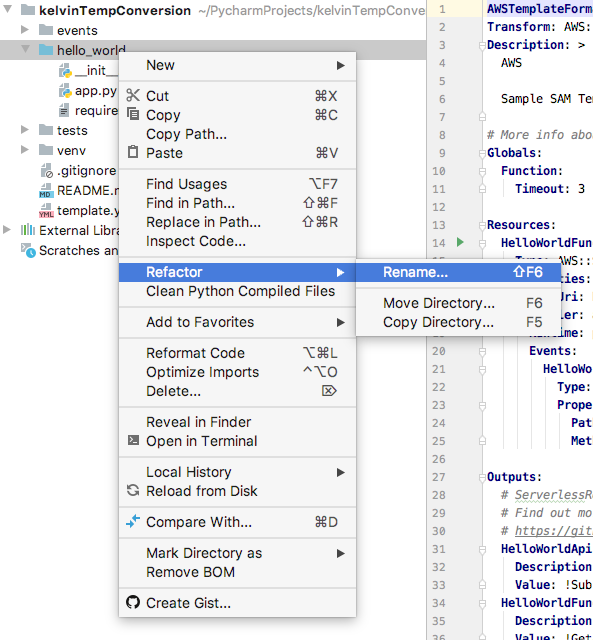
Right click the hello_world folder and select Refactor | Rename to rename the folder to kelvinConversion.
After reviewing the changes to be made, click the Do Refactor button.
Refactoring Hello World to kelvinConversion
Change all instances of HelloWorld with KelvinConversion in template.yaml.
Modify the function timeout (Globals:Function:Timeout:) to 60 seconds, the minimum for Kinesis Firehose.
Remove the Events section and the KelvinConversionApi section. These two sections are for building a public rest API. As we are developing a transformation function for our stream, neither is needed.
After modifying all instances of the hello world text, template.yaml should appear similar to the following.
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
AWS
Sample SAM Template for AWS
Globals:
Function:
Timeout: 60
Resources:
KelvinConversionFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: kelvinConversion/
Handler: app.lambda_handler
Runtime: python3.8
Outputs:
KelvinConversionFunction:
Description: "Kelvin Conversion Lambda Function ARN"
Value: !GetAtt KelvinConversionFunction.Arn
KelvinConversionFunctionIamRole:
Description: "Implicit IAM Role created for Kelvin Conversion function"
Value: !GetAtt KelvinConversionFunctionRole.Arn
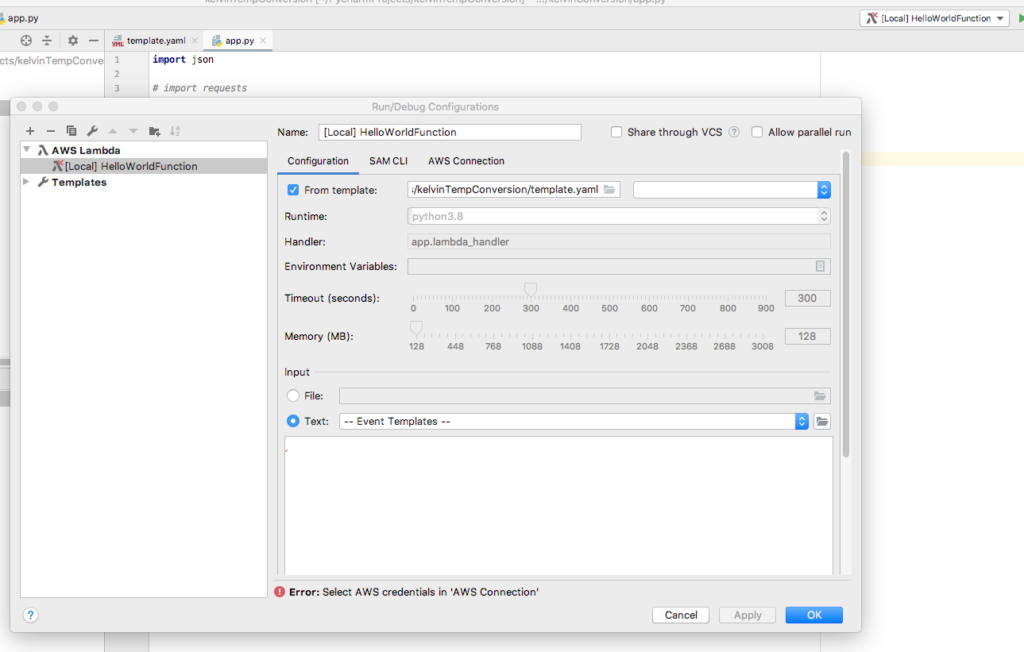
From the upper right drop down, select Edit Configurations.
Modify the template to reflect the new folder.
Click Ok.
Runtime configuration
Select the dropdown item and click the green arrow to run the application.
/usr/local/bin/sam local invoke --template /Users/jamesabrannan/PycharmProjects/kelvinTempConversion/.aws-sam/build/template.yaml --event "/private/var/folders/xr/j9kyhs2n3gqcc0n1mct4g3lr0000gp/T/[Local] KelvinConversionFunction-event.json" KelvinConversionFunction
Invoking app.lambda_handler (python3.8)
Fetching lambci/lambda:python3.8 Docker container image......
Mounting /Users/jamesabrannan/PycharmProjects/kelvinTempConversion/.aws-sam/build/KelvinConversionFunction as /var/task:ro,delegated inside runtime container
START RequestId: 1ffa20fa-486e-1827-e987-e92f16101778 Version: $LATEST
END RequestId: 1ffa20fa-486e-1827-e987-e92f16101778
REPORT RequestId: 1ffa20fa-486e-1827-e987-e92f16101778 Init Duration: 531.94 ms Duration: 14.75 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 24 MB
{"statusCode":200,"body":"{\"message\": \"hello world\"}"}
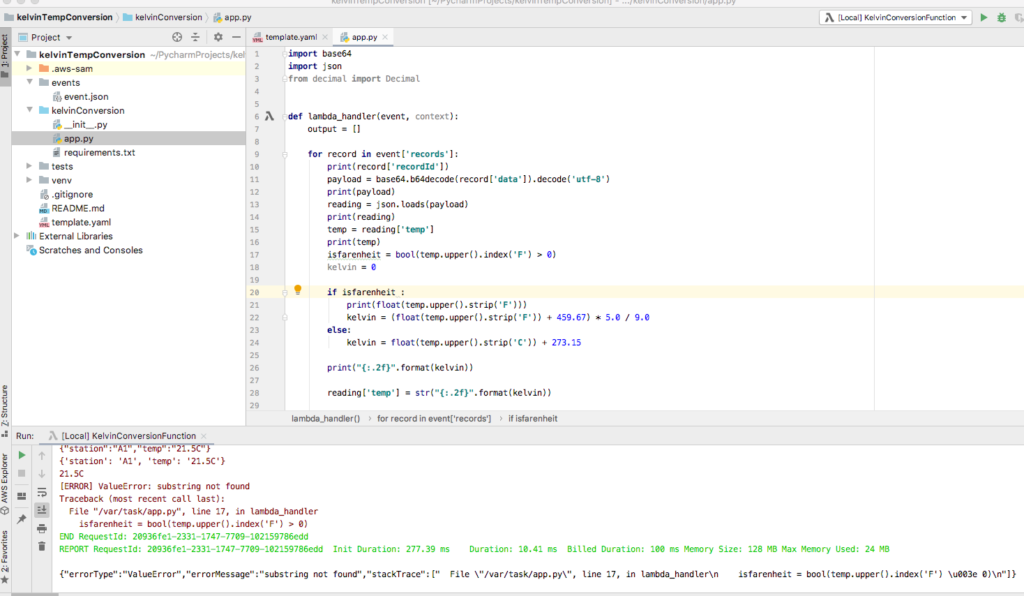
Now that you are assured the project is configured correctly and executes locally, open app.py and replace the sample code with the following. Note that the line using the index string function is in error. This error is by design and you will fix it later in the tutorial.
import base64
import json
from decimal import Decimal
def lambda_handler(event, context):
output = []
for record in event['records'] :
print(record['recordId'])
payload = base64.b64decode(record['data']).decode('utf-8')
print(payload)
reading = json.loads(payload)
print(reading)
temp = reading['temp']
print(temp)
# note: this is in error, if celcius this causes error
# this is fixed later in tutorial
isfarenheit = bool(temp.upper().index('F') > 0)
kelvin = 0
if isfarenheit:
print(float(temp.upper().strip('F')))
kelvin = (float(temp.upper().strip('F')) + 459.67) * 5.0 / 9.0
else:
kelvin = float(temp.upper().strip('C')) + 273.15
print("{:.2f}".format(kelvin))
reading['temp'] = str("{:.2f}".format(kelvin))
print(reading)
output_record = {
'recordId': record['recordId'],
'result': 'Ok',
'data': base64.b64encode(json.dumps(reading).encode('UTF-8'))
}
output.append(output_record)
print('Processed {} records.'.format(len(event['records'])))
return {'records': output}
Local Testing
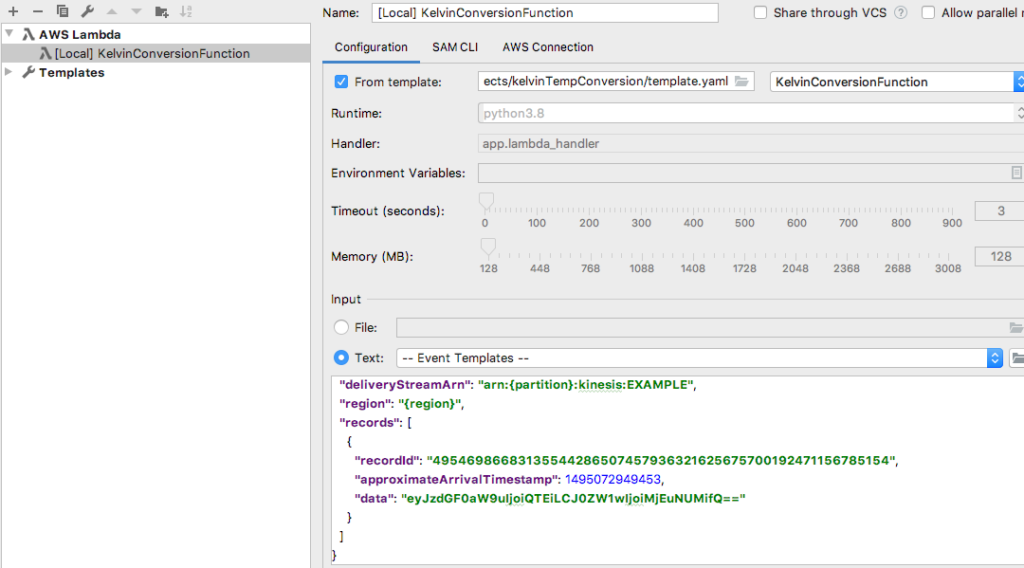
To test the record you need to use an event template. There are event types you can choose, depending upon how the Lambda function is to be used.
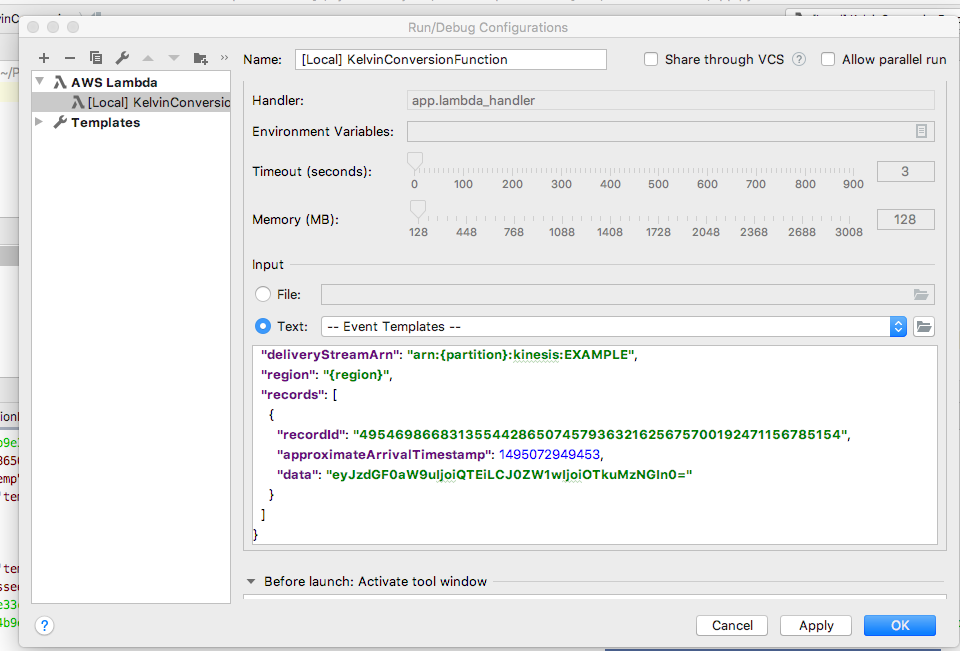
From Event Templates select Kinesis Firehose.
Select Kinesis Firehose template to generate test data
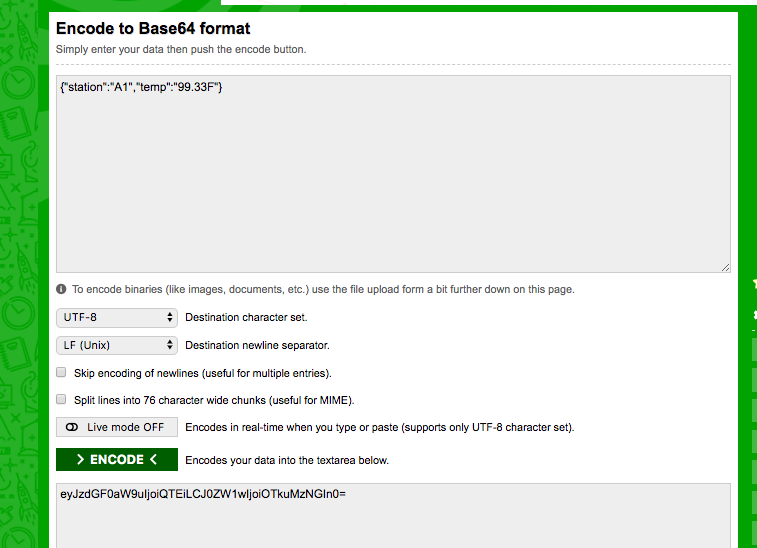
Create the sample record {“station”:”A1″,”temp”:”99.33F”} and base64 encode the record. A good site to encode and decode is the base64encode.org website.
Encoding a simple Json record to Base64
Replace the data string generated when you selected the Kinesis Firehose Event Template and replace it with the base64 encoded string.
Modify data value with the newly encoded value
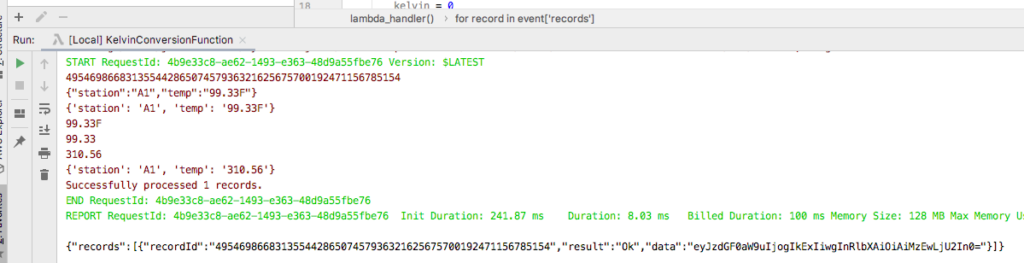
Run the application locally and you should see the returned record.
Console output from running application locally
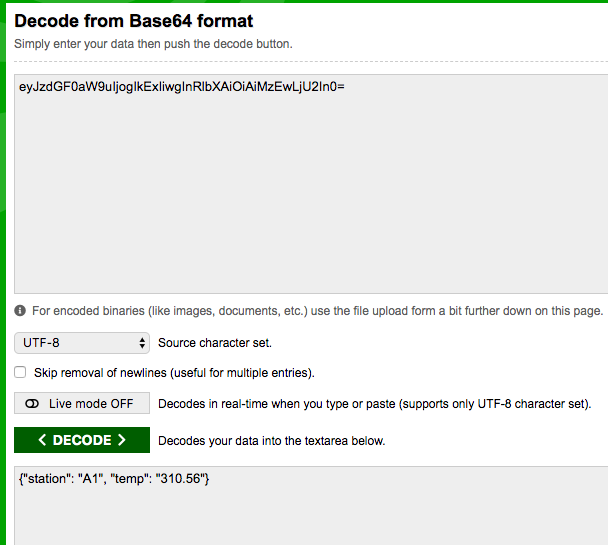
Copy the data string and decode the record from base64.
Decode result from Base64 to string
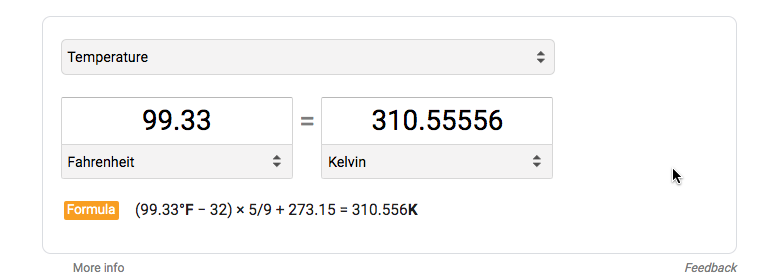
Validate the converted kelvin measurement is correct.
Note, you only tested fahrenheit. This is by design to illustrate debugging in the AWS Console. You fix this error later in this tutorial.
Deploying Serverless Application
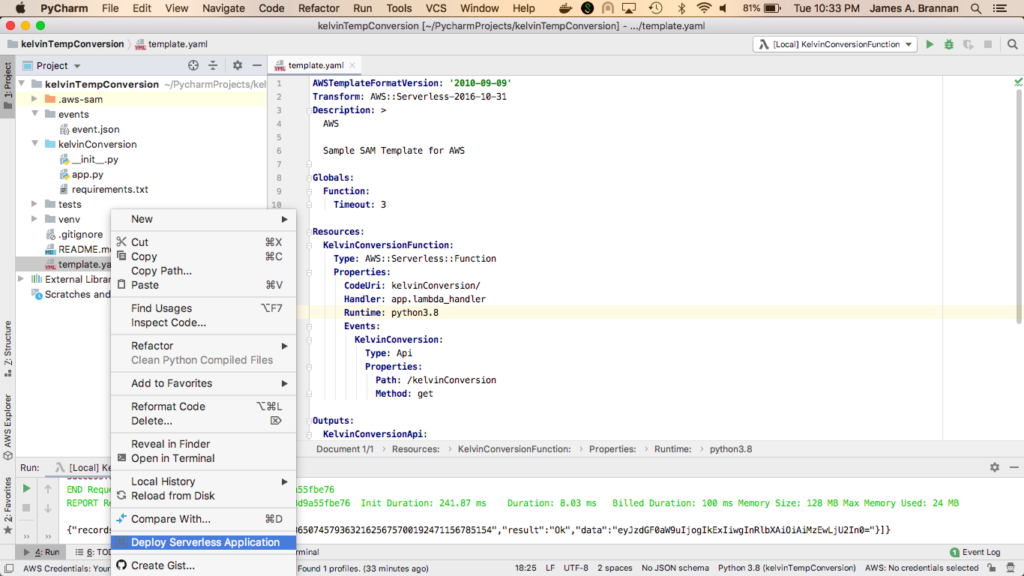
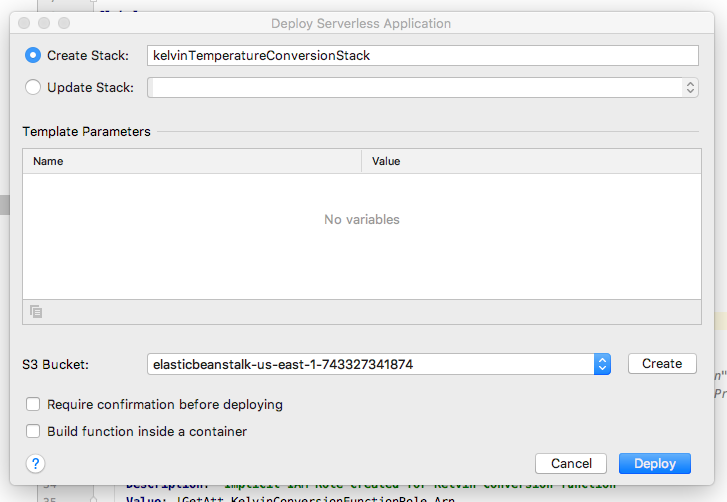
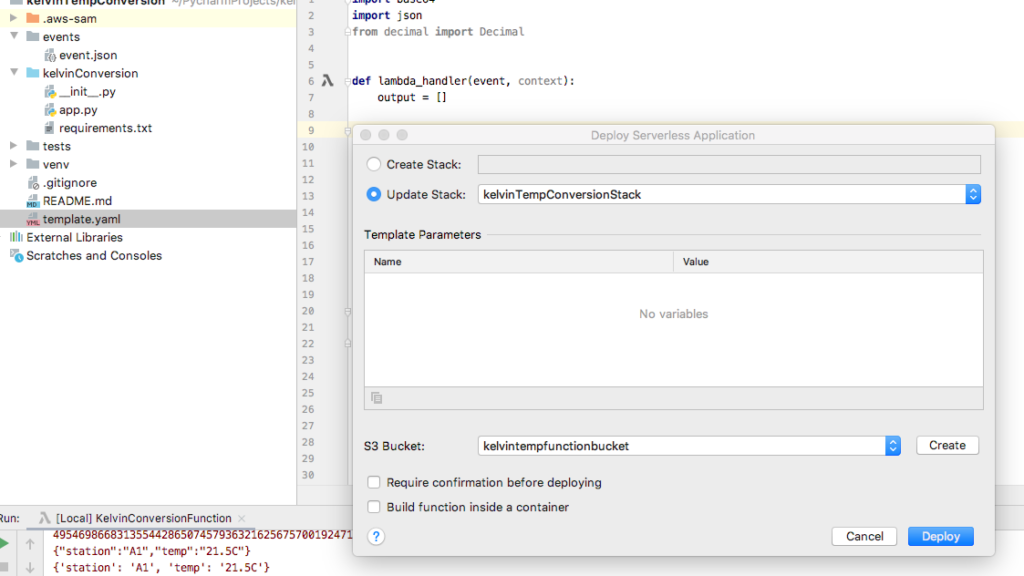
Right click on template.yaml and select Deploy Serverless Application from the popup menu.
Right click on template.yaml and select Deploy Serverless Application
Select Create Stack and name the stack kelvinTemperatureConversionStack.
Select or create an S3 Bucket.
Click Deploy.
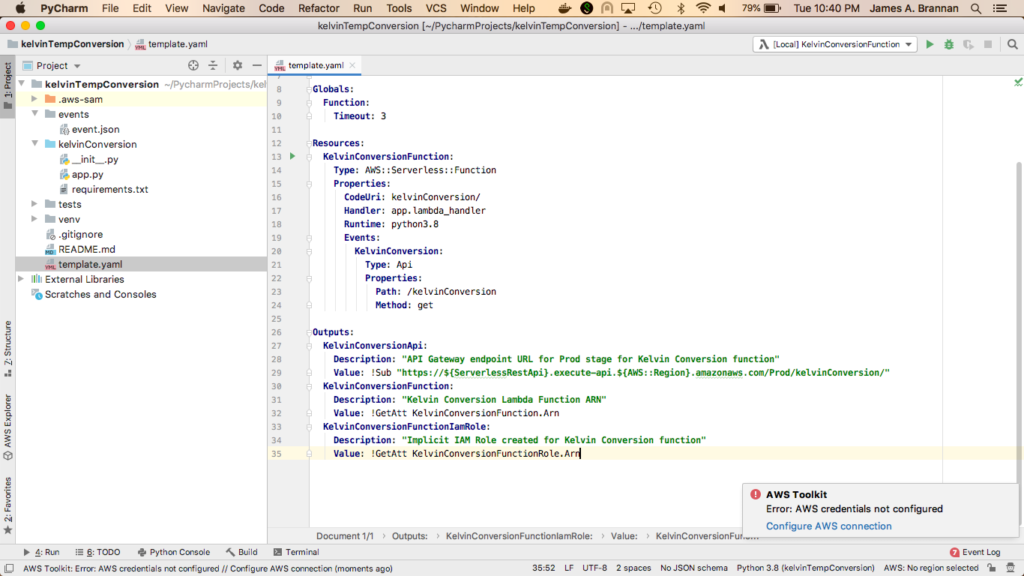
If you receive a credentials error, then you need to configure the AWS Toolkit correctly.
At the extreme lower right of the window, click the message telling you the issue.
Error if AWS Toolkit credentials are not configured correctlyProfile settings configured for AWS Toolkit
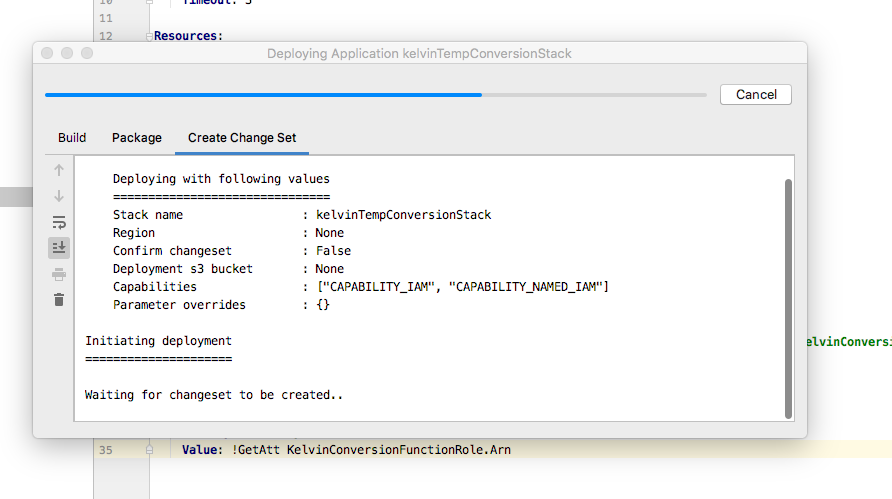
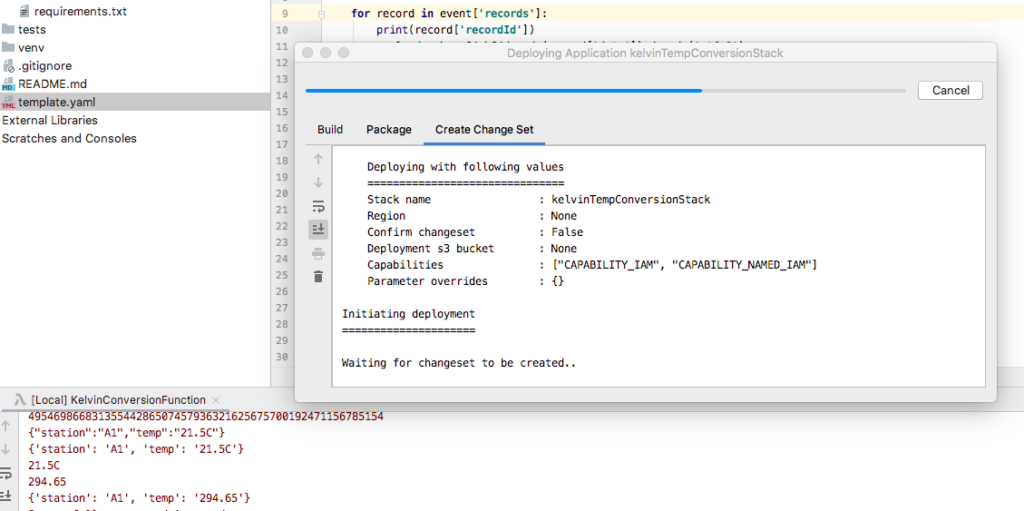
After fixing credentials (if applicable) then try again. A dialog window should appear informing you of the deployment progress.
Notice that the window is using CLI Sam commands to deploy the function to AWS.
Navigate to the temperatureStream configuration page.
Click Edit.
Enable source record transformation in the Transform source records with AWS Lambda section.
Select the Lambda function created and deployed by PyCharm.
Click Save.
Testing Kinesis Firehose Stream Using CLI
Open a command-line window and send several records to the stream. Be certain to escape the double-quotes, with the exception of the double quotes surrounding the data record.
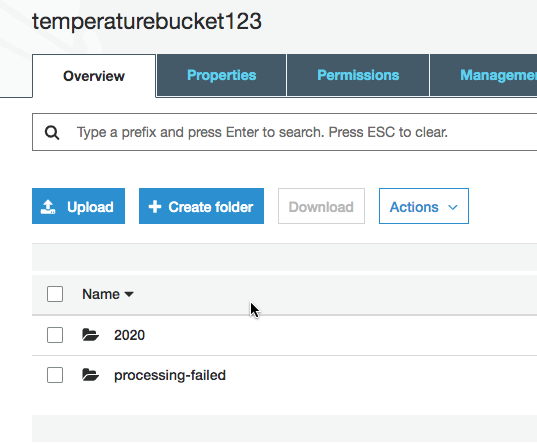
After waiting five minutes, navigate to the S3 bucket and you should see a new folder entitled processing-failed.
Processing-failed folder when Kinesis Firehose fails
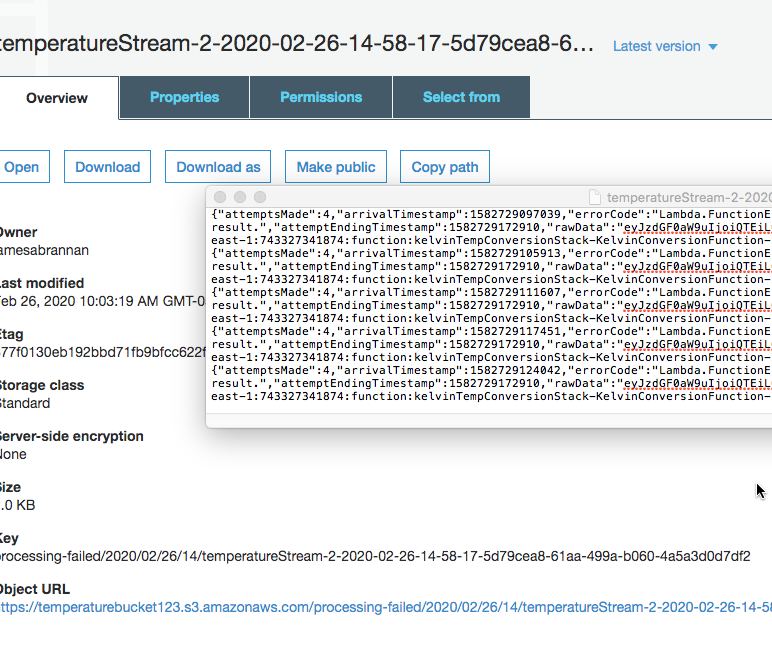
Navigate down the processing-failed folder hierarchy and open the failure records.
Errors written to S3 Bucket
The error messages are not very informative. But at least they tell you the Lambda function processing caused the error.
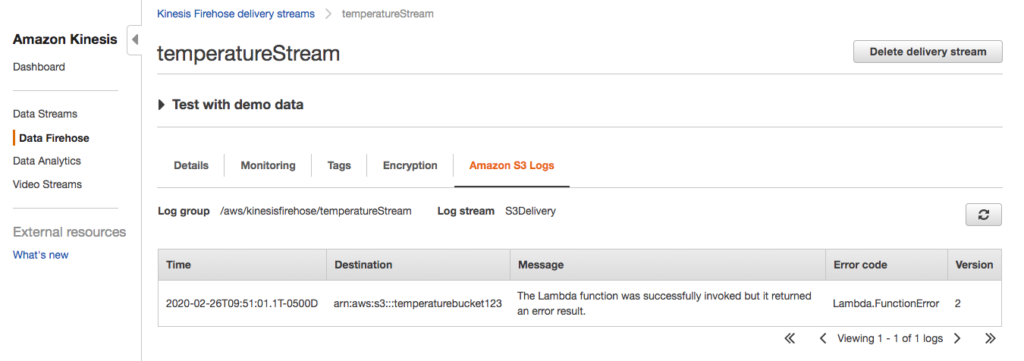
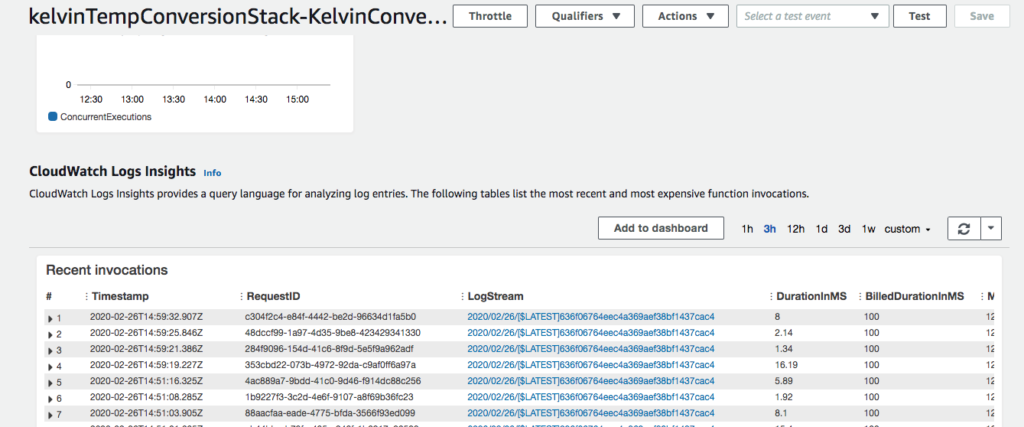
Navigate to the stream and select Amazon S3 Logs.
The log message is also not very informative.
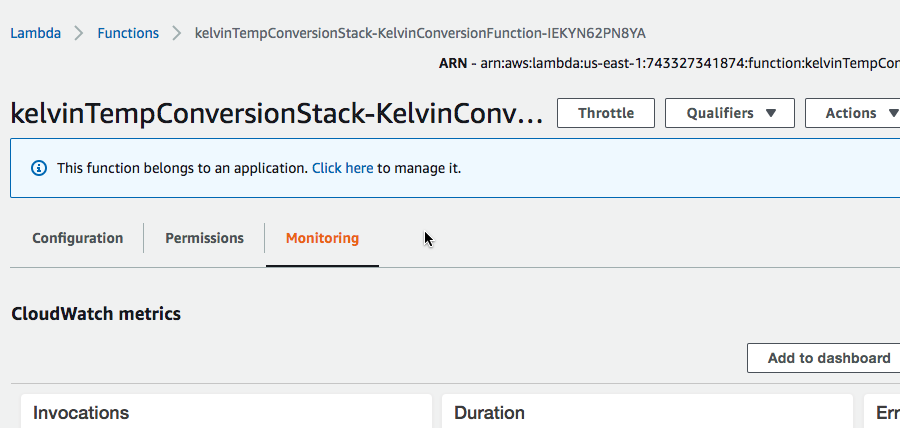
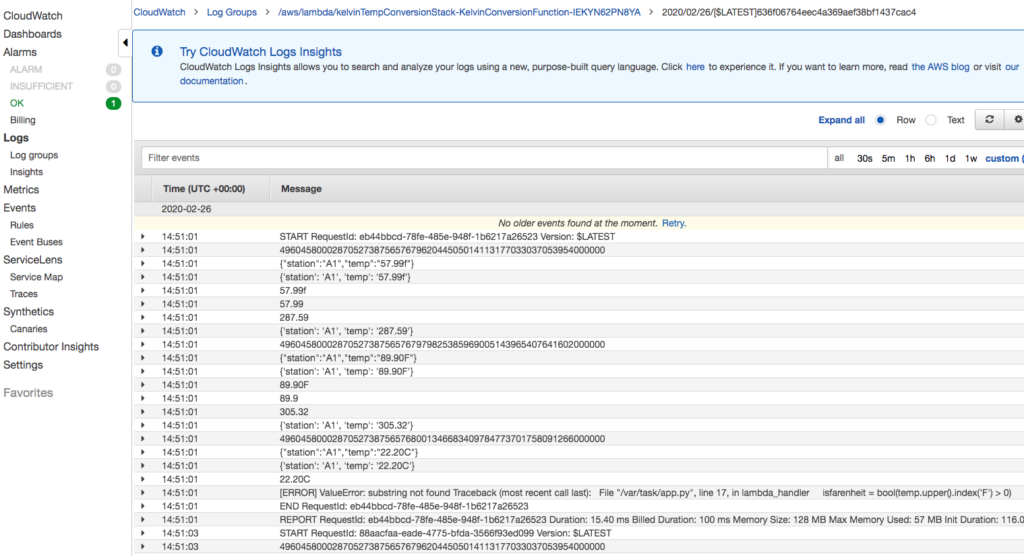
Navigate to the Lambda function details.
Select the LogStream from the most recent invocation of the Lambda function.
The detailed log records the exact cause of the error, the index function. Unlike some languages such as Java, the Python index function returns an error if the string is not found.
Fixing Error
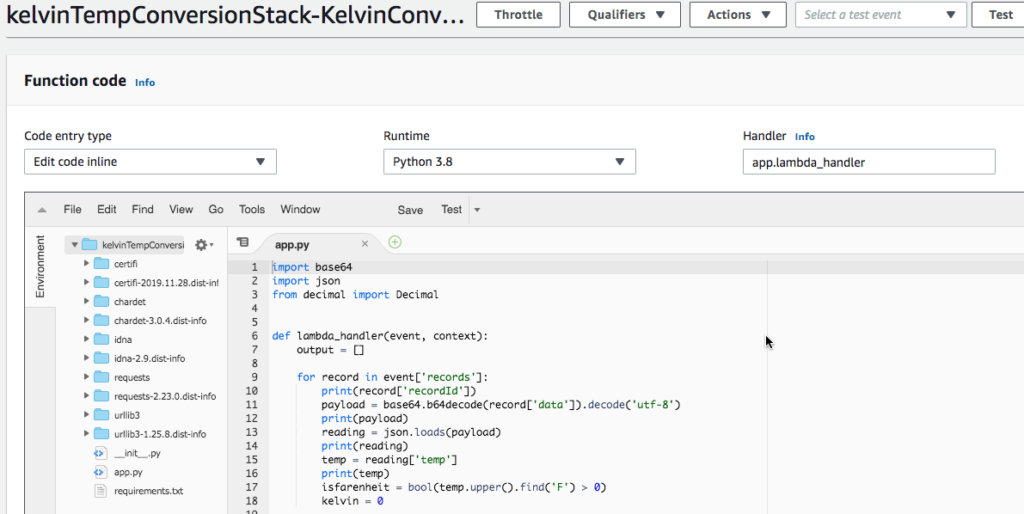
Return to the PyCharm project to fix the error and redeploy the Lambda function to AWS.
You might notice that you can edit a function directly in the AWS Console. DO NOT EDIT! Remember, you deployed this application using SAM in CloudFormation. The correct process is to fix the function and then redeploy it using SAM.
Python implementation in the AWS ConsoleData replaced with celcius value after encoding
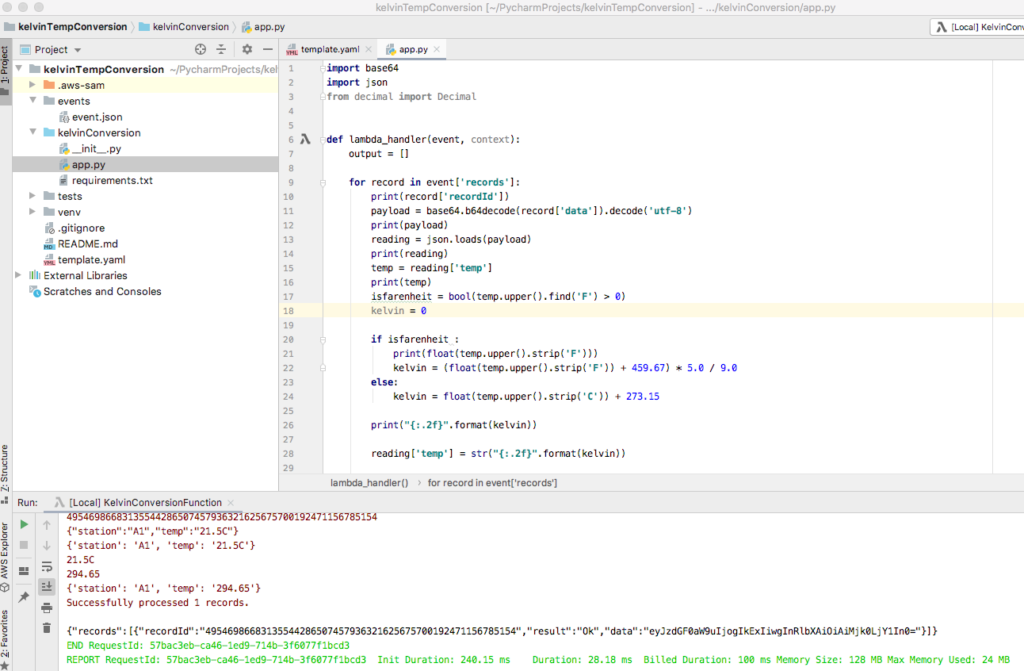
Modify the function to use find rather than the index function.
isfarenheit = bool(temp.upper().find('F') > 0)
Lambda function results in error due to the index function
Run the application locally using a celsius value. As before encode and decode and test the converted value.
Lambda function successfully ran with celcius data
After testing, right click on template.yaml and redeploy the serverless application.
Accept the Update Stack defaults.
Update Stack option in Deploy Serverless Application
After clicking Deploy a popup window informs you of the deployment progress.
Redeploying SAM application to AWS
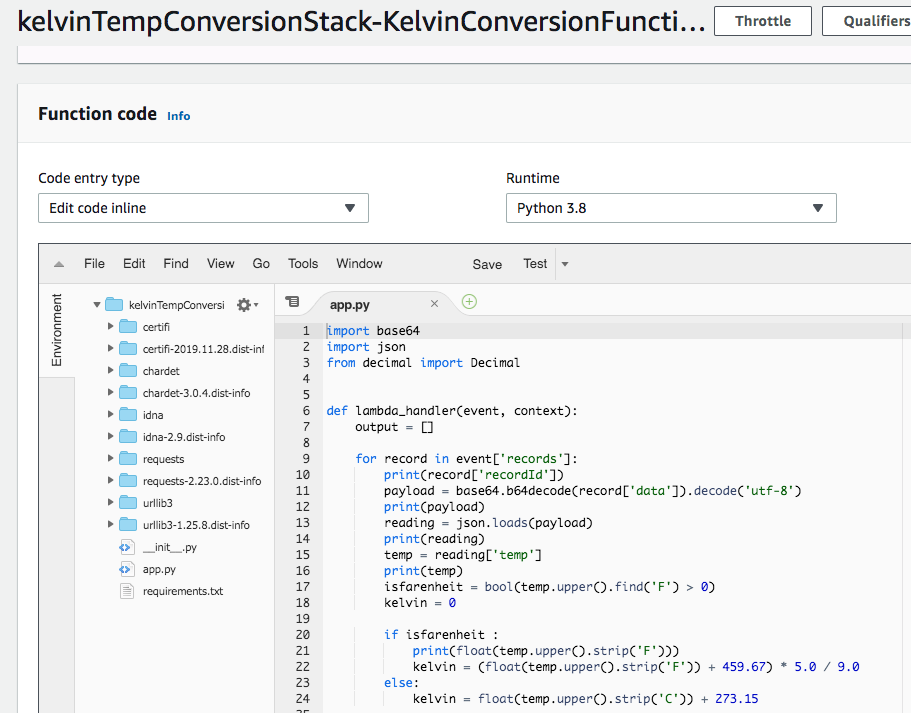
Navigate to the Lambda function details in the AWS Console and you should see the corrected source code.
Transformation function reflects changes made in PyCharm
From your command-line send several records to the stream.
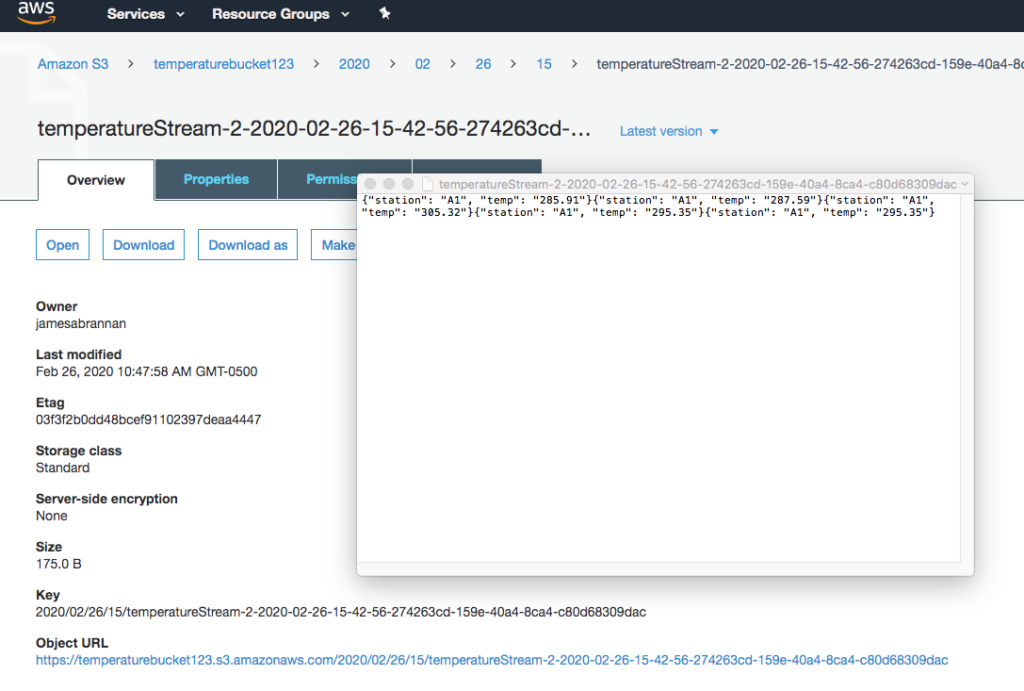
Navigate to the S3 bucket and you should see the transformed records.
Data streamed to S3 bucket
Summary
In this tutorial you created a Kinesis FIrehose stream and created a Lambda transformation function. You configured the stream manually and used SAM to deploy the Lambda function. An obvious next step would be to add the creation of the Kinesis Firehose and associated bucket to the Cloudformation template in your PysCharm project. This tutorial was sparse on explanation, so refer to the many linked resources to understand the technologies demonstrated here better. However, this tutorial was intended to provide a variation on the numerous more straightforward Kinesis Firehose tutorials available.